- The paper demonstrates that MIM pre-training enhances performance by emphasizing local image features and maintaining diverse attention mechanisms compared to traditional supervised models.
- The authors show that uniform CKA similarity across layers leads to more stable optimization and transferable feature representations in fine-grained semantic tasks.
- Experimental results indicate that MIM models excel in geometric and motion tasks, achieving faster convergence and improved accuracy in pose and depth estimation.
Revealing the Dark Secrets of Masked Image Modeling
Introduction to Masked Image Modeling
Masked Image Modeling (MIM) represents a promising shift in the paradigm of pre-training tasks within computer vision. Historically, supervised classification tasks on datasets like ImageNet have been the primary driver of advances in visual representation learning. However, MIM offers a self-supervised alternative, wherein portions of input images are masked, and the model learns by predicting the masked parts. This approach not only offers strong pre-training accuracy on geometric, motion, and fine-grained classification tasks but also introduces unique representational characteristics.
Visualizations and Representational Differences
Attention Mechanisms and Locality Inductive Bias
Attention mechanisms in Vision Transformers (ViT) play a crucial role in revealing the differences between MIM and traditional supervised models. MIM models exhibit a stronger locality inductive bias compared to their supervised counterparts. While supervised models tend to focus globally in higher layers, MIM models consistently maintain diverse attention across all layers, aggregating both local and global information. This is evident in the averaged attention distances across layers, where MIM models show a propensity to attend to nearby pixels more frequently.
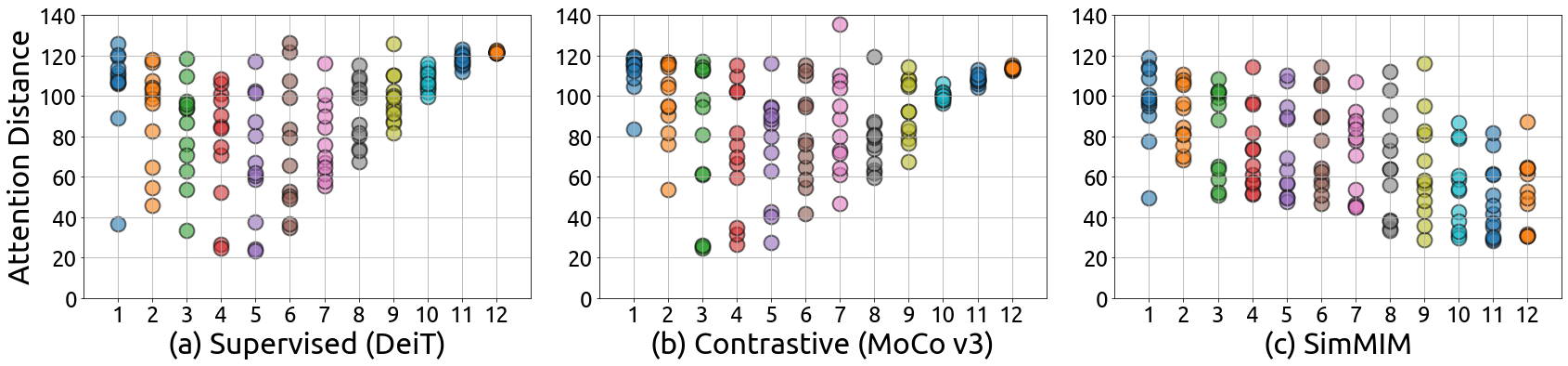
Figure 1: The averaged attention distance in different attention heads (dots) w.r.t. the layer number on supervised model (a), contrastive learning model (b), and SimMIM model (c) with ViT-B as the backbone architecture.
Diversity in Attention Heads
Another interesting aspect of MIM models is their ability to maintain diversity among attention heads throughout the layers. In contrast, supervised models often lose this diversity as they go deeper, which can adversely affect fine-tuning performance on downstream tasks. MIM models, with their large KL divergence among attention heads, demonstrate a better aggregation of different tokens, contributing to enhanced representational flexibility.
