- The paper introduces a novel tree-based sampling strategy to provide fine-grained, step-level reward signals for LLM reasoning.
- It employs dynamic data pruning and tailored advantage computation to stabilize policy updates, boosting Pass@1 accuracy from 19.0% to 35.5%.
- The approach reduces average response length by 18.1%, indicating enhanced token efficiency and optimization in reinforcement learning tasks.
TreeRPO: Tree Relative Policy Optimization
In this essay, we explore the nuances of the "TreeRPO: Tree Relative Policy Optimization" approach, which introduces a novel method to enhance the reasoning capabilities of LLMs by leveraging tree-based sampling techniques. This paper presents innovative solutions to overcome the limitations of trajectory-level reward signaling in reinforcement learning with LLMs.
Introduction and Motivation
The emerging capabilities of LLMs in reasoning tasks have been significantly improved through Reinforcement Learning (RL) frameworks, notably those employing Reinforcement Learning with Verifiable Rewards (RLVR). A primary bottleneck has been the reliance on trajectory-level reward feedback, which provides limited direct guidance at intermediate reasoning steps. To bridge this gap, TreeRPO introduces a tree-based sampling strategy that facilitates step-level reward estimation without needing an explicit reward model, aiming to improve both the granularity and effectiveness of the learning signals.
Methodology
Tree Sampling
TreeRPO uses an N-ary tree structure initiated from a question. The process involves iterative sampling to expand N branches per node up to a maximum depth D, thereby maintaining tractability. Each branch corresponds to potential continuations of reasoning steps judged by a verifiable reward function.
The reward for each leaf node, representing a complete reasoning path, is calculated using this function. Intermediate nodes aggregate rewards from their children's paths, providing fine-grained reward estimations that guide the LLM's reasoning process (Figure 1).
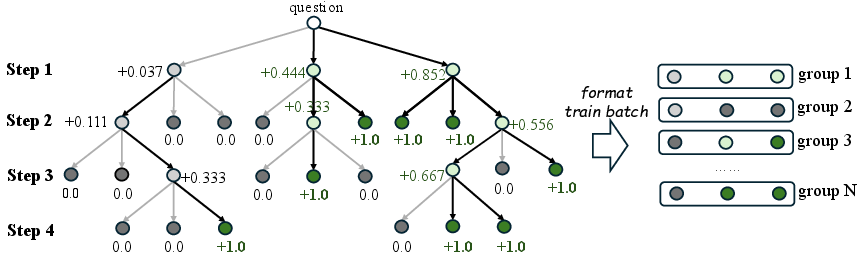
Figure 1: The sampling process of our TreeRPO. TreeRPO starts from the question, sampling N nodes at each step until generation is completed or the maximum depth limit D is reached.
Data Pruning and Advantage Computation
TreeRPO employs a dynamic pruning strategy akin to that used in DAPO, filtering out low-variance data samples to ensure all training samples are informative and contribute effectively to the learning signal. This is complemented by an advantage computation method tailored for continuous rewards, which stabilizes policy updates by accounting for the distribution characteristics of rewards.
The optimization objective of TreeRPO incorporates a clipped variant of GRPO with an additional KL-divergence penalty, balancing exploration and stability in policy updates. This clipping mechanism helps mitigate large policy deviations while facilitating refined learning through verifiable rewards.
Experimental Evaluation
The performance evaluation was conducted using Qwen-2.5-Math models on four mathematical benchmarks: MATH-500, OlympiadBench, MinervaMath, and AIME. The experiments underline TreeRPO's superior performance over the baseline GRPO, with significant improvements in Pass@1 accuracy—from 19.0% to 35.5%—and a reduction in response length by 18.1%, illustrating efficiency gains in token usage.
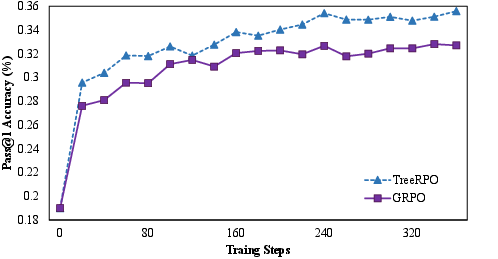
Figure 2: The average Pass@1 accuracy of TreeRPO and GRPO with Qwen-2.5-Math-1.5b on four mathematical benchmarks: MATH-500, OlympiadBench, Minerva, and AIME.
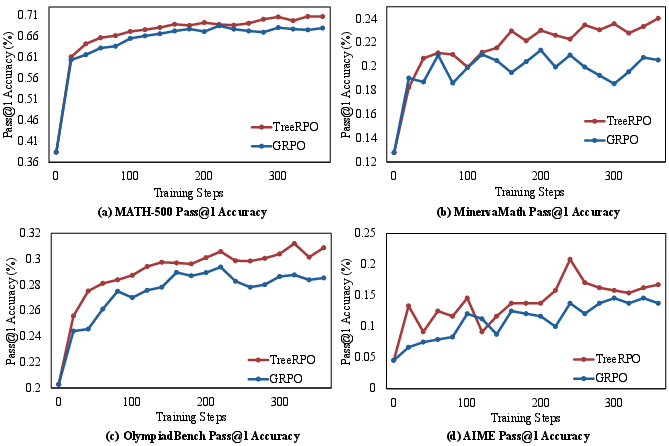
Figure 3: Performance comparison of our TreeRPO and GRPO on the four selected benchmarks: Math-500, MinervaMath, OlympiadBench, and AIME.
Conclusion
TreeRPO presents an effective reinforcement learning framework for enhancing the reasoning capabilities of LLMs by providing dense, fine-grained reward signals through tree sampling. This methodological advancement addresses a critical gap in trajectory-level reward systems, promoting more robust and efficient reasoning processes. Future work will explore scalability to larger model sizes and further optimizations in tree sampling efficiency, potentially broadening the application scope of TreeRPO in complex reasoning domains.