- The paper introduces VUVC, a novel framework that uses value uncertainty to generate curricula for efficient unsupervised skill discovery.
- It unifies MI-based approaches by reformulating goal-conditioning as variational empowerment under a dynamic curriculum.
- Empirical results show enhanced state space coverage and faster skill acquisition across simulated and real-world tasks compared to existing baselines.
Variational Curriculum Reinforcement Learning for Unsupervised Discovery of Skills
Introduction and Motivation
The paper "Variational Curriculum Reinforcement Learning for Unsupervised Discovery of Skills" (2310.19424) presents a unified perspective on information-theoretic, mutual information (MI)-based skill discovery in unsupervised reinforcement learning (RL). The authors argue that the order of skill acquisition (i.e., curriculum) fundamentally impacts sample efficiency when learning complex behaviors without external reward functions. The work introduces the Variational Curriculum Reinforcement Learning (VCRL) framework, which recasts traditional MI-based unsupervised RL approaches as a form of curriculum generation in goal-conditioned environments. Under this framework, the authors formulate the Value Uncertainty Variational Curriculum (VUVC), which uses value function uncertainty to autonomously generate curricula that accelerate state space coverage.
Variational Curriculum RL (VCRL) Unification
VCRL aims to generalize existing MI-based RL paradigms by formalizing the goal-conditioning process as variational empowerment under a curriculum goal distribution p(g). VCRL encapsulates several previous skill discovery techniques (e.g., DIAYN, Skew-Fit, RIG, EDL) by varying the choices of discriminative models and the generative mechanisms for curriculum goal sampling. Notably, VCRL treats the curriculum as a non-stationary process, adjusting the distribution of goals over the course of learning to maximize the diversity of reachable states.
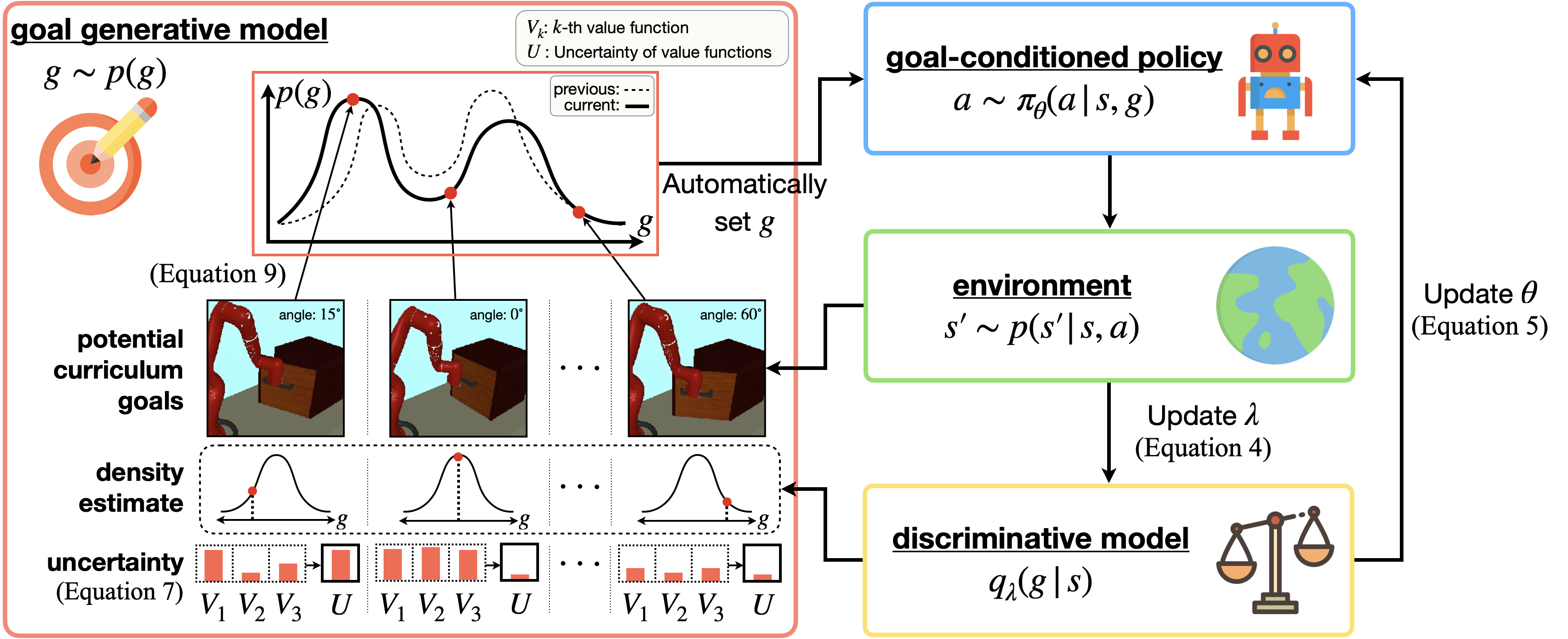
Figure 1: The VUVC approach under the VCRL framework, combining value uncertainty and density estimation to generate informative curriculum goals, thereby promoting efficient coverage of the state space.
