- The paper introduces a novel Physics-Informed Neural Operator (PINO) that integrates training data with PDE constraints to learn solution operators of parametric PDEs.
- The methodology combines a neural operator architecture with dual loss functions, enabling zero-shot super-resolution and enhanced accuracy in multi-scale systems like Kolmogorov flows.
- Experimental results demonstrate significant improvements over traditional models, with lower error rates in applications such as Burgers' equation, Darcy flow, and inverse problem scenarios.
The paper "Physics-Informed Neural Operator for Learning Partial Differential Equations" proposes a novel approach called the Physics-Informed Neural Operator (PINO), which integrates training data and physics constraints to learn solution operators of parametric partial differential equations (PDEs). This approach aims to improve upon existing methods by providing a hybrid model that combines the strengths of data-driven models with the robustness of physics-based constraints.
Introduction
Machine learning has become an essential tool for solving PDEs by learning operators that map function spaces. Prior work in this area includes neural operators like the Fourier Neural Operator (FNO), which demonstrates high speed and accuracy in operator approximation but struggles with scenarios where no training data is available or generalizes poorly to unseen resolutions. PINO addresses these limitations by incorporating physics-based constraints at a higher resolution than the training data, facilitating zero-shot super-resolution and overcoming challenges in multi-scale dynamic systems such as Kolmogorov flows.
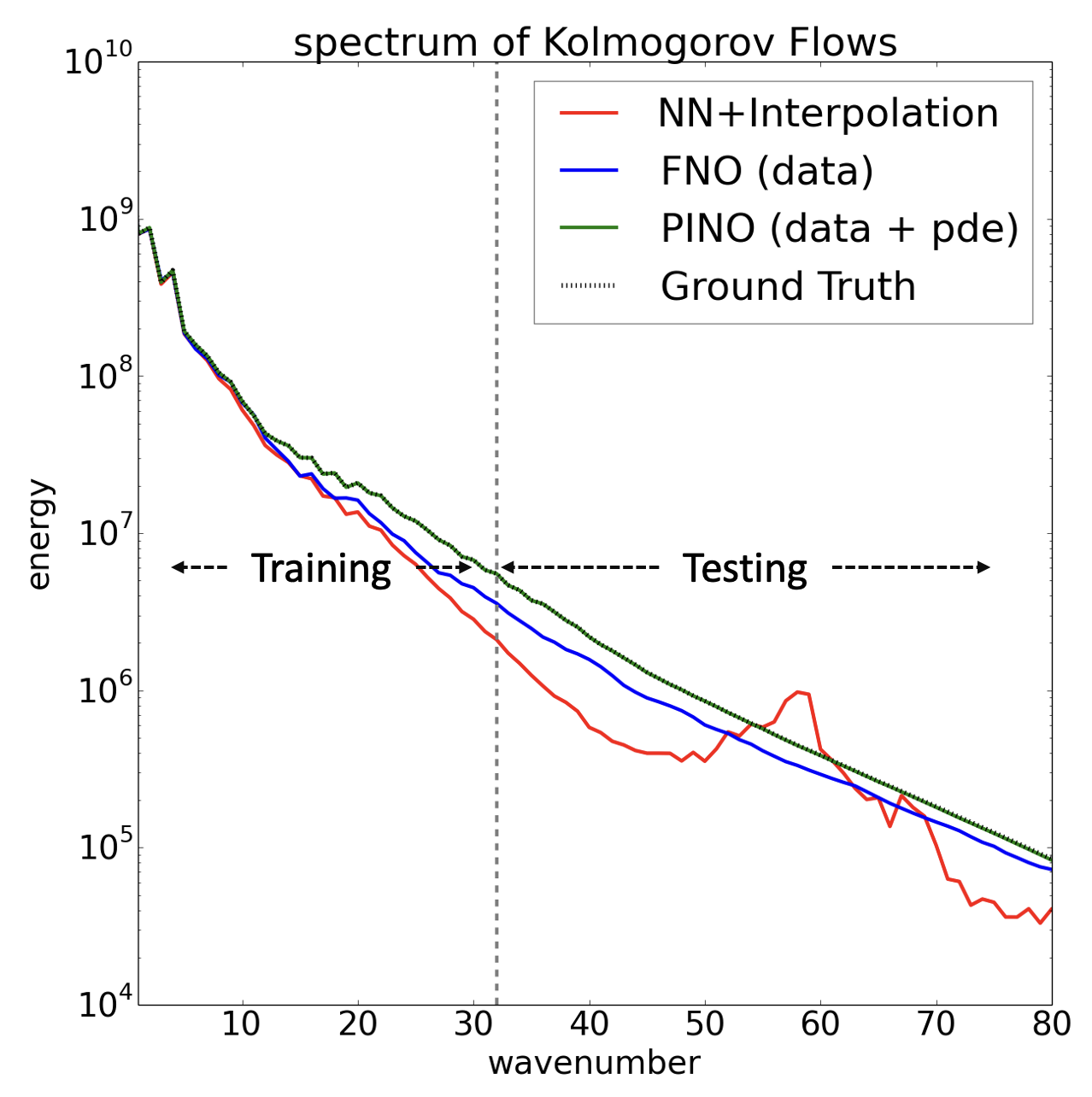
Figure 1: PINO uses both training data and PDE loss function and perfectly extrapolates to unseen frequencies in Kolmogorov Flows.
