- The paper introduces Arena-Bench, a comprehensive toolset for creating and evaluating navigation strategies in dynamic environments through both simulation and real-world testing.
- The methodology leverages ROS, integrated simulation environments like Gazebo and Flatland, and supports diverse robot kinematics, facilitating cross-paradigm evaluations including DRL training.
- Experimental results reveal that DRL-based planners excel in high obstacle density scenarios, while classical methods offer smoother trajectories, underscoring practical performance trade-offs.
Arena-Bench: A Comprehensive Benchmark Suite for Obstacle Avoidance in Dynamic Environments
Introduction
The paper "Arena-Bench: A Benchmarking Suite for Obstacle Avoidance Approaches in Highly Dynamic Environments" (2206.05728) introduces a benchmark suite designed to evaluate navigation algorithms in dynamic environments. Autonomous navigation, especially in complex and dynamically changing environments, remains a substantial challenge in robotics. Deep Reinforcement Learning (DRL) has demonstrated considerable potential in this area. However, the existing literature often uses bespoke simulation environments, hindering comparative evaluations. The authors address this gap by proposing Arena-bench, which provides a robust benchmarking ecosystem fully integrated into the Robot Operating System (ROS).
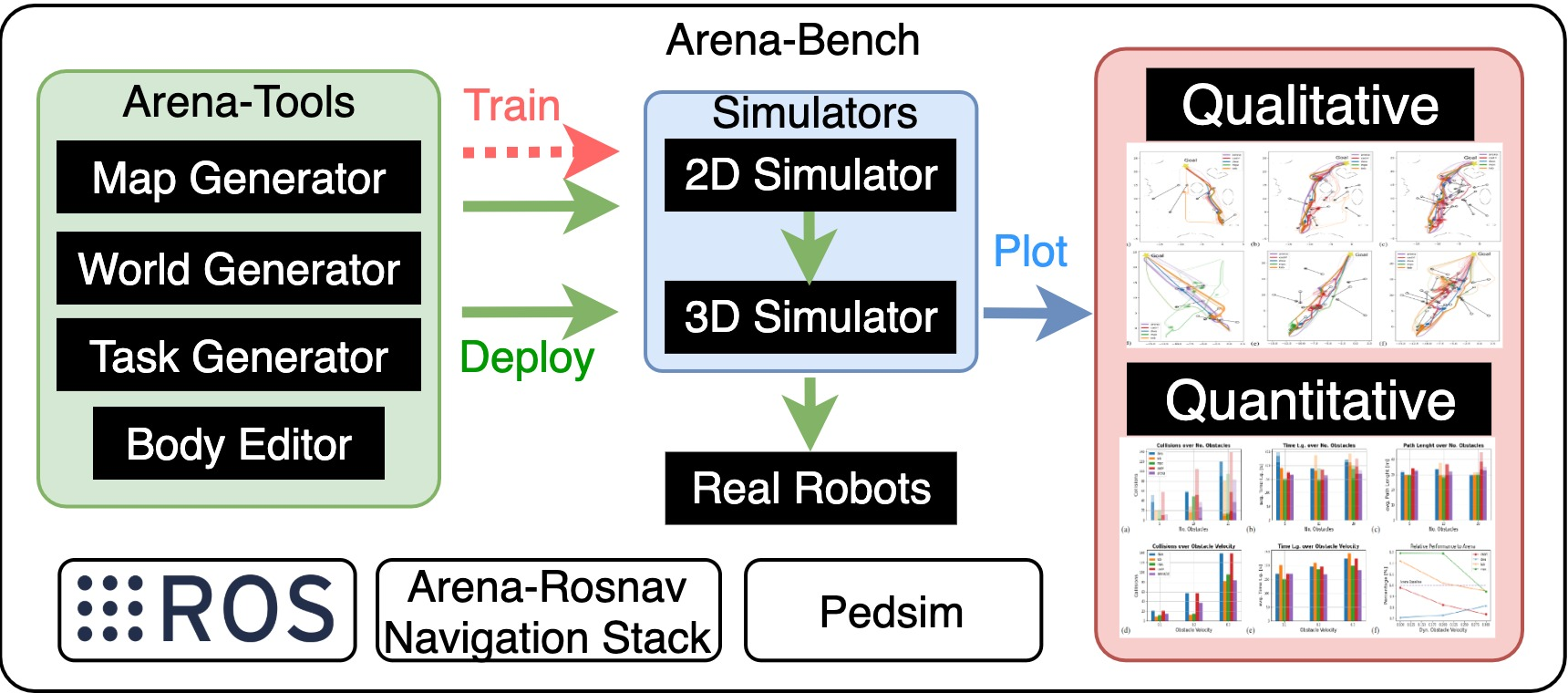
Figure 1: Arena-bench is a benchmark suite that enables to train and evaluate navigation approaches in realistic dynamic environments. It provides tools to develop navigation approaches, design and generate scenarios, and evaluation tasks on a variety of robotic platforms. The results can be plotted on a variety of different navigational metrics.