The VUVC approach is built on the insight that maximizing the uncertainty (variance) in value function predictions, as estimated by an ensemble, serves as a proxy for maximizing mutual information between goals and visited states. Theoretical analysis demonstrates that, under regularity conditions, sampling goals proportional to value function uncertainty and state novelty (via density estimation) leads to a more rapid increase in the entropy of the visited state distribution than sampling from a uniform curriculum.
Theoretical Justifications for VUVC
The main theoretical contribution is the derivation of optimal curriculum construction from a value uncertainty perspective. The authors show that in discrete state spaces, selecting goals based on value uncertainty—when the uncertainty is negatively correlated with the state visitation frequency—provably increases the entropy of visited states more rapidly than uniform curriculum methods such as Skew-Fit. The analysis holds under both optimal and suboptimal goal-conditioned policies, leveraging ensemble-based variance as a lower bound on the entropy of value function predictions.
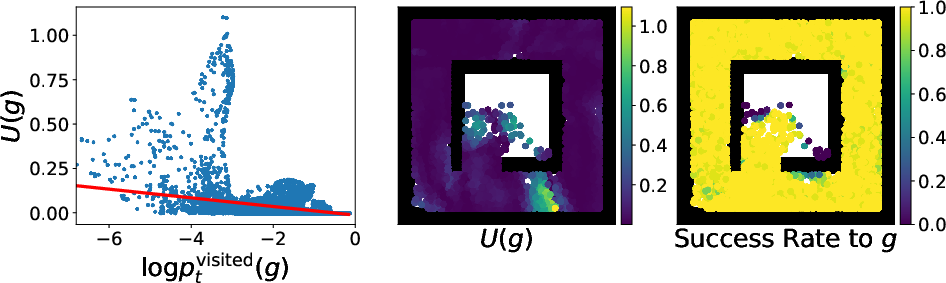
Figure 3: Relationship between value uncertainty and log-density of visited states, evidencing negative correlation and supporting the theoretical framework.
The paper further asserts, and empirically validates, that VUVC naturally filters out uninformative or unreachable goals, focusing the learning process on regions of the state space that yield maximum utility for skill acquisition.
Experimental Evaluation
Benchmark Environments
Empirical validation spans a diverse suite of simulated and real-world environments, including point maze navigation, configuration-based and vision-based robot manipulation tasks, and large-scale real robot navigation. The environments vary in observation modality (state-based and image-based), complexity, and required exploration.
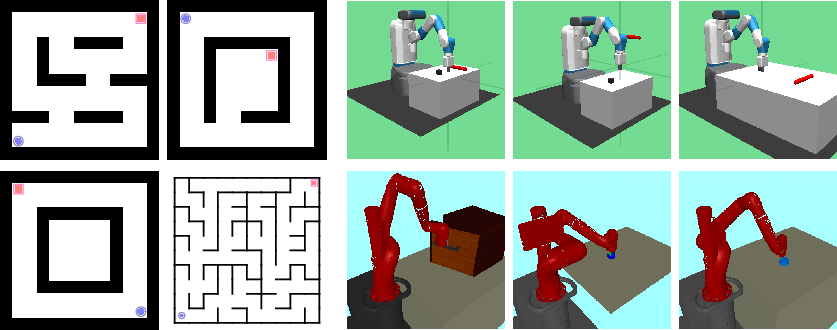
Figure 4: Simulated environments: Point maze tasks, configuration-based Fetch tasks, and vision-based Sawyer manipulation environments.
