- The paper proposes MTPO, a multi-turn RLHF algorithm integrating Q-functions with mirror descent to achieve Nash equilibrium.
- The methodology is validated through both education dialogue and car dealer environments, demonstrating enhanced performance over single-turn approaches.
- The results highlight improved strategic learning in multi-turn settings, enabling AI systems to handle complex, prolonged interactions.
Multi-turn Reinforcement Learning from Preference Human Feedback
Overview
The paper "Multi-turn Reinforcement Learning from Preference Human Feedback" explores advancements in Reinforcement Learning from Human Feedback (RLHF) using preference feedback from extended interactions, specifically multi-turn dialogues. This approach aims to improve the capabilities of LLMs in tasks requiring long-term planning, adaptive strategies, and dynamic interaction.
Key Concepts and Methodology
Multi-turn Preference-based RL
The paper introduces a structured approach to multi-turn preference-based RL, extending RLHF beyond single-turn interactions. It formalizes the multi-turn setting using Contextual Markov Decision Processes (CMDPs) where the agent receives preference feedback comparing final states after multiple exchanges, rather than immediate single-turn feedback.
In this framework, the authors present the Multi-turn Preference Optimization (MTPO) algorithm, leveraging Mirror Descent (MD) methods and self-play principles. MTPO converges to Nash equilibrium in the preference-based setting, effectively capturing the cumulative impact of actions over complete interactions (Figure 1).
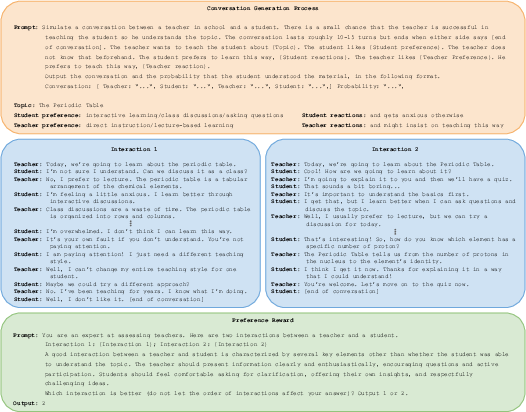
Figure 1: Education Dialogue data generation process. Top: prompt used to generate conversation with Gemini. Middle: conversations sampled from the the interaction between the teacher and student models. Bottom: prompt used for the preference oracle.
Algorithms and Theoretical Validation
The MTPO algorithm operates by integrating Q-functions into the preference optimization process. This is supported by a theoretical framework establishing convergence to Nash equilibrium using MD. Additionally, a variant, MTPO-τ, employs a geometric mixture policy for enhanced performance, particularly in scenarios requiring stochastic explorations.
The paper provides rigorous mathematical analysis and proofs regarding algorithmic convergence and preference-based Q-functions, essential for understanding interaction dynamics in extended dialogues.
Experimental Design
Education Dialogue Environment
To test MTPO in a preference-centric scenario, the authors developed the Education Dialogue environment. Here, a teacher agent guides a student in learning diverse topics, evaluated solely through preference feedback, without explicit reward signals. This environment showcases the superiority of multi-turn approaches over traditional single-turn RLHF methods, which are limited by their consideration of isolated, immediate feedback.
Car Dealer Environment
In a reward-based validation, the Car Dealer environment from LMRL-Gym is utilized, where agents aim to maximize sales prices. MTPO shows competitive performance compared to direct reward optimization, indicating the robustness of preference-based learning even in typical RL scenarios.
Implications and Future Directions
The methodologies proposed in the paper suggest significant enhancements in RLHF by enabling more strategic and adaptive learning systems. These developments are pertinent for applications demanding complex, multi-step interactions, such as advanced chatbots, negotiation systems, and educational tools.
Moving forward, the research sets a precedent for refining RL algorithms to better handle multi-turn interactions by directly leveraging preference feedback, thereby expanding the capabilities of AI systems in real-world contexts.
Conclusion
The paper contributes to the RLHF domain by shifting focus towards the multi-turn paradigm, demonstrating the efficacy of preference-based learning for complex, prolonged interactions. This approach not only enriches the learning dynamics but also broadens the scope of AI applicability in nuanced scenarios requiring deep conversational and strategic competencies.