Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training
Abstract: General AI Agents are increasingly recognized as foundational frameworks for the next generation of artificial intelligence, enabling complex reasoning, web interaction, coding, and autonomous research capabilities. However, current agent systems are either closed-source or heavily reliant on a variety of paid APIs and proprietary tools, limiting accessibility and reproducibility for the research community. In this work, we present \textbf{Cognitive Kernel-Pro}, a fully open-source and (to the maximum extent) free multi-module agent framework designed to democratize the development and evaluation of advanced AI agents. Within Cognitive Kernel-Pro, we systematically investigate the curation of high-quality training data for Agent Foundation Models, focusing on the construction of queries, trajectories, and verifiable answers across four key domains: web, file, code, and general reasoning. Furthermore, we explore novel strategies for agent test-time reflection and voting to enhance agent robustness and performance. We evaluate Cognitive Kernel-Pro on GAIA, achieving state-of-the-art results among open-source and free agents. Notably, our 8B-parameter open-source model surpasses previous leading systems such as WebDancer and WebSailor, establishing a new performance standard for accessible, high-capability AI agents. Code is available at https://github.com/Tencent/CognitiveKernel-Pro
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
- Accessibility tree: A structured representation of a web page's UI elements used to enable algorithmic navigation and interaction. "which provides both the accessibility tree and the screenshot of the current web page."
- Ablation study: An experimental analysis that removes or varies components to measure their impact on performance. "We present an ablation study of the effect of the reflection module in Table~\ref{tab:reflection_ablation}."
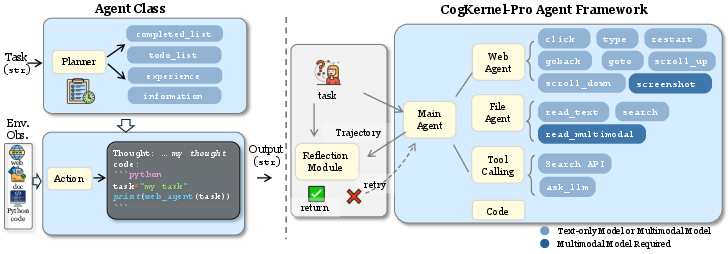
- Action space: The set of allowable actions an agent can take; here, generated and executed as Python code. "Cognitive Kernel-Pro leverages Python code as its action space, harnessing the full reasoning and code-generation potential of modern LLMs."
- Action–observation format: A structured log pairing each action with its resulting observation to facilitate evaluation. "presenting it in an action-observation format (i.e., ``Action 1: ..., Observation 1: ...; Action 2: ..., Observation 2: ...'')."
- Agent Foundation Models: Base models specialized for agent behaviors (planning, tool use, reasoning) that the framework trains and uses. "training data for Agent Foundation Models, focusing on the construction of queries, trajectories, and verifiable answers across four key domains: web, file, code, and general reasoning."
- Agentic abilities: Capabilities enabling an AI to act autonomously (e.g., planning, tool use, multi-step execution). "or lack of multimodal or general agentic abilities~\citep{webdancer, websailor}."
- Code Agent: An agent that generates and runs code as its primary means of acting or reasoning. "While we do not have a standalone Code Agent in the system, every sub-agent is a code agent since the output action of every agent is essentially python code."
- Deep Research Agents: Autonomous systems designed for multi-step research tasks like web navigation, data analysis, and synthesis. "The rapid advancement of Deep Research Agents~\citep{manus, deep_research} has transformed the landscape of automated knowledge discovery and problem-solving."
- DOM tree parsing: Processing the Document Object Model to understand and manipulate web page structure programmatically. "we enhance the web browsing tool with DOM tree parsing to display web structure, enable element clicking, and text input."
- Exact match: An evaluation metric where a predicted answer must exactly match the reference answer. "Exact match is used as the evaluation method here."
- Ensemble-based multi-run strategies: Running multiple independent attempts and aggregating results to improve robustness. "we propose a pipeline that integrates retry mechanisms and ensemble-based multi-run strategies."
- File Agent: A specialized agent for reading, searching, and interpreting files like PDFs, spreadsheets, and images. "File Agent. The file agent is designed to process a variety of file types, such as PDF files (.pdf), spreadsheet files (.xlsx, .xls, .csv), and image files ('.png', '.jpg', '.gif', etc.)."
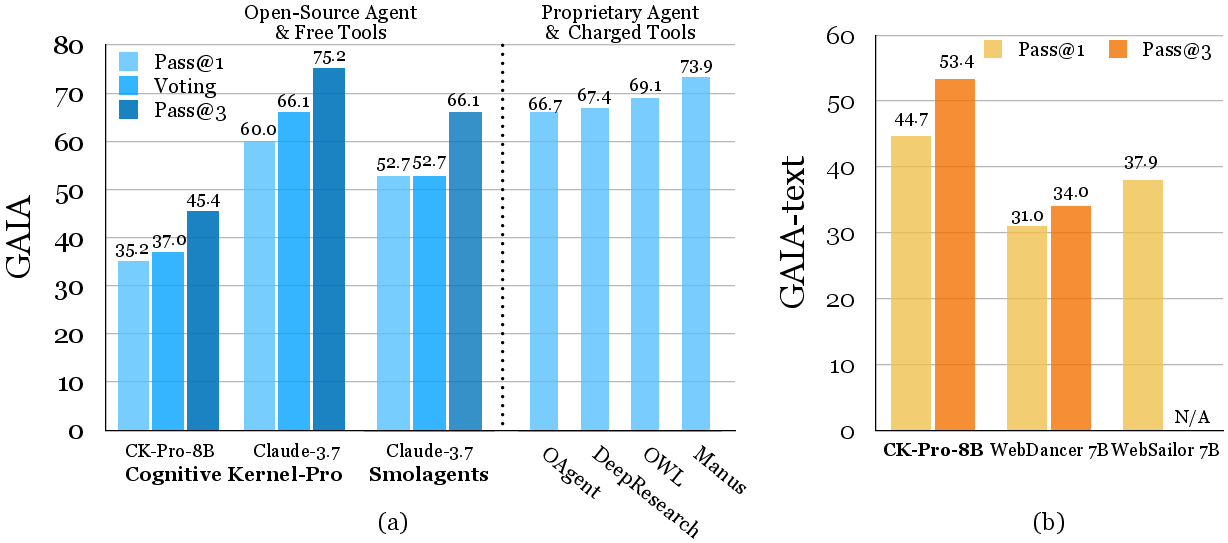
- GAIA: A benchmark for evaluating multi-step reasoning and agent capabilities across diverse tasks. "We evaluate Cognitive Kernel-Pro on GAIA, achieving state-of-the-art results among open-source and free agents."