Quantitative Results
The results indicate consistent outperformance of VUVC over prior curriculum and unsupervised RL baselines across all tested domains. Learning curves (success rates and sample efficiency) highlight faster and more complete state space coverage compared to baselines such as HER, GoalGAN, RIG, Skew-Fit, DIAYN, and EDL—despite several of these baselines leveraging oracle assumptions or additional exploration phases.
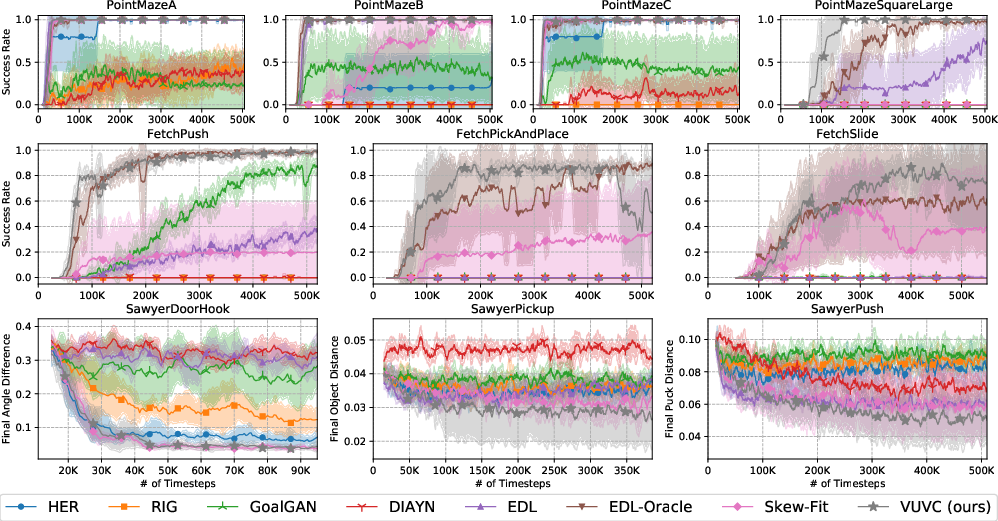
Figure 2: VUVC achieves significantly better sample efficiency and final performance across point maze navigation, robot control, and vision-based manipulation.
Qualitative State Space Coverage
Visualization of curriculum goal distributions and accumulated visited states demonstrates accelerated and more uniform coverage of the reachable state space by VUVC agents relative to baselines.
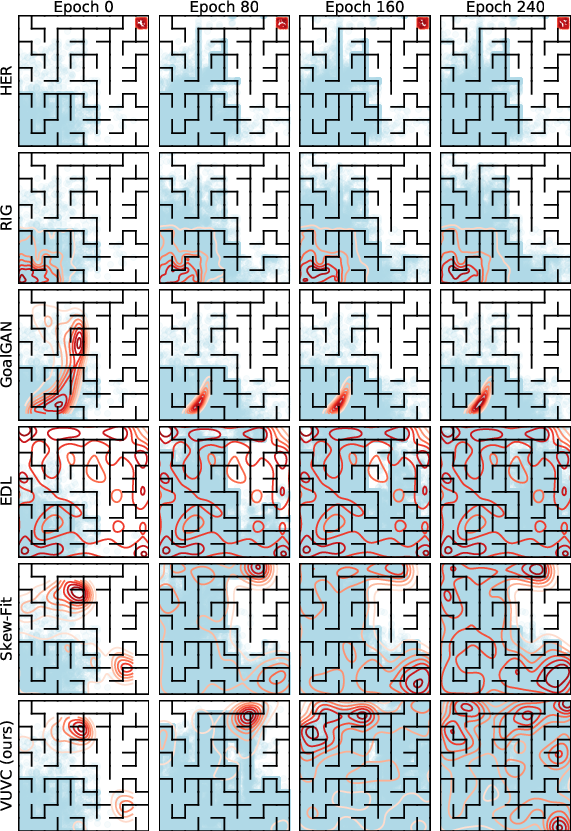
Figure 5: VUVC’s curriculum goal distribution (red contours) and trajectory coverage (cyan dots) facilitate complete state space exploration far more efficiently than competing methods.
