Contrastive Learning as Goal-Conditioned Reinforcement Learning
Abstract: In reinforcement learning (RL), it is easier to solve a task if given a good representation. While deep RL should automatically acquire such good representations, prior work often finds that learning representations in an end-to-end fashion is unstable and instead equip RL algorithms with additional representation learning parts (e.g., auxiliary losses, data augmentation). How can we design RL algorithms that directly acquire good representations? In this paper, instead of adding representation learning parts to an existing RL algorithm, we show (contrastive) representation learning methods can be cast as RL algorithms in their own right. To do this, we build upon prior work and apply contrastive representation learning to action-labeled trajectories, in such a way that the (inner product of) learned representations exactly corresponds to a goal-conditioned value function. We use this idea to reinterpret a prior RL method as performing contrastive learning, and then use the idea to propose a much simpler method that achieves similar performance. Across a range of goal-conditioned RL tasks, we demonstrate that contrastive RL methods achieve higher success rates than prior non-contrastive methods, including in the offline RL setting. We also show that contrastive RL outperforms prior methods on image-based tasks, without using data augmentation or auxiliary objectives.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Contrastive Learning as Goal-Conditioned Reinforcement Learning — A Simple Explanation
What is this paper about?
The paper explores a new way to teach computers (or robots) how to reach goals by reusing a powerful idea from computer vision called contrastive learning. Instead of adding extra “representation learning” tricks to an existing reinforcement learning (RL) algorithm, the authors flip the script: they show that contrastive learning itself can act like an RL algorithm for goal-reaching tasks. Even better, they prove that what contrastive learning learns matches a core RL concept (a value function), and they show in experiments that this approach works really well.
What questions did the authors ask?
- Can we solve goal-reaching tasks using just contrastive learning, without extra reward shaping or fancy add-ons?
- Is there a precise link between contrastive learning (which learns to tell “things that go together” from “things that don’t”) and RL value functions (which tell you how good an action is for a goal)?
- Does this idea work better (and more simply) than common RL methods, especially on image-based tasks and in offline settings where you can’t collect new data?
How did they do it? (With simple analogies)
Think of a robot trying to reach a goal, like pushing a puck to a spot on a table.
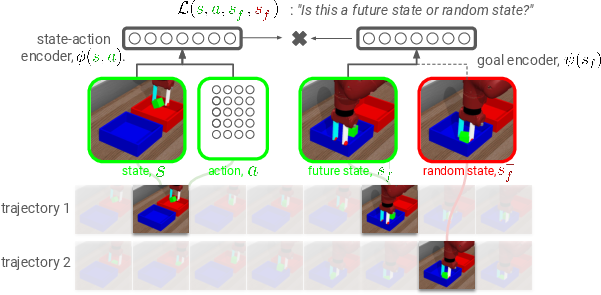
- Key idea: Learn two “embeddings” (compact summaries):
- One for “what I’m doing now”: a state-action pair, written as φ(s, a).
- One for “what I want”: a future or goal state, written as ψ(s_goal).
- Contrastive learning setup:
- Positive pairs: match a current state-action (what you do now) with a future state the robot actually reaches soon after. These are true matches.
- Negative pairs: match the same state-action with a random, unrelated state. These are false matches.
- Training goal: Make the embedding of the current choice φ(s, a) be “close” (high similarity, via a dot product) to the embedding of the correct future/goal ψ(s_goal), and far from random ones.
- Why this is like RL: The similarity score f(s, a, s_goal) = φ(s, a) * ψ(s_goal) ends up estimating “how likely this action will lead to that goal soon.” In RL terms, that’s a goal-conditioned Q-value (a measure of how good an action is for reaching a specific goal).
- Acting (choosing actions): To reach a goal, pick the action whose embedding is closest to the goal’s embedding. In other words, choose actions that make the desired future most likely.
In short, they turn “match the right pairs” into “take actions that will reach the goal,” and they prove the math that connects these two ideas.
Helpful definitions:
- Reinforcement Learning (RL): Learning by trying actions and seeing what works to get rewards.
- Goal-conditioned RL: The agent is given a target state (the “goal”) and learns to reach it.
- Contrastive learning: Learning to pull matching pairs together and push non-matching pairs apart.
- Representation/embedding: A compact vector that captures the important features of inputs.
- Q-function/value function: A score telling how good an action is for reaching a goal.
What methods did they compare?
They built a very simple version called Contrastive RL (NCE). They also looked at:
- A prior method (C-learning), which they show is actually a form of contrastive learning.
- Variants using different contrastive objectives (like CPC/infoNCE).