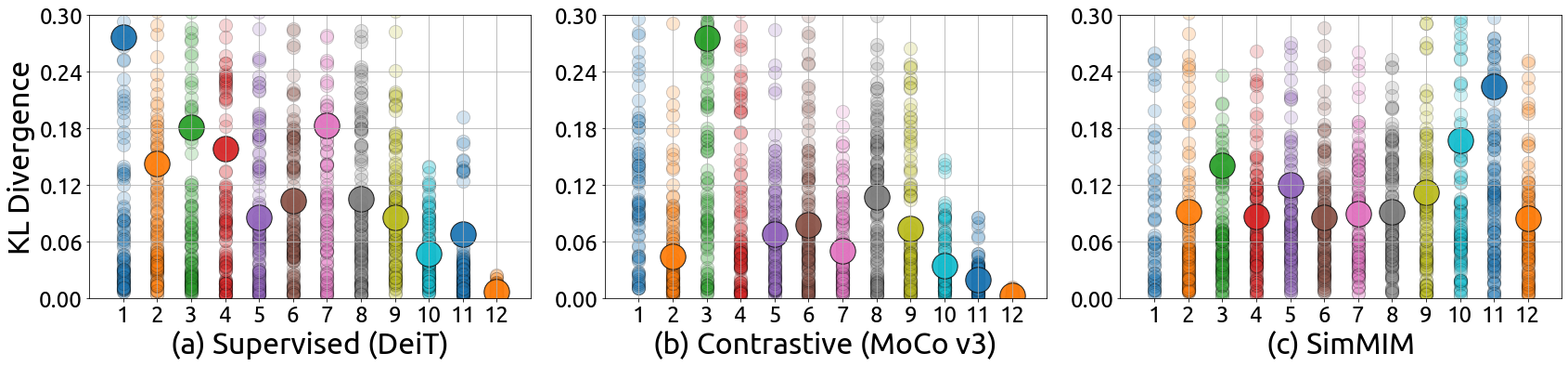
Figure 2: The KL divergence between attention distributions of different heads (small dots) and the averaged KL divergence (large dots) in each layer w.r.t. the layer number on (a) the supervised model, (b) contrastive learning model, and (c) SimMIM model with ViT-B as the backbone architecture.
CKA Similarity and Layer Representations
Feature representation similarity, as gauged by Centered Kernel Alignment (CKA), further differentiates MIM models. While supervised models show varied CKA similarity across different layers, indicating learning of distinct representation structures, MIM models exhibit high CKA values across layers. This suggests a uniformity in representation structures, facilitating easier optimization and transferability in downstream tasks.
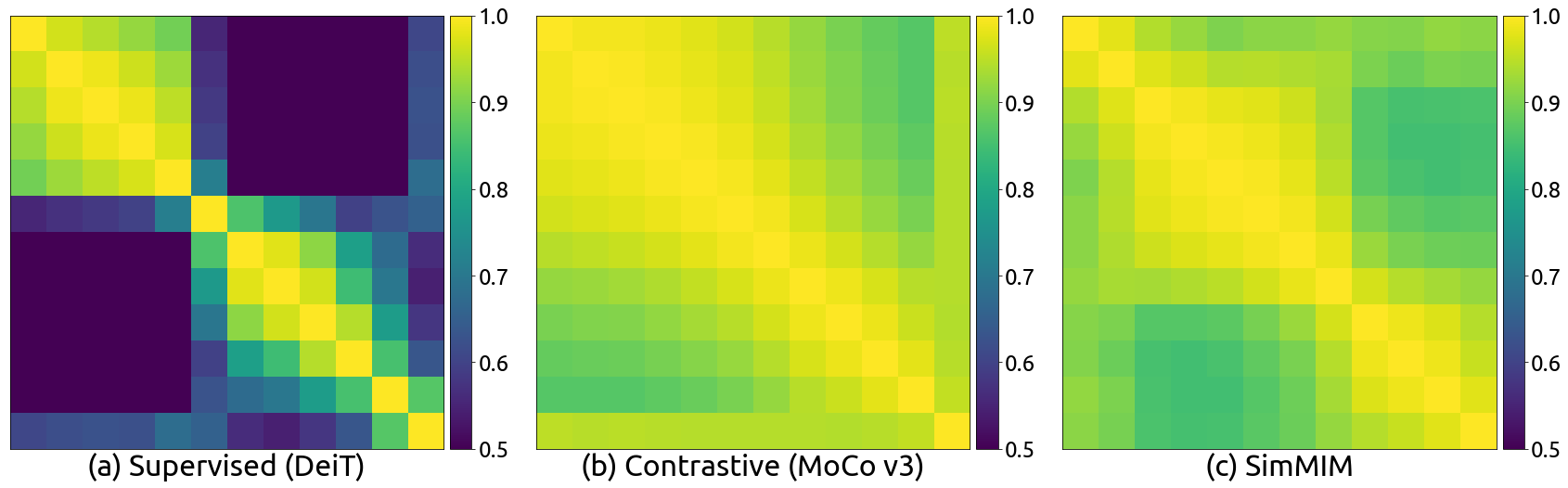
Figure 3: The CKA heatmap between the feature maps of different layers of (a) supervised model, (b) contrastive learning model, and (c) SimMIM model with ViT-B as the backbone architecture.