Real Robot Deployment
The VUVC-discovered skills are deployed in a real-world, building-scale navigation scenario using the Husky A200 mobile robot. In a zero-shot setup, the agent is able to reach long-range goals solely with skills acquired in simulation—without task-specific reward engineering. Integrating global planning with VUVC skills further enhances long-range navigation capability and reduces traversal time, illustrating effective transfer and compositionality of the learned skills.
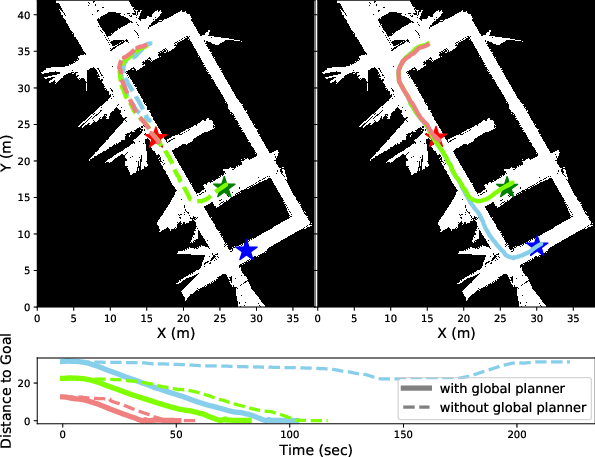
Figure 7: Evaluation in a building-scale navigation scenario, showing improved goal-reaching and reduced time with global planner integration.

Figure 6: In simulation, VUVC rapidly expands state space coverage for a mobile robot navigation task via laser sensor input.
Ablations and Additional Insights
Ablation studies indicate insensitivity of VUVC’s performance to ensemble size in uncertainty estimation, supporting robustness of the technique. Further analysis of the value uncertainty landscape validates that uncertainty is elevated in moderately reachable, informative goal regions—thereby biasing curricular sampling toward maximally beneficial learning experiences.
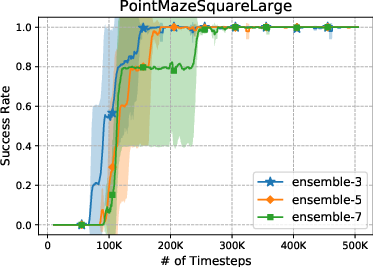
Figure 9: VUVC’s performance is robust to changes in ensemble size for uncertainty estimation.
Implications and Future Directions
This work demonstrates that autonomous curriculum generation predicated on value function uncertainty can dramatically enhance both the efficiency and completeness of unsupervised skill acquisition in high-dimensional RL settings. VUVC’s integration of information-theoretically grounded exploration with density-based novelty and goal-conditioning extends the practical capabilities of unsupervised RL to real-world, long-horizon robotic applications without reward engineering.
Theoretical results motivate further research into:
- Rigorous characterization of the regularity conditions for the entropy increment guarantees in broader classes of MDPs
- Extension to variable initial state distributions and non-stationary environments
- Integration with hierarchical RL and more complex world models for skill compositionality and re-use
- Deployment in increasingly unstructured real-world domains, potentially leveraging richer sensor modalities
Conclusion
The VCRL framework and its instantiation as VUVC represent a formal unification and principled advance in unsupervised RL, providing strong empirical and theoretical evidence for the efficacy of value uncertainty-driven curricula. By promoting rapid, efficient, and robust state space coverage, VUVC establishes a new standard for skill discovery without supervision, and opens new avenues for scalable autonomous learning in complex, reward-sparse settings.