- The paper introduces system enhancements that integrate long context, multi-speaker data, and BERT word embeddings to achieve coherent prosody in multi-sentence TTS.
- The methodology augments phoneme encodings with speaker embeddings and contextual word representations, mitigating overfitting and enhancing syntax-driven prosody.
- Evaluations using subjective and objective metrics reveal significant improvements in naturalness and accurate inter-sentence pause handling.
Overview of "Simple and Effective Multi-sentence TTS with Expressive and Coherent Prosody"
The study explores multifaceted extensions to a Transformer-based FastSpeech-like Text-to-Speech (TTS) system to enhance the prosody for multi-sentence inputs. It investigates how incorporating long context, rich contextual word embeddings, and multi-speaker data can synergistically impact both the coherence and expressiveness of prosodic delivery in TTS systems.
System Extensions and Methodology
Baseline System
The baseline system is built upon a Transformer-based FastSpeech-like structure featuring an acoustic model and a duration model. The architecture leverages Feed-Forward Transformer (FFT) blocks for generating speech by predicting both phoneme durations and corresponding mel-spectrograms.
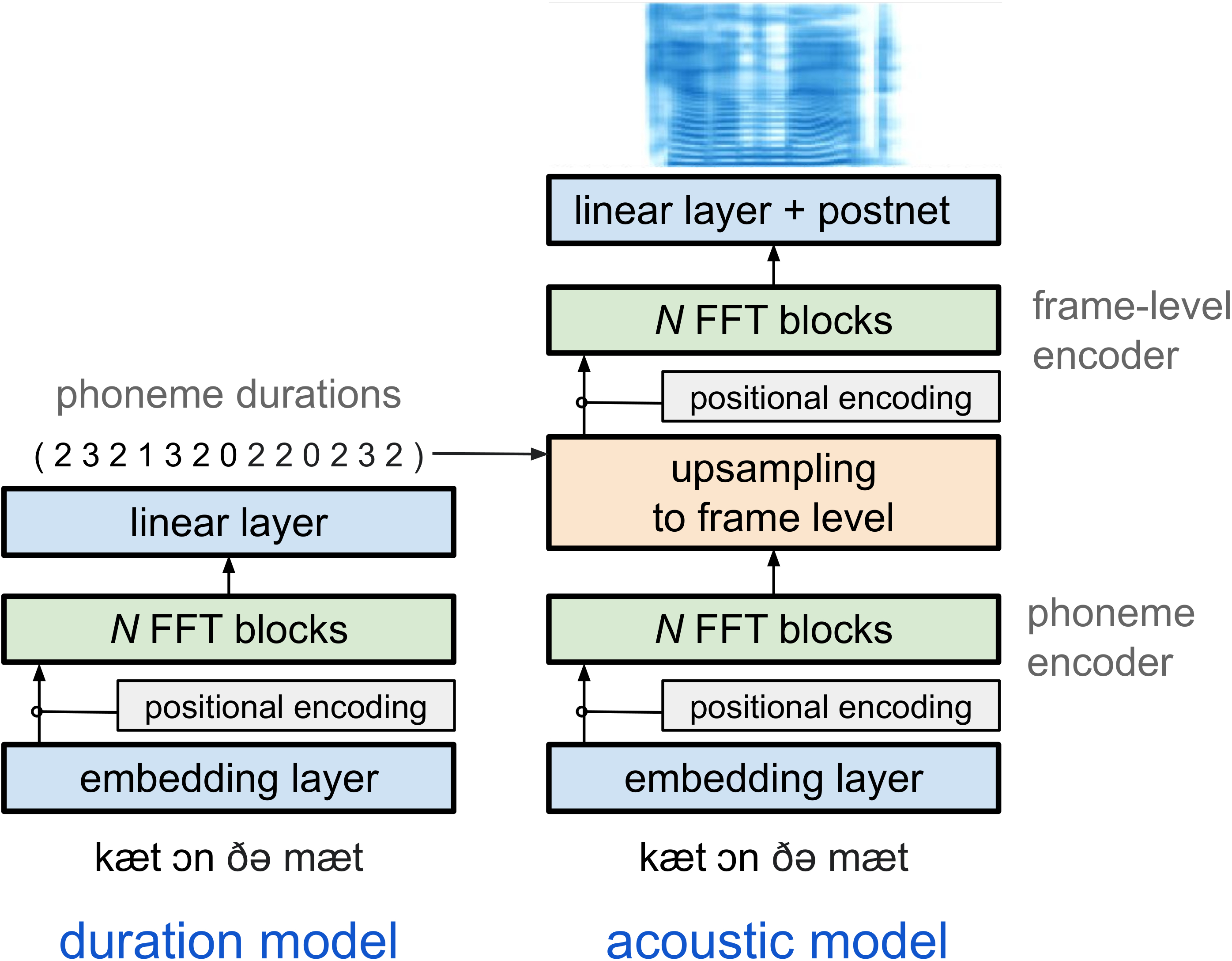
Figure 1: FastSpeech-like Transformer baseline.
