- The paper demonstrates that dropout probes effectively reveal when syntax is causally used in neural language models by addressing representational redundancy.
- The methodology applies dropout layers to encourage probes to utilize complete syntactic information, validated through experiments on QA and NLI tasks.
- The approach not only clarifies the role of syntax but also improves model performance by injecting syntactic cues during test time.
This paper examines the role of syntax in neural LLMs, revealing circumstances under which models utilize syntactic representations. Utilizing dropout probes, the authors present a novel strategy for probing syntactic information within embeddings. This work explores syntactic redundancy, causal use of syntax, and methods for enhancing model performance by injecting syntactic information.
Introduction to Probing Redundancy
Probes are auxiliary models that assess whether linguistic properties are encoded in model embeddings. Previous probing methods suggested that syntactic information is not always causally used, potentially leading to false negatives due to redundancy in representations.
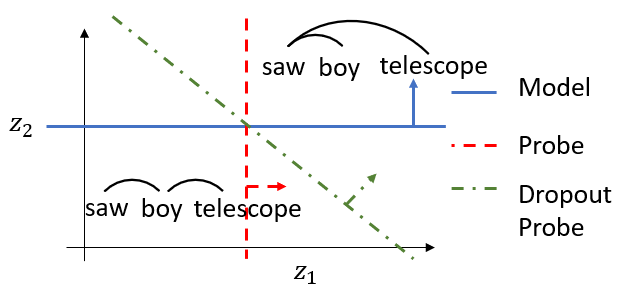
Figure 1: In a 2D embedding space, a model might redundantly encode syntactic representations of a sentence like ``the girl saw the boy with the telescope.'' Redundant encodings could cause misalignment between the model's decision boundary (blue) and a probe's (red). We introduce dropout probes (green) to use all informative dimensions.
The paper identifies representational redundancy in BERT, evidenced by mutual information measures. This redundancy can lead to probes and models utilizing different aspects of syntax, resulting in inefficacious probing methods.
Dropout Probes: Design and Functionality
Dropout probes are introduced to address the observed redundancy. By incorporating dropout layers, these probes are encouraged to use all syntactic information present, improving their ability to detect causal use of syntax by the model.
The design employs training with input dropout, serving two purposes: encouraging robust learning by the probes and enabling better alignment with model usage at test time.
Experimental Verification
