- The paper introduces AST-Probe to determine if pre-trained models encode full syntactic structures by projecting token embeddings onto a syntactic subspace.
- The methodology employs an orthogonal projection to isolate AST-related features, achieving high precision in recovering syntax trees across several programming languages.
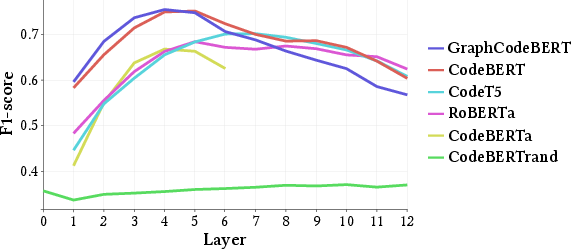
- Experimental results reveal that models like GraphCodeBERT and CodeBERT capture syntactic features primarily in middle layers, with optimal subspace dimensions between 64 and 128.
AST-Probe: Recovering Abstract Syntax Trees from Hidden Representations of Pre-trained LLMs
The paper "AST-Probe: Recovering Abstract Syntax Trees from Hidden Representations of Pre-trained LLMs" proposes a novel method to determine whether pre-trained LLMs for programming languages encode the entire syntactic structure of code in their hidden representations. This involves probing these models to extract the Abstract Syntax Trees (ASTs) associated with code snippets. The authors introduce the AST-Probe, which aims to identify a syntactic subspace within model representations and utilize this discovery to fully recover ASTs from embedded code data.
Introduction
The application of NLP techniques to source code analysis has led to significant improvements in automating various tasks such as code completion, search, and summarization. Pre-trained LLMs like BERT, GPT, CodeBERT, and others have facilitated these advancements by learning to represent source code meaningfully. Despite these successes, there is still a lack of understanding regarding the specific syntactic properties these models capture.
AST-Probe is introduced to bridge this gap by assessing whether a syntactic subspace exists within the latent spaces of these models that can encapsulate the full grammatical structure of programming languages. This would imply the models are not only capturing linguistic nuances but also complex syntax relevant to ASTs.
The AST-Probe Approach
The AST-Probe methodology involves projecting token embeddings derived from LLMs onto a lower-dimensional space, hypothesized to contain syntactic structures. After projection, a reconstructed AST is generated from these embeddings. The methodology revolves around the following components:
Syntactic Subspace Identification
- Projection Mechanism: Define an orthogonal projection from the model’s representation space to a hypothesized syntactic subspace S. The vectors in this subspace are expected to retain AST information.
- Vector Transformation: Token embeddings undergo transformation via this projection, effectively isolating the syntactic features.
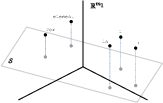
Figure 1: Visualization of the projection. The dotted blue lines represent the projection PS.
AST Recovery
From the syntactic subspace vectors, AST-Probe seeks to reconstruct the AST using geometric properties and learned vector relationships.
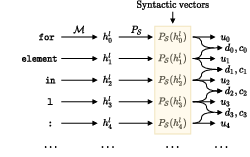
Figure 2: Overview of the AST-Probe. The syntactic vectors are obtained using the projection PS.
Experimental Setup
The evaluation was conducted on five state-of-the-art LLMs: CodeBERT, GraphCodeBERT, CodeT5, CodeBERTa, and RoBERTa, covering Python, JavaScript, and Go languages. Key metrics involved precision, recall, and F1-score in recovering ASTs:
Discussion and Implications
The study presents a comprehensive approach to probe into and visualize the syntactic comprehension of programming language within pre-trained models. The findings suggest that state-of-the-art models effectively encode meaningful AST-related syntactic information, which is compactly stored.
These insights have implications beyond pure academic interest, as understanding the inner workings of these models can inform better design and fine-tuning strategies for niche applications in automated code analysis and generation. Furthermore, the potential correlation of syntactic understanding with task performance merits exploration.
Conclusion
AST-Probe provides a sophisticated framework to quantitatively analyze the syntactic understanding within pre-trained LLMs’ hidden layers. Future research could explore expanding the diversity of models and languages probed, assessing correlations with model performance on functional tasks, and exploring how fine-tuning impacts syntactic capacity retention.
The innovation demonstrated by AST-Probe suggests promising directions for further study into the interpretability and optimization of LLMs in software engineering contexts.