- A combined version (NCE + C-learning).
They compared against:
- HER (a popular goal-conditioned RL baseline with actor-critic learning).
- GCBC (goal-conditioned behavioral cloning: imitate actions that led to goals).
- Model-based methods that predict future states.
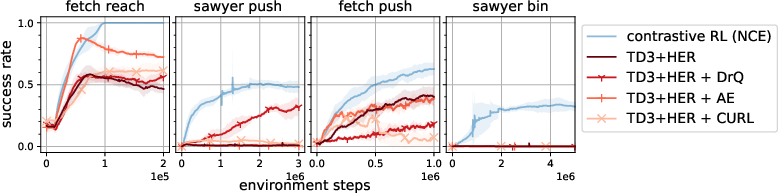
- Image-focused add-ons like DrQ (data augmentation), autoencoders (AE), and CURL (contrastive features from augmented images).
They tested on:
- Robot tasks (reach/push with a robotic arm), both with low-dimensional states and with images.
- Navigation tasks (mazes).
- Offline RL benchmarks (AntMaze), where the agent cannot collect new data.
- A harder camera setup with a moving, first-person view (partial observability).
What did they find, and why is it important?
- Contrastive RL often outperformed the traditional methods on both state and image tasks, sometimes by a lot, especially on harder tasks (like moving objects across bins).
- It worked well on images without any special image tricks (no data augmentation or extra losses), while actor-critic baselines needed those tricks and still didn’t match its performance.
- The simplest version (NCE) is already strong and easy to implement. A combined version (NCE + C-learning) was often the best overall.
- It handled moving-camera, first-person views reasonably well, despite partial observability.
- In offline RL (AntMaze), Contrastive RL + a bit of behavior cloning beat many baselines on 5 out of 6 tasks, including some that are hard for standard TD-learning methods.
Why this matters:
- Simpler training: You don’t need to bolt on extra representation learning parts or image augmentations; the learning objective doubles as both representation learning and RL.
- Strong performance with images: Good news for real robots that see the world through cameras.
- Theory + practice: They don’t just claim it works; they prove the similarity score is a value function (up to a constant) and give conditions for policy improvement.
What could this change in the future?
- A cleaner way to build goal-reaching agents: one objective that learns both understanding (representations) and doing (actions) at the same time.
- Better robotics: agents can learn from their own experience, camera views, and even offline datasets without carefully crafted rewards or image tricks.
- A unifying view: Representation learning and RL don’t have to be separate steps; contrastive learning can directly drive decision-making.
Overall, the paper shows that contrastive learning isn’t just for making good features—it can directly power goal-conditioned reinforcement learning, often more simply and effectively than the usual approaches.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves missing, uncertain, or unexplored, phrased to be directly actionable for future work:
- Theory beyond tabular and Bayes-optimal critics: Convergence and policy-improvement guarantees rely on tabular state-action spaces, a Bayes-optimal critic, and an auxiliary filtering step that is not used in practice. It remains open to establish guarantees under function approximation, stochastic optimization, and without filtering.
- Policy mismatch in the learned critic: The core result links the critic to Q for the averaged goal-conditioned policy π(·|·) rather than per-goal π(·|·, s_g). Quantify and mitigate the impact of this mismatch on control, and develop estimators that recover per-goal Q without sacrificing sample efficiency.
- Dependency on discounted state occupancy sampling: Positive pairs must be drawn from the discounted occupancy p{π}(s_{t+}|s,a), but in practice data are off-policy and mixed across policies. Characterize the bias introduced by this approximation and propose corrected sampling or importance weighting schemes.
- Role and estimation of p(s_g): The optimal critic is log Q − log p(s_g). The method ignores or absorbs the −log p(s_g) term at action selection. Analyze the effect of non-uniform goal marginals on policy learning and explore ways to estimate or compensate for p(s_g) in high-dimensional spaces.
- Generality beyond the next-step reachability reward: The analysis hinges on the goal-conditioned reward r_g(s,a) = (1−γ) p(s_{t+1}=s_g|s,a). Determine whether and how the framework extends to other goal-reaching rewards (e.g., sparse indicators, terminal-only success, staying vs just hitting), shaped rewards, or non-reachability objectives.
- Variance and horizon scaling for Monte Carlo learning: The method is Monte Carlo–style with geometric time sampling. Provide a variance analysis, investigate γ sensitivity, and develop variance-reduction strategies for long-horizon, sparse-reachability settings.
