- The paper presents a novel benchmark (HLSMAC) that integrates classical Chinese stratagems into StarCraft II scenarios to test high-level strategic decision-making.
- It introduces multidimensional metrics—TPF, TDA, AUF, CTD, and USR—to rigorously evaluate agent behavior and ensure compliance with strategic objectives.
- Experimental results reveal that most current MARL and LLM-based agents struggle with high-level strategies, underscoring the need for advanced approaches.
HLSMAC: A StarCraft Multi-Agent Benchmark for High-Level Strategic Decision-Making
Motivation and Benchmark Design
The HLSMAC benchmark addresses a critical gap in multi-agent reinforcement learning (MARL) evaluation: the lack of environments that require agents to demonstrate high-level strategic reasoning rather than mere micromanagement. Existing benchmarks such as SMAC focus on fine-grained unit control, which fails to capture the complexity of human-like strategic planning. HLSMAC systematically integrates twelve scenarios inspired by the classical Chinese Thirty-Six Stratagems, each designed to challenge agents with tasks involving tactical maneuvering, timing coordination, deception, and other strategic elements.
The benchmark construction pipeline (Figure 1) involves a rigorous process: selection and analysis of stratagems, scenario design leveraging human gameplay and StarCraft II data, and iterative refinement to ensure each scenario embodies the core strategic principle. The resulting maps feature expanded spatial dimensions (≥80×80 grids), richer terrain, diverse unit and structure abilities, dynamic opponent policies, and redefined victory conditions that emphasize strategic objectives over exhaustive confrontation.
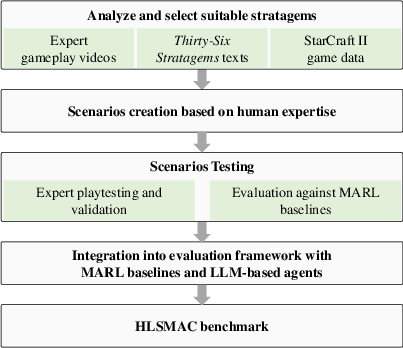
Figure 1: Benchmark Construction Pipeline illustrating scenario design from stratagem analysis to map implementation.
Scenario Structure and Strategic Elements
Each HLSMAC scenario is a direct instantiation of a stratagem, with explicit mechanisms that force agents to adopt strategic solutions. For example, in the "Besiege Wei to Rescue Zhao" (wwjz) scenario, agents must abandon direct defense and instead attack the enemy base, triggering a retreat and enabling piecemeal defeat of the enemy (Figure 2). Similarly, "Lure Your Enemy onto the Roof, Then Take Away the Ladder" (swct) requires agents to use transport and force field abilities to trap and destroy retreating enemies (Figure 3). The scenarios are calibrated such that naive or direct approaches are guaranteed to fail, enforcing the necessity of strategic reasoning.

Figure 2: Scenario progression in wwjz, sdjx, and swct, showing initial setup, victory via stratagem, and defeat via direct combat.