Experimental Insights Across Tasks
Semantic Understanding
In semantic understanding tasks, MIM models show their strength primarily in fine-grained and conceptually distinct datasets not well-covered by ImageNet categories. Although supervised models perform better in settings where categories are directly aligned with ImageNet, MIM models excel in understanding and generalizing across diverse and new categories.
Geometric and Motion Tasks
Significantly, MIM pre-trained models outperform supervised models by large margins on geometric and motion tasks, such as pose estimation and depth estimation. This suggests that the strong locality and diversity delivered through MIM pre-training are particularly advantageous for tasks requiring precise spatial reasoning and object localization.
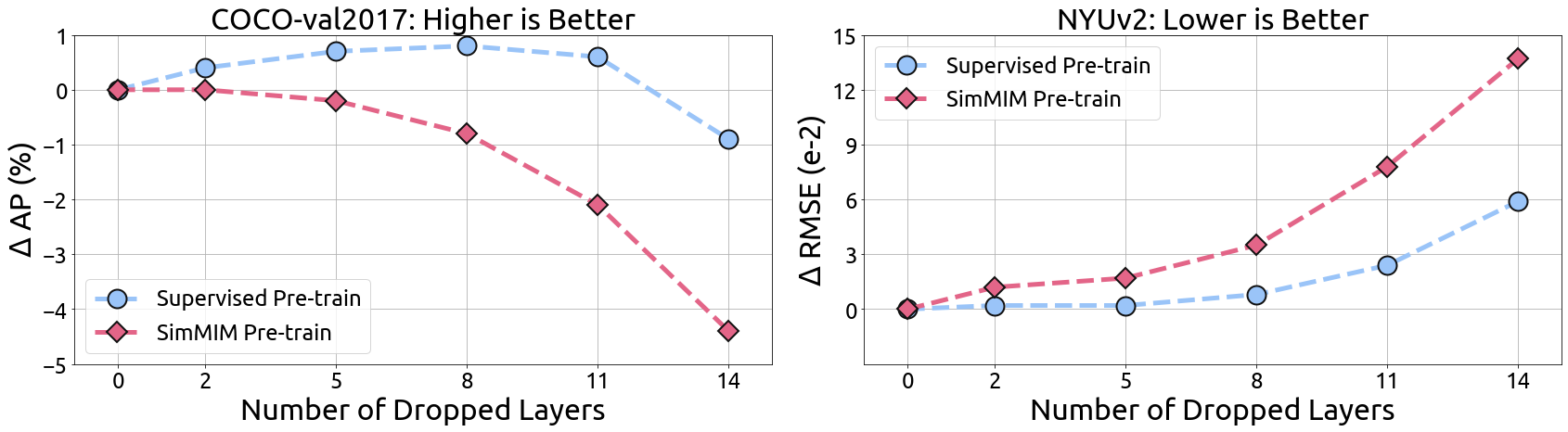
Figure 4: The performance of the COCO val2017 pose estimation (left) and NYUv2 depth estimation (right) when we drop several last layers of the SwinV2-B backbone.
Combined Tasks
For combined tasks like object detection, MIM models retain competitive performance, sometimes surpassing supervised models. Detailed examination of task-specific training losses reveals faster convergence in localization tasks for MIM models, highlighting the beneficial impact of MIM pre-training on component learning processes within complex tasks.
Conclusion
The analysis of MIM pre-training elucidates several key advantages, particularly its locality bias and diversity maintenance across layers and attention heads. These traits not only enable superior fine-tuning performance on a broader range of tasks but also position MIM as a formidable alternative to traditional supervised pre-training models. The efficacy of MIM across geometric/motion tasks and its competitiveness in semantic understanding tasks herald a shift toward embracing masked image modeling as a versatile tool in visual representation learning. This research invites further exploration into MIM's applications and optimizations, advocating for its wider adoption in the community and its utilization as a foundation for future advancements.