Methodology
PINO employs the FNO framework, known for being a universal approximator of any continuous operator, to create a model that not only learns from data but also adheres to PDE constraints during training. The approach involves a two-phase process: (1) operator learning phase where the neural operator learns using both data and PDE constraints, and (2) instance-wise fine-tuning where the learned operator is refined to target specific PDE instances.
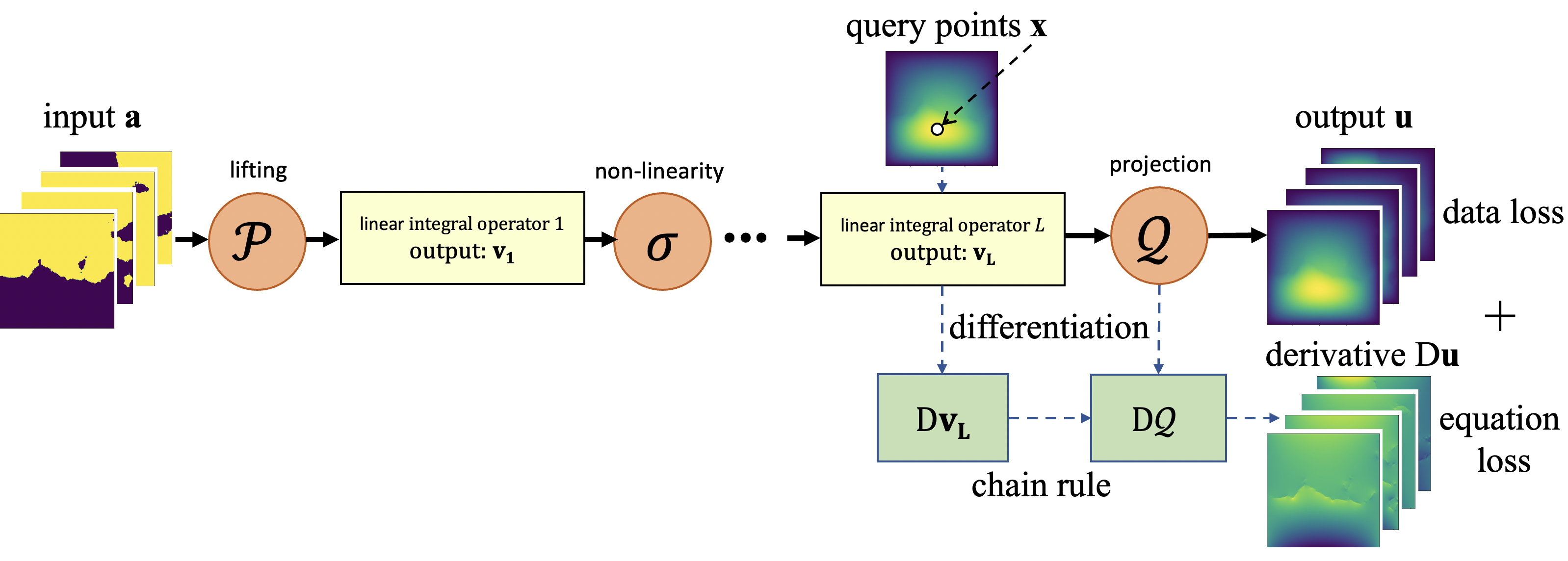
Figure 2: PINO trains the neural operator with both training data and PDE loss function.