- Hint-based rejection sampling: A data collection method that uses intermediate hints and discards low-quality samples to improve training trajectories. "we incorporate intermediate process hints and employ hint-based rejection sampling, which significantly improves the quality and relevance of the collected data."
- Inference-time optimization: Techniques applied during inference (not training) to improve outcomes, such as reflection and voting. "We introduce two inference-time optimization processesâreflection and votingâdesigned to enable the agent to evaluate and refine its own trajectories, contributing to a more robust and accurate performance of the framework."
- Information aggregation: Combining data from multiple sources or formats to derive an answer. "constraining that the answer must be derived through information aggregation operations, as shown in Figure~\ref{fig:info-agg}."
- Multimodal LLM: A model that processes and reasons over multiple modalities (e.g., text and images). "``screenshot'' is a special function to turn on screenshot mode to call a multimodal LLM to process the image."
- Multi-hop information-seeking QA pairs: Questions requiring several retrieval steps across sources to answer. "create diverse and complex multi-hop information-seeking QA pairs grounded in web pages."
- Pass@1: The accuracy when only the top attempt is considered correct if it matches the reference. "(b) Performance on the text-only GAIA subset (=103), demonstrating our 8B model's superiority over 7B models in the WebDancer/WebSailor family (2\% higher Pass@1, over 10\% higher Pass@3)."
- Pass@3: The accuracy when any of the top three attempts is correct. "(b) Performance on the text-only GAIA subset (=103), demonstrating our 8B model's superiority over 7B models in the WebDancer/WebSailor family (2\% higher Pass@1, over 10\% higher Pass@3)."
- PersonaHub: A resource of synthetic personas used to generate diverse queries for training. "PersonaHub~\citep{ge2024scaling} provides an effective strategy to synthesize large-scale diverse queries for various LLM tasks like math, logic reasoning, instruction following, etc."
- Planner: The component that maintains task state and orchestrates sub-tasks and actions. "The planner maintains a state dictionary containing
completed\_list',todo_list',experience', andinformation' (\S \ref{sec:ck_arch})." - Reflection module: A critic-like process where the agent reviews its actions and outcomes to detect errors and retry. "a standalone reflection module is included to assess task completion; if the task is incomplete, the agent will retry (\S \ref{sec:reflection})."
- Rejection sampling: A sampling technique that filters out low-quality or incorrect trajectories based on criteria or similarity. "Subsequently, we apply rejection sampling using similarity-based matching, facilitated by the
cot\_qaof LangChain, with gpt-4.1 as the backbone model." - Retry mechanisms: Automated re-attempts of tasks upon failure or uncertain outcomes to improve reliability. "we propose a pipeline that integrates retry mechanisms and ensemble-based multi-run strategies."
- Self-instruct: A data synthesis approach where an LLM generates tasks or topics using provided seed instructions. "Using a self-instruct based method, we use an LLM to generate broad and interesting topics with verifiable sources of truth."
- State dictionary: A structured store of an agent’s current progress, plans, and gathered knowledge. "The planner maintains a state dictionary containing
completed\_list',todo_list',experience', andinformation' (\S \ref{sec:ck_arch})." - Sub-agent: A specialized agent delegated specific sub-tasks (e.g., web or file operations) by the main agent. "The sub-agents are equipped with specialized skills that are essential for a general-purpose task-solving agent system."
- Trajectory sampling: Generating and collecting sequences of agent actions and observations for training or evaluation. "during trajectory sampling for training, providing these intermediate results as hints to the task-solving agent significantly improves the success rate for training data collection."
- Verifiable agent query-answer pairs: Training data where answers can be checked against sources to ensure correctness. "includes the construction of verifiable agent query-answer pairs, ensuring high-quality training data."
- Vision-LLMs (VLMs): Models that jointly process visual and textual information for reasoning or understanding. "These agents, powered by LLMs and vision-LLMs (VLMs), excel in tasks such as coding, web navigation, file processing, and complex reasoning."
- Voting: An inference-time procedure that compares multiple trajectories to select the best final answer. "The voting process enables the agent to aggregate multiple trajectories, enhancing its decision-making and increasing the likelihood of achieving optimal outcomes."
- Web Agent: A specialized agent capable of browsing, interacting with, and extracting information from live web pages. "Web Agent. The web agent is equipped with a browser and can navigate live web pages to collect relevant and time-sensitive information."
Collections
Sign up for free to add this paper to one or more collections.