System Overview
Arena-bench incorporates several modules for designing, generating, and evaluating navigation tasks in both 2D and 3D simulations, leveraging Flatland and Gazebo. This benchmark not only integrates classical and state-of-the-art planners but also supports the training of DRL agents, thereby enabling a cross-paradigm evaluation framework.
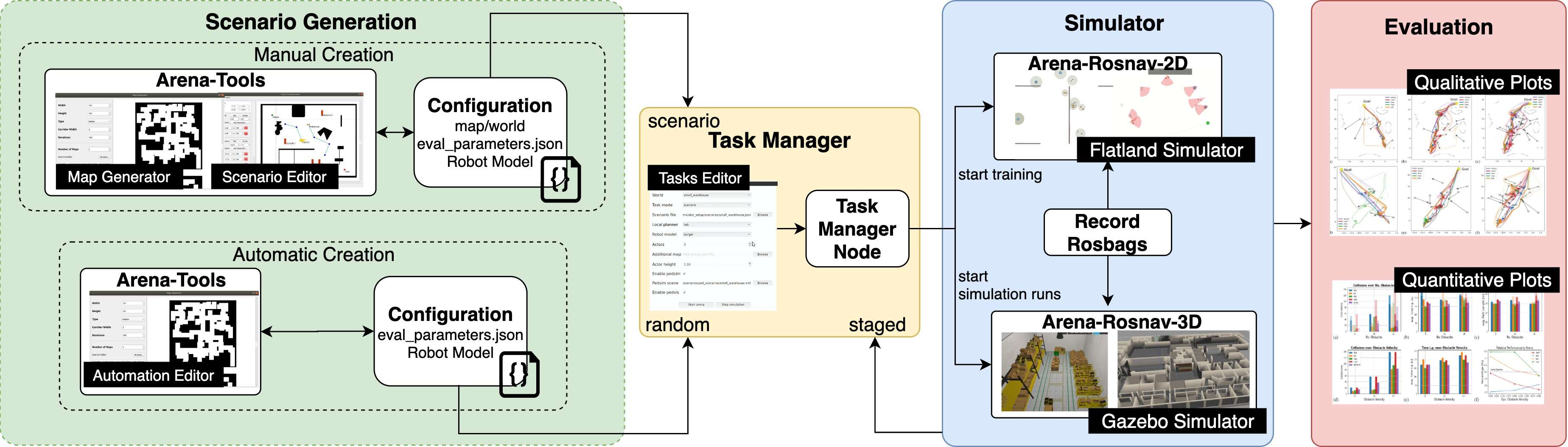
Figure 2: Our proposed benchmark suite consists of multiple modules for designing and generating different scenarios and evaluating different navigation approaches on specifically designed tasks. The suite includes a variety of different robot kinematics, including car-like, holonomic, and differential drive.
Methodology
The paper details Arena-bench's comprehensive toolset, which includes a map generator, a scenario editor, and a task editor. These tools allow for the creation of both static and dynamic environments, supporting an array of robotic kinematics such as differential drive and holonomic models. The integration of the Pedsim library enables the realistic simulation of dynamic obstacles, utilizing the social force model to predict and control obstacle trajectories in real time.
Evaluation Metrics
The evaluation framework within Arena-bench provides quantitative assessments across various metrics, including navigational safety, efficiency, and smoothness. Specifically, the suite measures collision rates, path lengths, and movement jerk, among others, thereby offering a comprehensive profile of each planner's performance under different conditions.
Experiments and Results
Experimental evaluations were conducted using three robotic platforms: Jackal, Turtlebot3 (TB3), and Robotino, across several dynamic scenarios. The results indicated that the DRL-based ROSNAV and AIO planners generally outperformed traditional planners in scenarios with high obstacle density. Classical planners such as MPC and TEB demonstrated superior smoothness but struggled with high dynamics.