Figure 3: swct scenario, demonstrating the use of transport and force field abilities to execute the stratagem.
The diversity of scenarios spans indirect attacks (adcc), deception (wzsy), feints (sdjx), and ability-based tactics (jdsr, gmzz), each with tailored unit compositions, terrain, and triggers. This design ensures that success requires not only coordination but also the integration of domain knowledge and abstract reasoning.
Integration with MARL and LLM Frameworks
HLSMAC is implemented to be compatible with both PyMARL and LLM-PySC2, enabling evaluation of both traditional MARL algorithms and LLM-based agents. The environment uses a modular factory pattern, with scenario-specific classes inheriting from a shared base, supporting dynamic unit spawning and complex termination logic. The action space is extended to include strategic abilities (e.g., Burrow, Hallucination, Load/Unload), and the reward structure is decomposed to facilitate detailed analysis.
For LLM agents, the framework supports hierarchical agent configurations and prompt-based task decomposition, allowing for the evaluation of agents' ability to interpret and execute high-level strategic instructions.
Evaluation Metrics
Recognizing the inadequacy of win rate as a sole metric, HLSMAC introduces scenario-specific metrics:
- Target Proximity Frequency (TPF): Measures how often allied units approach critical targets.
- Target Directional Alignment (TDA): Quantifies the alignment of unit movement with optimal strategic paths.
- Ability Utilization Frequency (AUF): Tracks the purposeful use of special abilities.
- Critical Target Damage (CTD): Assesses damage dealt to key objectives.
- Unit Survival Rate (USR): Evaluates preservation of allied forces.
These metrics are computed from replay data and are scenario-dependent, providing multidimensional insight into agent behavior.
Experimental Results
Comprehensive evaluation of 21 MARL algorithms and GPT-3.5-based LLM agents reveals several key findings:
- Difficulty: Nearly 80% of algorithm-scenario combinations achieve zero win rates, indicating the substantial challenge posed by HLSMAC (Figure 4).
- Strategic Failure: High win rates do not guarantee strategic compliance; agents often succeed via unintended behaviors, as revealed by replay analysis (Figures 9–11).
- Metric Correlation: R2 analysis shows that CTD, TPF, and USR correlate strongly with win rate, while AUF is effective for distinguishing human-like purposeful ability usage from aimless execution (Figure 5).
- LLM Limitations: LLM agents fail to solve scenarios, demonstrating limited tactical awareness and inability to generate effective action sequences.
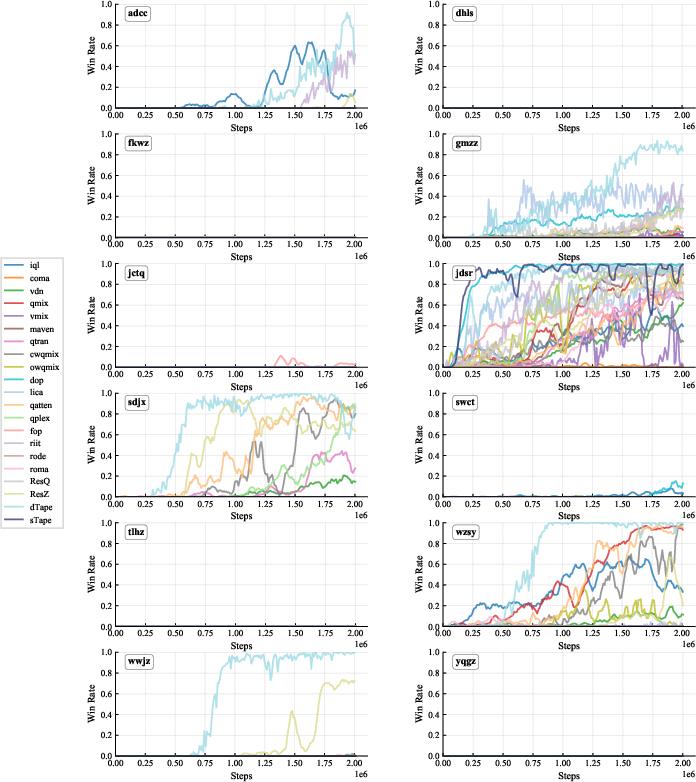
Figure 4: Win Rates Across 21 MARL Baselines on the 12 HLSMAC Scenarios; most algorithms fail on the majority of scenarios.
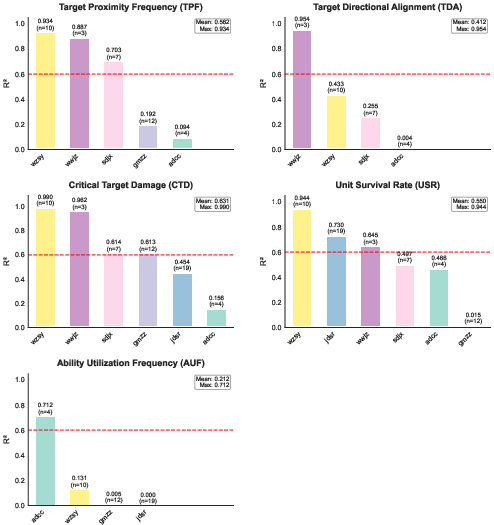
Figure 5: R2 Analysis of Win Rate Correlation with Evaluation Metrics; CTD, TPF, and USR are most predictive.

Figure 6: Replay snapshots of dTAPE on sdjx and RESZ on wwjz, illustrating stratagem-aligned execution.

Figure 7: Replay snapshots of RIIT on adcc and DOP on swct, showing non-stratagem behaviors and repetitive ability usage.

Figure 8: Replay snapshots of CWQMIX on fkwz and VMIX on gmzz, highlighting aimless ability execution versus human strategic use.
Implications and Future Directions
HLSMAC establishes a new standard for evaluating multi-agent strategic intelligence, shifting the focus from micromanagement to high-level reasoning. The benchmark exposes the limitations of current MARL and LLM-based methods, which struggle to generalize, interpret, and execute complex strategies. The multidimensional metrics provide a richer framework for analysis, enabling the identification of behaviors aligned with human strategic principles.
Practically, HLSMAC can drive the development of algorithms that incorporate explicit reasoning, hierarchical planning, and knowledge integration. Theoretically, it motivates research into the representation and learning of abstract strategies, the transfer of human knowledge, and the design of environments that require compositional and causal reasoning.
Future work should explore automated scenario generation, curriculum learning for strategic skills, and the development of specialized architectures capable of leveraging the structure and semantics of strategic tasks. The integration of LLMs with symbolic reasoning and planning modules may be necessary to overcome current limitations.
Conclusion
HLSMAC provides a rigorous, strategically rich benchmark for multi-agent learning, systematically integrating classical human strategic wisdom into StarCraft II scenarios. The environment, metrics, and experimental results collectively demonstrate the inadequacy of current methods and the necessity for new approaches to strategic decision-making. HLSMAC is positioned to catalyze advances in both algorithmic development and the theoretical understanding of multi-agent strategic intelligence.