- Stability without target networks: The approach eschews target networks and TD-style bootstrapping. Identify failure modes (e.g., overfitting, drift under replay) and study stabilizers (target encoders, momentum, Polyak averaging).
- Negative sampling pitfalls and false negatives: In-batch negatives can include states that are reachable or semantically similar, causing representation conflicts. Explore hard-negative mining, temporal windows, distance-based masks, or curriculum negatives to reduce false-negative harm.
- Temperature and calibration in NCE/BCE: The critic uses a logistic link without temperature tuning. Assess whether temperature scaling, logits normalization, or margin-based losses improve performance and calibration of Q estimates.
- Expressivity limits of inner-product critics: The bilinear form f(s,a,s_g)=φ(s,a)T ψ(s_g) may be too restrictive for complex dynamics. Evaluate more expressive critics (e.g., MLP over concatenated embeddings, attention, hypernetworks) and study their impact on control and representation quality.
- Representation ablations: There is no systematic study of embedding dimensionality, batch size, encoder architecture, or shared vs separate encoders for φ and ψ. Provide ablations to quantify their effects on learning stability and sample efficiency.
- Combining with augmentations and auxiliary objectives: While the method outperforms baselines that use augmentation/auxiliary losses, it remains unknown whether judicious augmentations (e.g., color jitter, random crops) or self-supervised regularizers synergize with contrastive RL.
- Partial observability and memory: The method succeeds moderately with a moving camera but does not incorporate recurrent policies or history encoders. Evaluate recurrent/transformer architectures, belief-state learning, and goal-conditioned memory for POMDPs.
- Exploration and goal sampling: The work treats exploration and automatic goal selection as orthogonal. Integrate goal curricula, novelty-driven sampling, or coverage objectives and quantify gains on hard-exploration tasks (e.g., Sawyer bin remains <50% success).
- Off-policy theory and replay usage: The algorithm is practically off-policy but theoretically on-policy. Develop off-policy corrections (e.g., importance sampling, conservative critics) and characterize how replay buffer composition and policy lag affect learning.
- Scaling to high-dimensional visual goals: Pairwise logits incur O(B2) compute/memory. Investigate scalable negative pools, approximate nearest neighbor negatives, memory banks, or sub-quadratic contrastive estimators to handle large images and bigger batches.
- Generalization to unseen goals: Goals are sampled from replay. Measure and improve generalization to goals outside the training occupancy (e.g., extrapolation to far or unseen regions), including evaluation on held-out goal sets.
- Robustness to stochastic, irreversible, or time-varying dynamics: Analyze how stochastic transitions, irreversible actions, and non-stationary environments affect occupancy-based critics and propose robust training modifications.
- Discrete or hybrid action spaces: The actor update assumes reparameterizable continuous actions. Develop and test counterparts for discrete/hybrid actions (e.g., Gumbel-softmax, categorical policy gradients) and study their efficacy.
- Real-world deployment and sensing realism: No real-robot results or domain randomization tests are reported. Evaluate on hardware with delays, sensor noise, and dynamic backgrounds; assess sim-to-real transfer and robustness requirements.
- Comparison breadth and fairness: Some baselines (e.g., stronger image-based GCRL methods, modern contrastive RL with momentum encoders, recent UVFA variants) are not included. Expand comparisons and ensure matched compute/augmentation budgets.
- Offline RL sensitivity and scope: Offline results use AntMaze; the sensitivity to λ (BC weight), number of critics, dataset quality/coverage, and goal relabeling strategies is not analyzed. Extend to diverse datasets (e.g., image-based, robotic manipulation) and characterize failure regimes.
- Hindsight relabeling strategy design: The method relabels with future states but does not explore alternative relabeling distributions (e.g., time-distance weighting, prioritized successful outcomes). Study how relabeling choices influence learning.
- Success metric vs “stay at goal” behavior: The occupancy objective encourages reaching and staying, while many tasks count single-time success. Examine alignment/misalignment between this objective and task success criteria and adapt the objective when needed.
- Transfer and compositionality of learned representations: It is unclear whether φ and ψ transfer across tasks, goals, or reward families (e.g., successor-feature-style transfer). Investigate zero/few-shot goal composition and transfer learning.
- Safety and constraints: The framework optimizes goal reachability without explicit constraints. Explore integration with constrained RL or cost-aware contrastive objectives for safe goal-reaching.
- Hyperparameter selection guidelines: Practical guidance for γ, entropy regularization, batch size, negative ratio, and learning rates is limited. Provide principled selection heuristics or adaptive schemes grounded in theory or diagnostics.
Collections
Sign up for free to add this paper to one or more collections.