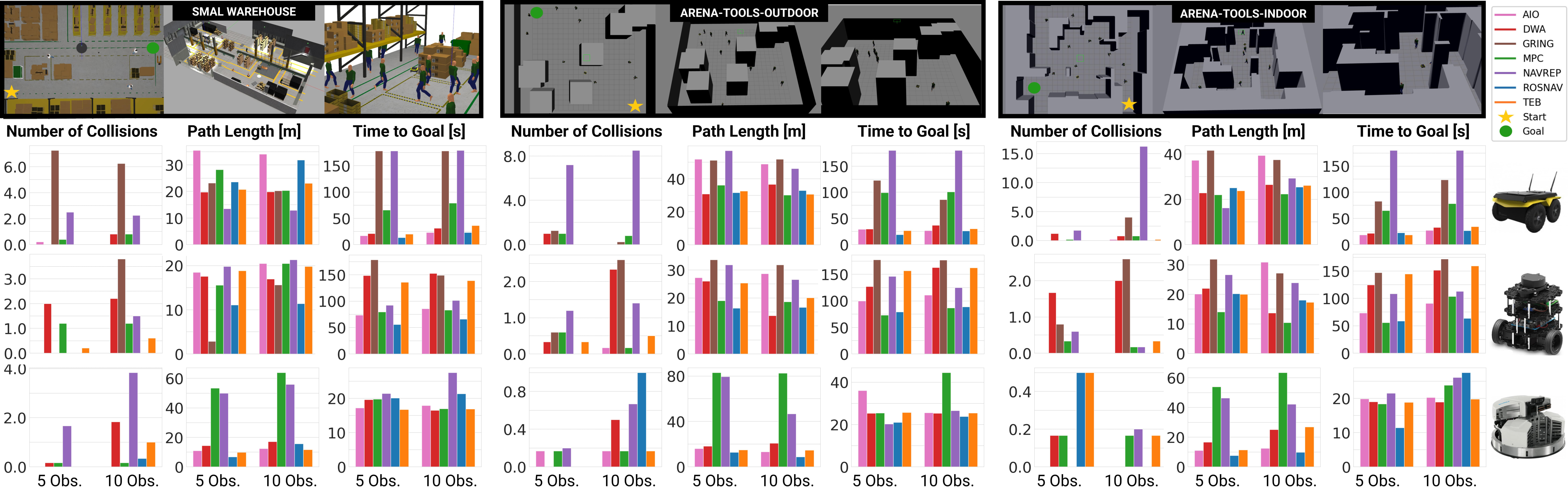
Figure 3: Experiments in simulation. Quantitative results of all planners on three robots over three worlds within the 3D simulation over the number of obstacles.
Real-World Testing
To validate the simulation results, real-world experiments were conducted in a robotics laboratory using the Turtlebot3. The experiments confirmed the validity of the simulation outcomes, though real-world tests introduced expected discrepancies such as localization errors and inconsistent pedestrian behaviors.
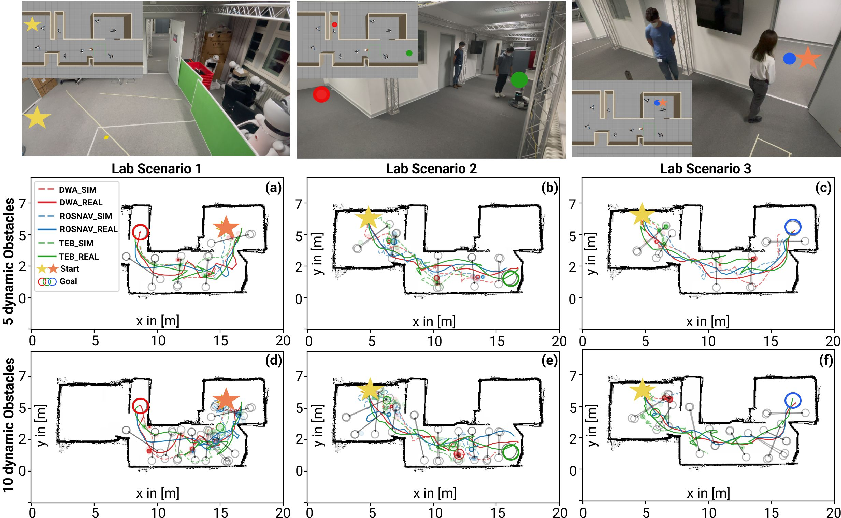
Figure 4: Experiments on the real robot. Upper row: Robotics laboratory where the real experiments were conducted and generated 3D world. Goals are illustrated as colored dots. The two different start positions are indicated by stars of different colors (yellow and orange).
Conclusion
Arena-bench proves to be a valuable tool for benchmarking and developing navigation strategies in dynamic environments. The integration of DRL training capabilities and comprehensive evaluation metrics facilitates the cross-comparison of different navigation paradigms. Future work could expand real-world testing and further investigate the impact of robot kinematics on navigation performance. This benchmark suite is poised to drive advancements in the deployment of DRL-based navigation in mobile robotics.