The proposed dropout probes were empiratically tested on various tasks using models such as BERT (pre-trained and finetuned for QA and NLI tasks). The experiments demonstrated the efficacy of dropout probes in revealing syntactic causality where traditional probes did not.
Findings on Redundancy
The empirical estimation of mutual information confirmed the redundant encoding of syntax in embeddings. This finding justifies the need for dropout probes to account for all dimensions of information.
Assessing Causal Use
Causal analysis was conducted using syntactically ambiguous sentences. Results indicated that dropout probes detected syntactic causality in models like QA, where traditional probes had failed.
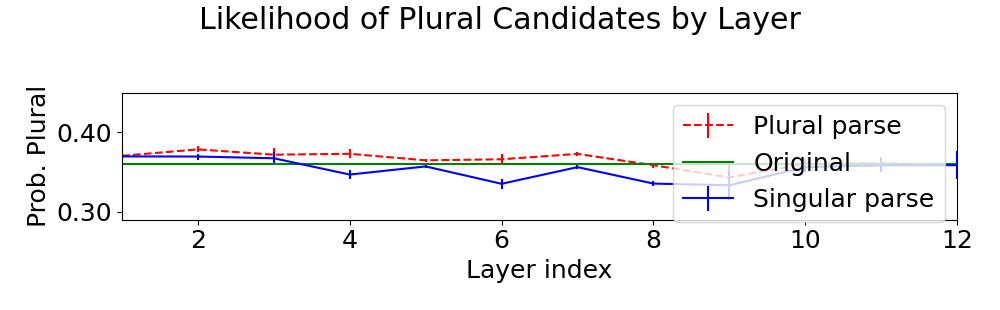
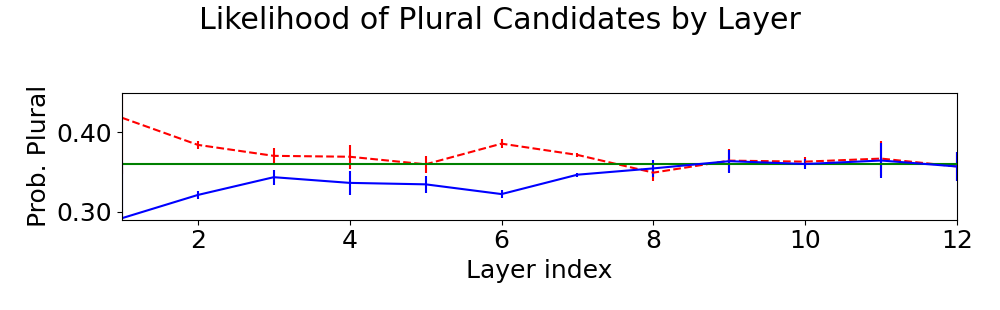
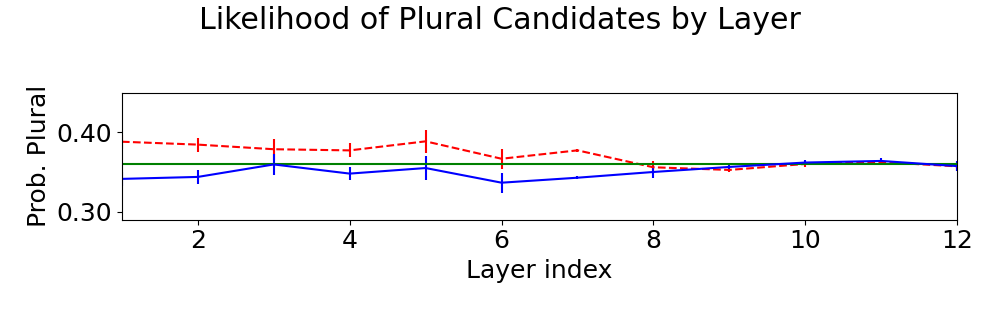
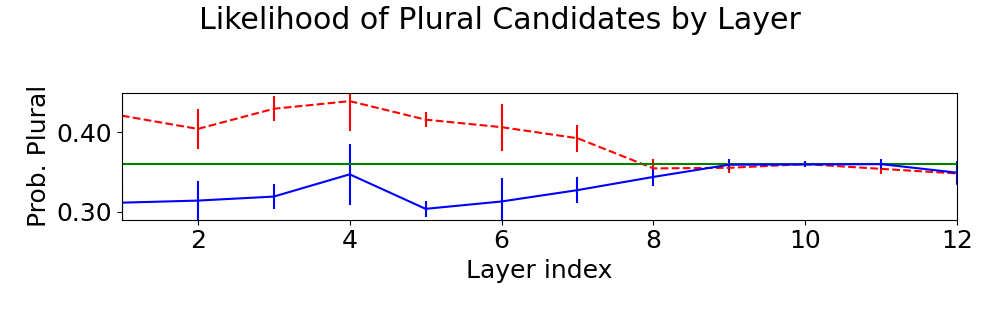
Figure 2: Mean and standard deviation probabilities over 5 trials for plural candidates using the original embeddings (green) or counterfactual embeddings favoring plural (dashed red) or singular (solid blue) parses. Counterfactual embeddings generated by both depth- and distance-based probes caused the greatest shift in model predictions.
Beyond causal detection, dropout probes were leveraged to improve model performance in syntactically challenging QA tasks by injecting syntactic information at test time.
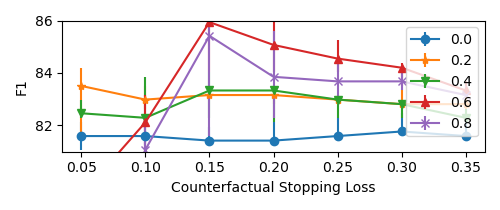
Figure 3: Using dropout probes over a range of dropout values (different curves) and counterfactual stopping losses improved model performance, and dropout typically improved performance. Medians and quartiles plotted over 5 trials.
This approach leads to significant enhancements in model accuracy without necessitating full retraining.
Conclusion
The research demonstrates that dropout probes provide a significant methodological advancement in probing for syntactic information embedded in neural LLMs. By addressing redundancy, these probes offer a novel path to understanding and enhancing model performance through syntactic insights. Further exploration into the nuanced role of syntax and redundancy in embeddings will likely yield even deeper understanding and stronger models in the future of AI research.