- The paper presents Dress Code, a high-resolution dataset addressing previous limitations by featuring over 50,000 image pairs across diverse garment categories.
- It introduces a novel three-stage pipeline and a Pixel-level Semantic-Aware Discriminator (PSAD) that significantly enhances image synthesis realism.
- Experimental results show superior performance over nine state-of-the-art methods, with improved metrics like FID and KID in multi-garment and high-resolution settings.
Dress Code: High-Resolution Multi-Category Virtual Try-On
Introduction
The paper introduces "Dress Code," a high-resolution dataset for virtual try-on that incorporates a diverse range of clothing categories, addressing significant limitations found in previous datasets. The focus of image-based virtual try-on (VTON) is to realistically synthesize images of a person wearing a target garment without altering their intrinsic attributes like body shape and pose. This paper leverages the Dress Code dataset to propose a new architecture that leverages a Pixel-level Semantic Aware Discriminator (PSAD) for enhanced visual realism.

Figure 1: Differently from existing publicly available datasets for virtual try-on, Dress Code features different garments, also belonging to lower-body and full-body categories, and high-resolution images.
Dataset Description
Dress Code dataset stands out due to its inclusion of over 50,000 high-resolution image pairs (1024x768 pixels), encapsulating a wide variety of upper-body, lower-body, and full-body clothing. Motivated by the constraints of existing datasets, which fail to cater to full-body and lower-body garments, Dress Code offers a significant advancement in terms of scale and detail.












Figure 2: Sample image pairs from the Dress Code dataset with pose keypoints, dense poses, and segmentation masks of human bodies.
Proposed Architecture
The architecture employs a three-stage pipeline: garment warping, human parsing estimation, and final image generation. The innovation in this architecture is the introduction of the PSAD, which enhances image realism by learning pixel-level semantic correlations instead of focusing only on image-level or patch-level details.
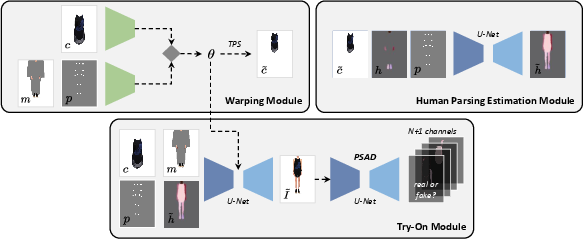
Figure 3: Overview of the proposed architecture.
Pixel-level Semantic-Aware Discriminator (PSAD)
PSAD improves image synthesis by embedding detailed semantic class predictions at the pixel level. It learns internal semantic representations and enforces the generator to produce high-quality images by accounting for semantic discrepancies.
Experimental Results
Dress Code serves as a new benchmark for VTON systems, meticulously compared against nine state-of-the-art approaches. Models were trained across various image resolutions, including 512x384, and 1024x768, highlighting the capacity of Dress Code to maintain synthesis quality at high resolutions.
High-Resolution and Multi-Garment Settings
The proposed system showcases superior performance in high-resolution settings, maintaining image details across different clothing categories. Further, a novel multi-garment try-on setting was introduced, demonstrating effective image synthesis in scenarios that require multiple garments to be overlaid seamlessly.






























Figure 4: Sample try-on results on the Dress Code test set.
Qualitative Comparisons
Significant improvements are observed in qualitative assessments, where Dress Code outperformed traditional patch-based baselines. Particularly, PSAD achieved significant improvements in synthesis realism over common metrics such as the Frechet Inception Distance (FID) and Kernel Inception Distance (KID).


















Figure 5: Qualitative comparison between Patch and PSAD.
Conclusion
The Dress Code dataset and associated architecture address critical shortcomings in existing VTON frameworks by supporting high-resolution multi-garment try-ons, significantly advancing the real-world applicability of virtual try-on systems. Future work will likely explore more intricate interactions between multiple garment layers using the Dress Code framework. The dataset and models can drive further research, potentially extending into more dynamic domains such as video-based try-on scenarios.