- The paper introduces Siamese Image Modeling (SiameseIM), a dual-branch framework that merges instance discrimination and masked image modeling to overcome spatial and semantic limitations.
- The paper employs a novel positional embedding mechanism and dense loss to effectively align and reconstruct representations from different augmented views.
- The paper's experiments demonstrate significant improvements across benchmarks like ImageNet classification, COCO detection, and ADE20k segmentation.
Siamese Image Modeling for Self-Supervised Vision Representation Learning
Abstract
This paper introduces a novel framework for self-supervised learning (SSL) in vision tasks, termed Siamese Image Modeling (SiameseIM). Drawing insights from existing SSL paradigms, such as Instance Discrimination (ID) and Masked Image Modeling (MIM), SiameseIM addresses limitations in spatial sensitivity and semantic alignment through a dual-branch Siamese network architecture. The proposed method surpasses traditional ID and MIM techniques across numerous downstream tasks, including ImageNet finetuning, linear probing, COCO detection, and ADE20k semantic segmentation.
Introduction
Self-supervised learning has garnered attention for its ability to leverage unlabeled data, competing closely with supervised learning in vision domains. ID and MIM have been prominent SSL frameworks, each with distinct properties: ID ensures semantic alignment by pulling together augmented views but lacks spatial sensitivity, while MIM reconstructs images from masked versions but struggles with semantic alignment. SiameseIM integrates the strengths of both approaches by using a dual-branch network to process augmented views from the same image, facilitating dense representation prediction through semantic matching and spatial modeling.
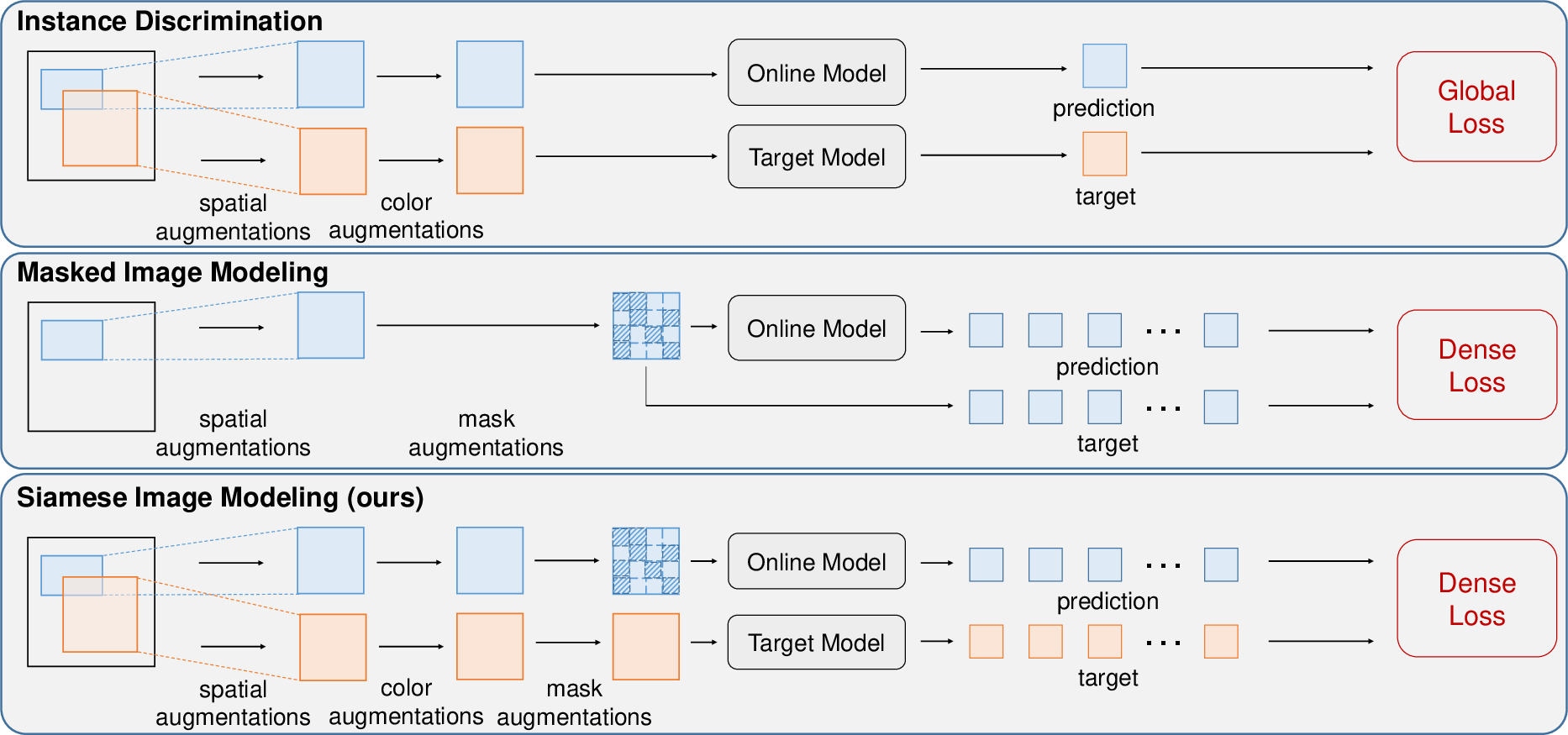
Figure 1: Comparisons among ID, MIM and SiameseIM. Matching different augmented views can help to learn semantic alignment, which is adopted by ID and SiameseIM. Predicting dense representations from masked images is beneficial to obtain spatial sensitivity, which is adopted by MIM and SiameseIM.
