- The paper introduces crossword solving as a novel NLP benchmark with new datasets and constraint satisfaction challenges.
- The research utilizes both retrieval-augmented and SMT-based methods to model clue-answering and full puzzle solving.
- Results reveal that even advanced models achieve only ~24% word accuracy, highlighting significant room for methodological improvement.
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
Introduction
The paper "Down and Across: Introducing Crossword-Solving as a New NLP Benchmark" (2205.10442) presents crossword puzzle solving as a novel NLP challenge. Crossword puzzles necessitate complex linguistic reasoning, extensive world knowledge, and the ability to meet structured constraints within a puzzle grid. This task is motivated by the limitations of existing NLP models which are prone to fragility and sensitivity to data patterns [wallace2019universal, mccoy2019right]. The proposed benchmark leverages the New York Times daily crosswords spanning 25 years, with approximately nine thousand puzzles featuring diverse clue types such as historical, factual, synonyms, and wordplay.
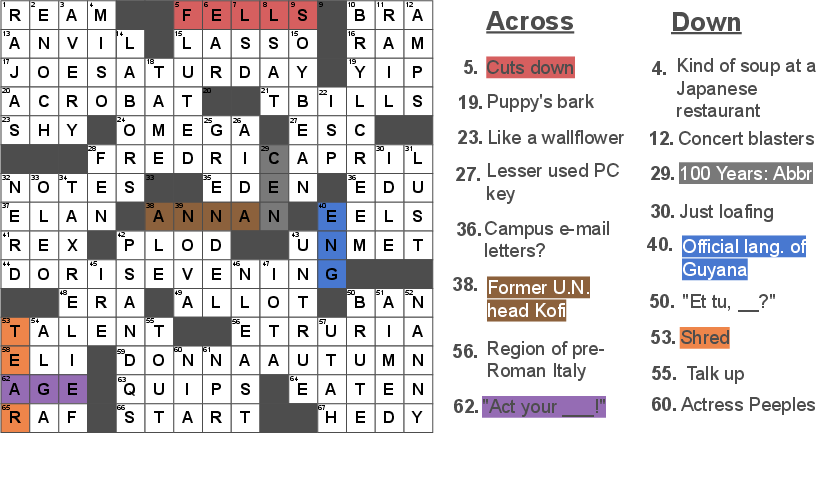
Figure 1: Crossword puzzle example from July 7, 2009 New York Times daily crossword, illustrating multiple clue categories.
Dataset and Task Description
The paper introduces two datasets: the NYT Crossword Puzzle dataset and the NYT Clue-Answer dataset. The former includes the original puzzle grid requiring complete solution generation, while the latter consists of over half a million unique clue-answer pairs formatted as open-domain QA tasks. These datasets facilitate two subtasks—independent clue-answer solving and the constraint satisfaction problem of completing the entire puzzle grid.
Crossword puzzles are characterized by stringent constraints requiring answers to be correct in context, exact character length, and potential overlap with other answers. Evaluating this task involves complementary performance metrics including Exact Match, Character Accuracy, and Word Accuracy, alongside metrics indicating the extent of puzzle relaxation needed for solutions, such as Word Removal and Character Removal.
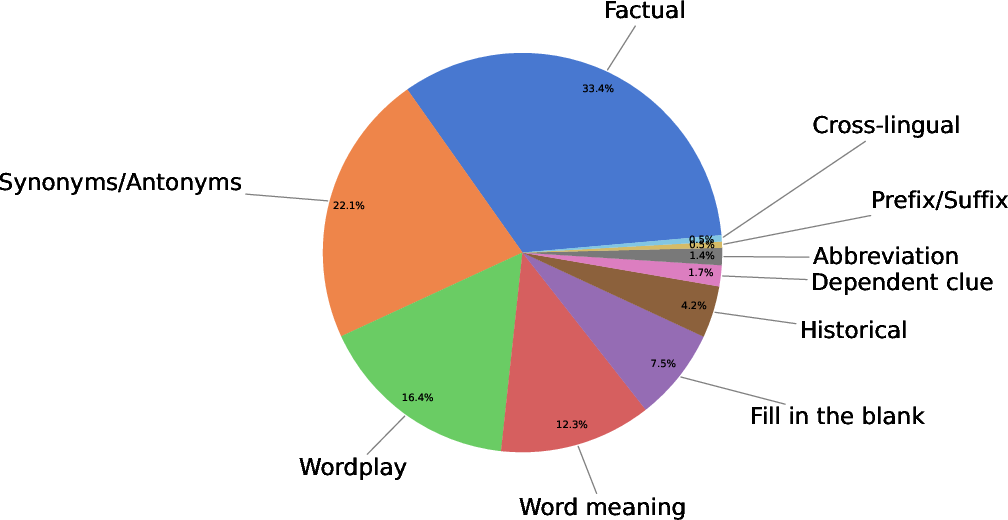
Figure 2: Distribution of annotated clue types among the test examples indicates diverse reasoning requirements.
Implementation Baselines
Several baseline models were employed, including sequence-to-sequence models BART and T5, and retrieval-augmented generation (RAG) models utilizing external sources like Wikipedia and dictionaries. Clue-answering performance shows RAG models outperforming sequence-to-sequence counterparts, highlighting the importance of retrieval mechanisms in acquiring factual content.
For solving entire crosswords, baseline methods modeled the problem as Satisfiability Modulo Theories (SMT), using Z3 SMT solver frameworks. Despite promising baseline results, generating accurate complete puzzle solutions is constrained by the pre-filtering requirements to circumvent the oracle based on ground-truth answers.
Results
Benchmark results demonstrate substantial challenges inherent in crossword solving. The best-performing model, RAG-wiki, yields word accuracy at only 23.8% for the full puzzle task, indicating considerable room for future methodological improvements. The clue-answer task shows a significant dependency on retrieval-based approaches, with RAG models achieving nearly double the accuracy compared to fine-tuned BART sequences.
Discussion
This research outlines compelling complexities in developing an end-to-end solution for crossword solving, primarily due to the character-level output requirements and SMT solver constraints. Addressing these constraints involves transforming puzzle systems into efficient probabilistic reasoning modules, driving the exploration of weighted constraint satisfaction solvers for partial solution extraction without oracle dependency.
Conclusion
The paper establishes crossword-solving as a formidable NLP challenge, incorporating diverse linguistic reasoning elements. It provides valuable datasets for enhancing the robustness and reasoning capabilities of existing systems. As AI continues to evolve, crossword puzzles will offer a nuanced testbed for persisting weaknesses in language understanding and constraint satisfaction problems.
The presented crosswords datasets and baseline analyses invoke broader consideration of NLP tasks necessitating complex and interdependent reasoning, encouraging future developments in comprehensive AI systems capable of integrating multi-disciplinary knowledge and reasoning capabilities.