- The paper introduces a DMRL model that uses disentangled representations and distance correlation for robust, modality-specific preference modeling.
- It employs a shared-weight neural attention mechanism to differentiate user influences across item IDs, texts, and images.
- Experimental results on Amazon reviews show superior performance over baseline methods, highlighting its practical impact.
Disentangled Multimodal Representation Learning for Recommendation
Introduction
The paper introduces a Disentangled Multimodal Representation Learning (DMRL) model aimed at enhancing recommendation systems by effectively harnessing multimodal side information such as reviews and images. The fundamental premise of DMRL is to address the limitations in current methods that inadequately consider the varying importance users place on different modalities when forming preferences for various item factors, such as appearance or quality. By implementing disentangled representation techniques and multimodal attention mechanisms, DMRL aims to provide a more nuanced understanding of user preferences across different modalities and item factors.
Disentangled Representation Learning
The DMRL model segments the feature space of each modality (including user ID, item ID, textual, and visual features) into multiple chunks, each representing a latent factor. This process involves distance correlation as a regularization term to enforce independence among factor representations within each modality. Such disentangling improves the robustness and expressiveness of the learned representations, mitigating the risk of feature redundancy and leading to better preference modeling.
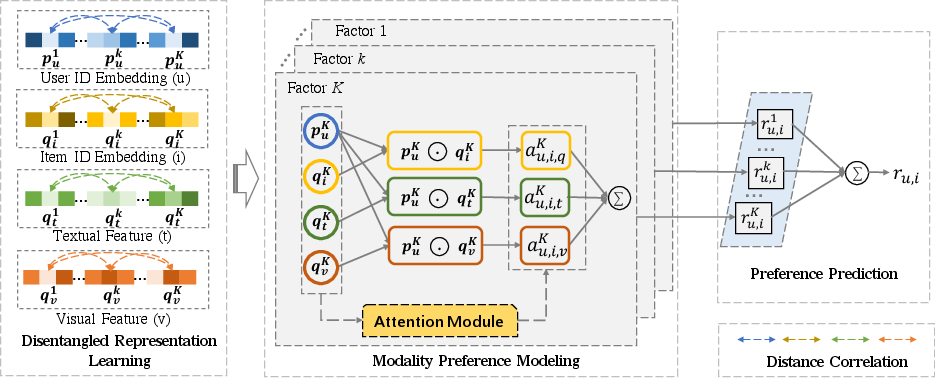
Figure 1: Overview of our DMRL model. Best viewed in color.
Modality Preference Modeling
An essential aspect of DMRL is its capacity to model user-specific attention weights for different modalities in relation to each item factor. The methodology incorporates a shared-weight neural attention mechanism that derives these weights, allowing for the differentiation of user preference influence across item IDs, textual descriptions, and visual features (Figure 2). The modality preference mechanism ensures that the final recommendation captures the complexity and diversity of user likes and dislikes across various content types.
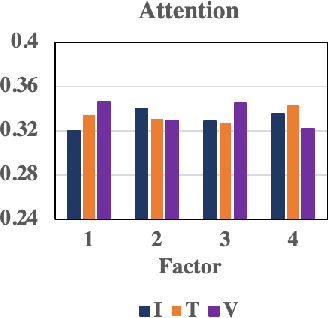
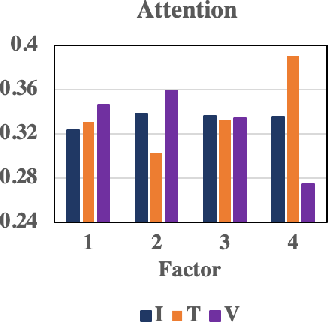
Figure 2: Attention weights of different modalities. I, T and V represent item ID, textual feature and visual feature, respectively.
Preference Prediction
DMRL predicts user preferences by consolidating the weighted preferences from different modalities for each item factor. The model calculates a weighted preference score using dot product interactions between user and item representations, effectively summarizing user preferences into a comprehensive score that accounts for the varied contributions of different modality features.
Experimental Evaluation
Trials conducted on five datasets from the Amazon review corpus helped demonstrate DMRL's effectiveness. Compared to baseline methods such as NeuMF, CML, and MMGCN, DMRL showed superior performance across various metrics, underscoring the importance of leveraging both multimodal information and disentangled representation techniques in recommendation tasks.
Notably, DMRL achieved a significant uptick in performance owing to its ability to integrate user-specific modality preferences and disentangled multimodal features (Figure 3). This integration addresses the nuanced ways users evaluate items across multiple presentation forms, ultimately leading to more accurate and satisfying recommendations.
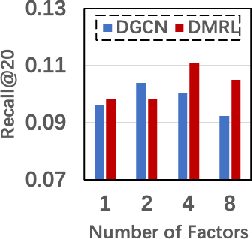
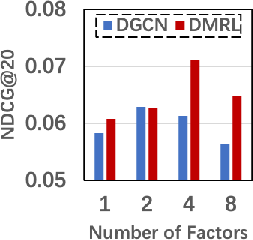
Figure 3: Impact of the Factor Number (K).
Implications and Future Work
DMRL represents a sophisticated approach to personalized recommendation by highlighting the role of disentangled representation and modality-specific preference modeling. The findings suggest a potential trajectory for future research into the fine-grained incorporation of multimodal information and personalized attention mechanisms in AI-driven recommender systems. Future developments might explore more dynamic attention mechanisms and further optimize disentanglement processes to overcome remaining challenges related to data sparsity and feature independence.
Conclusion
The Disentangled Multimodal Representation Learning model offers a promising advancement in recommendation systems, leveraging advanced techniques to decipher and apply user preferences across varied content forms. By effectively disentangling item factors and capturing user modality preferences, DMRL enhances the capability to accurately predict user interests, thereby paving a path for future innovations and practical applications in AI and recommendation technologies.