Methodology
Siamese Network Architecture
SiameseIM utilizes a Siamese network with two branches: the online branch employs an encoder to process visible patches of the first augmented view. A decoder follows, reconstructing the second view's representation based on relative positional information. The target branch encodes the second view using a momentum-based approach, establishing prediction targets.
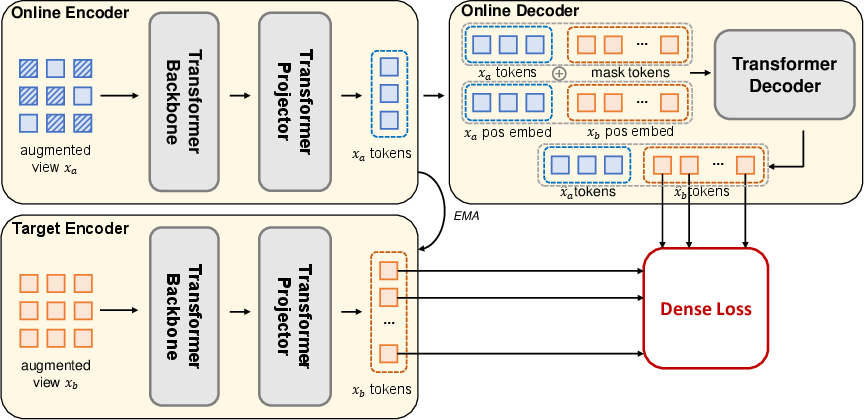
Figure 2: The overview of our Siamese Image Modeling (SiameseIM). Different augmented views are fed into the online and target branches. The online encoder operates on the visible patches of xa. The online decoder accepts the xa tokens as well as mask tokens that correspond to predicted xb tokens. We use relative positions to inform the locations between xa and xb. The target encoder maps xb to the target representations. We finally apply the dense loss on the dense representations.
Positional Embedding and Dense Loss
A novel positional embedding mechanism enables the network to consider the positional variations between augmented views, critical for spatial alignment. The reconstruction process applies a dense loss, derived from ID methods and optimized for memory efficiency, aligning semantic and spatial representations without the need for global loss components.
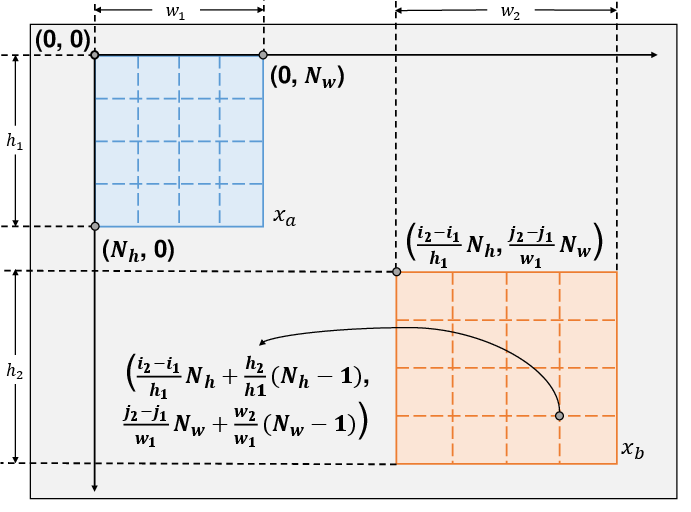
Figure 3: Positional embedding for online decoder. The positions are calculated with respect to the left-top origin of xa.
Experimental Results
Extensive experiments demonstrate the superiority of SiameseIM over established SSL frameworks:
- Image Classification: SiameseIM achieves top performance in ImageNet finetuning and linear probing, with significant gains in semantic alignment, evidenced by improved few-shot learning results with linear separability in features.
- Object Detection: On COCO and LVIS datasets, SiameseIM delivers marked improvements in spatial sensitivity, particularly benefiting long-tail and robustness-concerned detection scenarios.
- Semantic Segmentation and Robustness: Superior segmentation accuracy is observed on ADE20k, alongside enhanced robustness across various benchmarks, manifesting SiameseIM's balanced feature learning capabilities.
Conclusion
Siamese Image Modeling represents a significant advance in the field of self-supervised learning by harmonizing the benefits of ID and MIM within a singular framework. Through innovative dual-branch architecture and dense loss integration, SiameseIM effectively captures semantic alignment and spatial sensitivity, outperforming traditional SSL methods across diverse vision tasks. The framework opens promising avenues for future SSL research, addressing longstanding dilemmas in feature representation quality.
While the computational demands of SiameseIM necessitate further optimization, its potential to enrich self-supervised vision representation underscores critical strides in AI research, with ongoing efforts directed at refining efficiency and reducing bias risks in SSL deployments.