The neural operator architecture comprises multiple layers, each performing a linear integral operation followed by non-linear transformation, capturing complex dynamic processes at various resolutions. By combining physics loss and data loss, PINO effectively generalizes to high-resolution scenarios, maintaining accuracy without requiring extensive high-resolution data for training.
Experimental Results
Empirical evaluations demonstrate that the inclusion of PDE constraints significantly enhances the generalization capability of neural operators across resolutions, providing error rates notably lower than those seen with conventional models. For instance, PINO achieves a relative error reduction on chaos-driven Kolmogorov flows when compared to models solely trained on data. It efficiently handles scenarios such as zero-shot super-resolution, where it predicts highly accurate solutions for higher resolutions than those used during training.
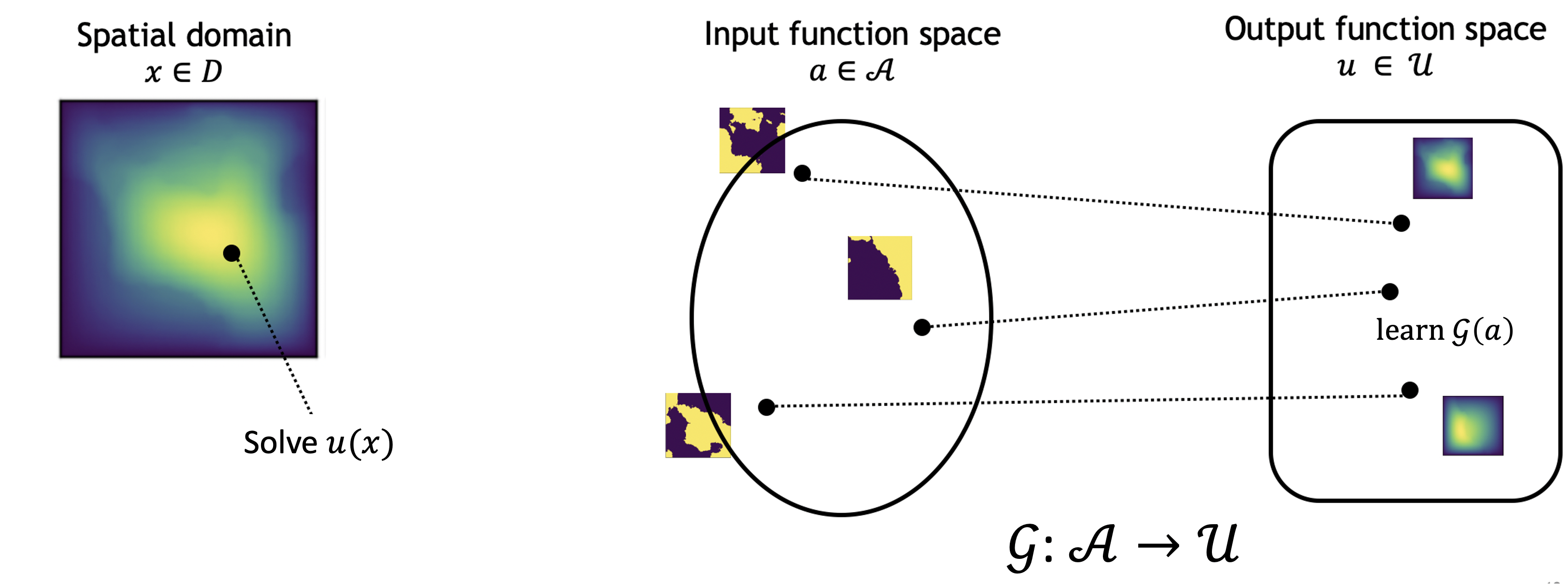
Figure 3: Solve for one specific instance versus learn the entire solution operator.
In tests with Burgers' equation and Darcy flow, PINO achieves substantial accuracy improvements, beating data-only models. Specifically, when trained with coarse data and extrapolating to high-resolution domains, it consistently surpasses traditional neural operators like FNO, which lack PDE-informed constraints.
In examining transferability, PINO shows potential in adapting models across different parameter settings, such as varying Reynolds numbers in fluid dynamics studies, highlighting its robustness and flexibility in diverse PDE contexts.
PDE Constraints in Inverse Problems
PINO's utilization extends to inverse problems where it efficiently recovers coefficient functions or input conditions by optimizing using both data and PDE loss functions. This approach confines the solution space to the solution manifold of the underlying PDE, ensuring physically plausible estimations.
