- The paper introduces UFO, a framework that transforms single-turn RL into effective multi-turn reasoning by leveraging minimal unary feedback.
- It employs Markov Decision Processes and Proximal Policy Optimization, integrating reward decay and repetition penalties to improve response diversity.
- Experiments demonstrate up to a 14% accuracy improvement and enhanced generalization across diverse tasks using multi-turn training.
A Simple "Try Again" Can Elicit Multi-Turn LLM Reasoning
Introduction
The paper "A Simple 'Try Again' Can Elicit Multi-Turn LLM Reasoning" addresses the challenge of enabling large reasoning models (LRMs) to engage in multi-turn reasoning and adapt their responses based on feedback. Single-turn reinforcement learning (RL) methods have demonstrated efficacy in enhancing the reasoning capabilities of LLMs but often falter in multi-turn interactive tasks due to repetitive and static response behaviors (Figure 1).
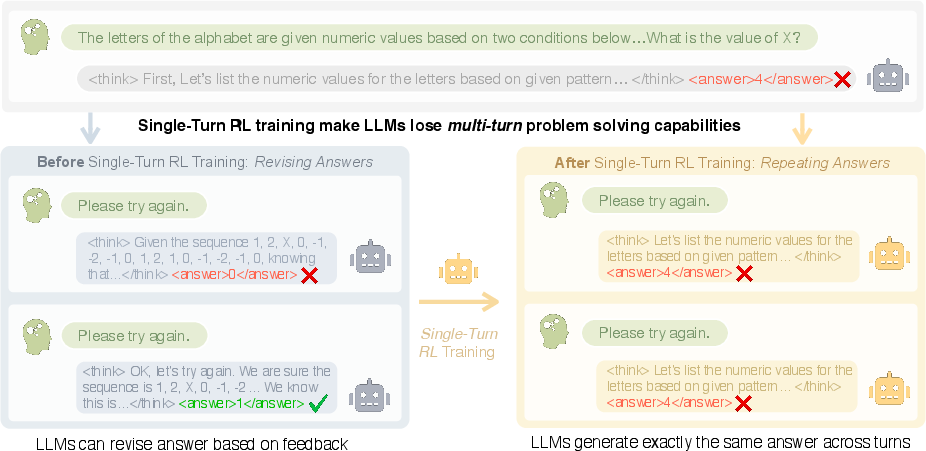
Figure 1: Single-turn RL causes LLMs to repeat the same answer across turns instead of revising based on feedback.
To address this gap, the authors introduce Unary Feedback as Observation (UFO), a framework that utilizes minimal feedback signals to train models for multi-turn reasoning tasks. UFO leverages simple unary feedback, such as generic prompts like "Let's try again," to encourage iterative exploration and adaptation within existing RL setups.
UAV Framework and Implementation
The UFO framework models multi-turn interactions as Markov Decision Processes (MDP), capturing the interaction history at each step and applying unary feedback to transform single-turn datasets into multi-turn sessions. At its core, UFO employs reinforcement learning to optimize multi-turn policies using Proximal Policy Optimization (PPO) while imposing reward decay and repetition penalties to enhance reasoning efficiency and diversity (Figure 2).
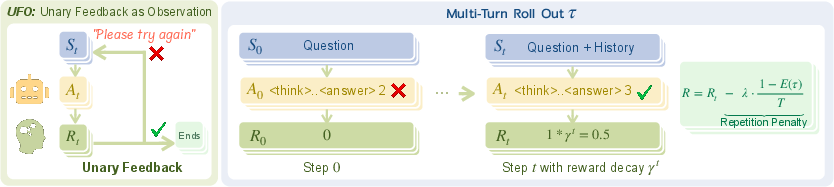
Figure 2: The UFO framework for multi-turn training. At each step t, the model observes the full interaction history and generates a response. Correct responses receive discounted rewards γt, while incorrect ones receive none.
To implement this framework:
- State Construction: Concatenate interaction history as a prompt, with the unary feedback acting as a response modifier.
- Policy Optimization: Adopt PPO, which uses a learned critic for fine-grained value assessments over multi-turn episodes.
- Reward Structuring: Define rewards that decay exponentially over turns, encouraging minimal turn count, and apply a penalty for repeated answers to foster diversity.
- Training: Engage in batch training using rollouts per prompt, with models evaluating their success based on structured multi-turn datasets.
Experimental Results
The experiments reveal that multi-turn RL via UFO effectively bolsters interactive reasoning, with agents achieving up to a 14% improvement in accuracy for multi-turn reasoning compared to single-turn RL. Additionally, multi-turn-trained models demonstrate robust generalization across diverse task domains and effectively adapt to distinct evaluation setups, including single-turn scenarios (Figure 3).
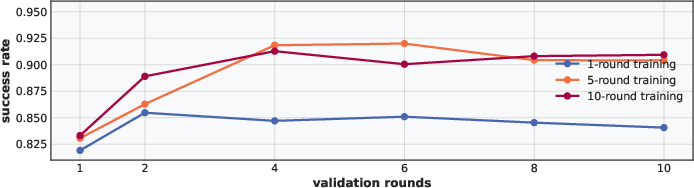
Figure 3: Validation performance (Succ@k) of models trained with different roll-out turns under varying inference-time turn budgets. Multi-turn training (5 or 10 turns) consistently yields higher success rates across all inference turn budgets.
Limitations and Future Directions
While the UFO framework advances multi-turn reasoning capabilities, it is primarily validated on smaller model scales, which may limit its scalability. Further exploration of larger models remains an avenue for future research. Moreover, enhancing reward structure to better align with complex reasoning processes could address drifts in reasoning integrity observable in multi-turn trajectories (Figure 4).
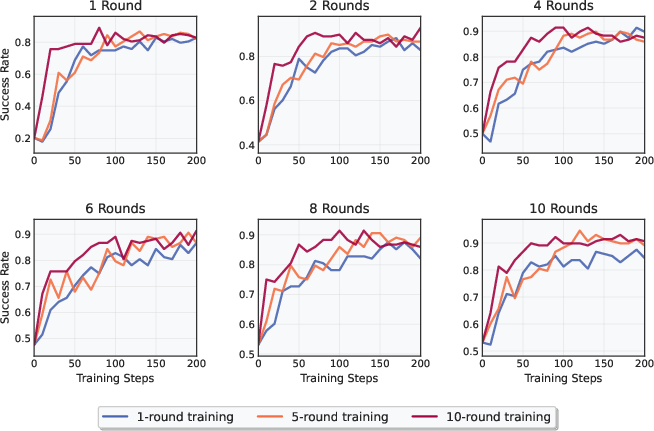
Figure 4: Performance across different evaluation round settings. Each subplot shows the success rate evaluated at r rounds.
Conclusions
The paper presents a significant step toward bridging the gap between single-turn and multi-turn reasoning capabilities in LRMs. By leveraging minimal feedback within familiar RL paradigms, UFO offers a practical and lightweight approach to improve iterative reasoning without requiring extensive structural changes. This work points to a promising direction for practical applications where limited feedback can still yield deep and adaptive model reasoning.