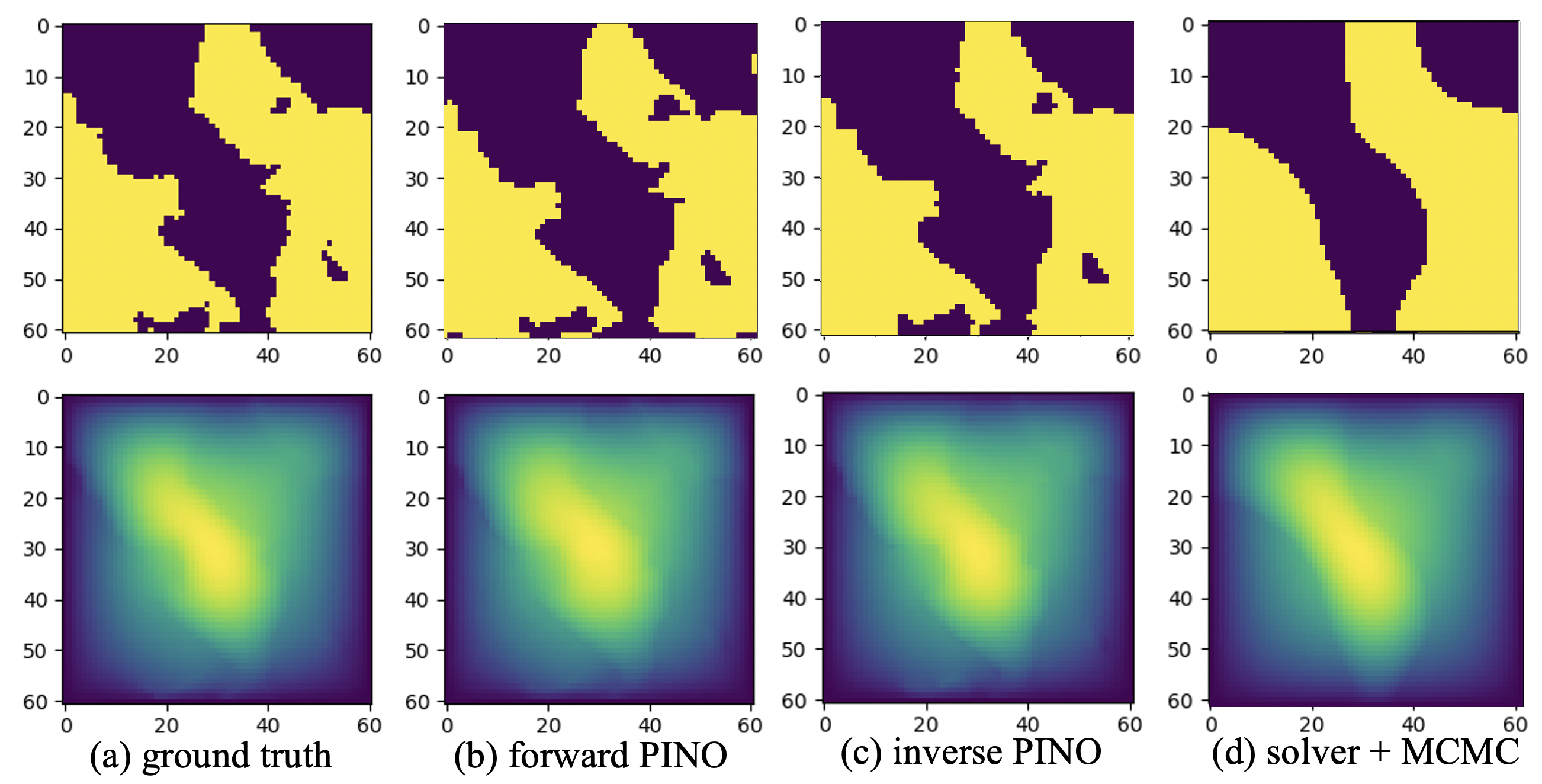
Figure 4: Darcy inverse problem: comparing PINO forward and inverse models with numerical solver with MCMC.
Conclusion
PINO presents a powerful framework bridging the gap between data-driven and physics-informed methods for PDEs. By integrating operator learning with instance-wise fine-tuning, it offers a solution capable of operating across a range of resolutions without loss of accuracy. Future research may focus on refining the optimization landscape and exploring broader applications, including extending PINO to domains requiring generalization over diverse geometric configurations or under different boundary conditions. The implications of this research are considerable, paving the way for more efficient, robust, and flexible solutions to PDE-related challenges in scientific computing.