Extension 1: Multi-Speaker Modeling
The integration of multi-speaker data aims to facilitate transfer learning. This is achieved by augmenting phoneme encodings with speaker embeddings, effectively reducing overfitting risks prevalent with limited single-speaker data availability. The embeddings are extracted from a pre-trained speaker verification model.
Extension 2: BERT Word Embeddings
Leveraging contextual syntactic information, BERT word embeddings are appended to phoneme encodings to enhance syntax-driven prosody modulation. These embeddings are dynamically aligned and upsampled in a manner designed to optimize input structure coherence.
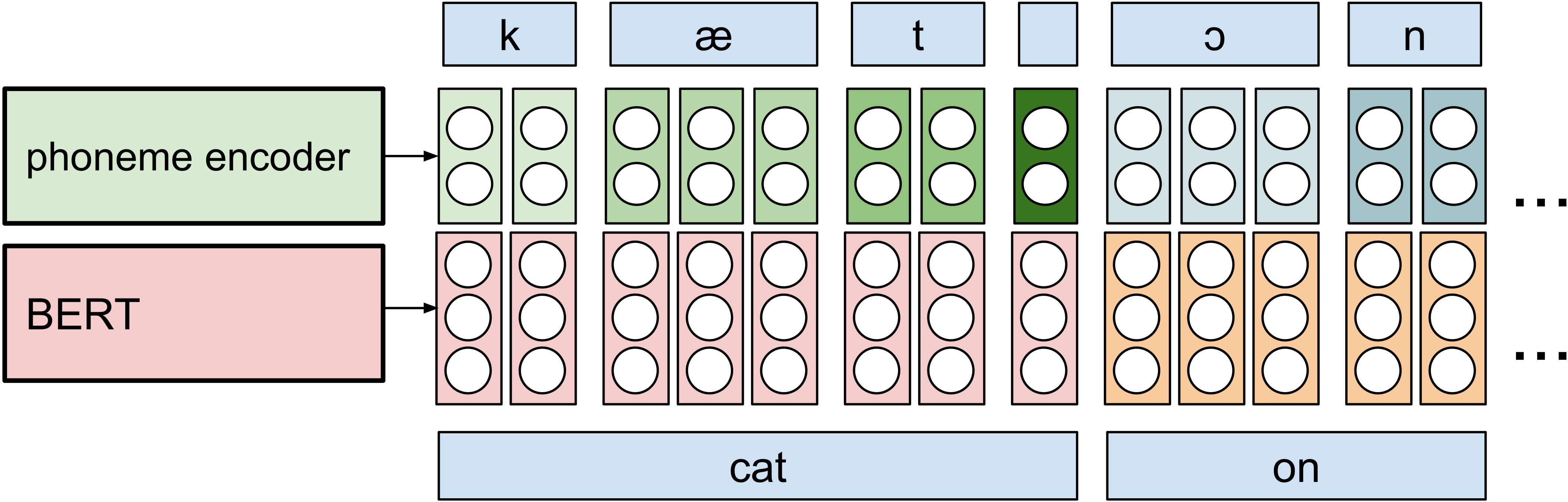
Figure 2: Alignment and upsampling of phoneme encodings and BERT word embeddings in Transformer-BERT.
Extension 3: Long Context Incorporation
To mitigate coherence loss across sentence boundaries, the system processes concatenated multi-sentence inputs, thus retaining contextual dependencies. This encapsulation of extended textual input mitigates the propensity towards prosodic disruption by delineating broader semantic nuances.
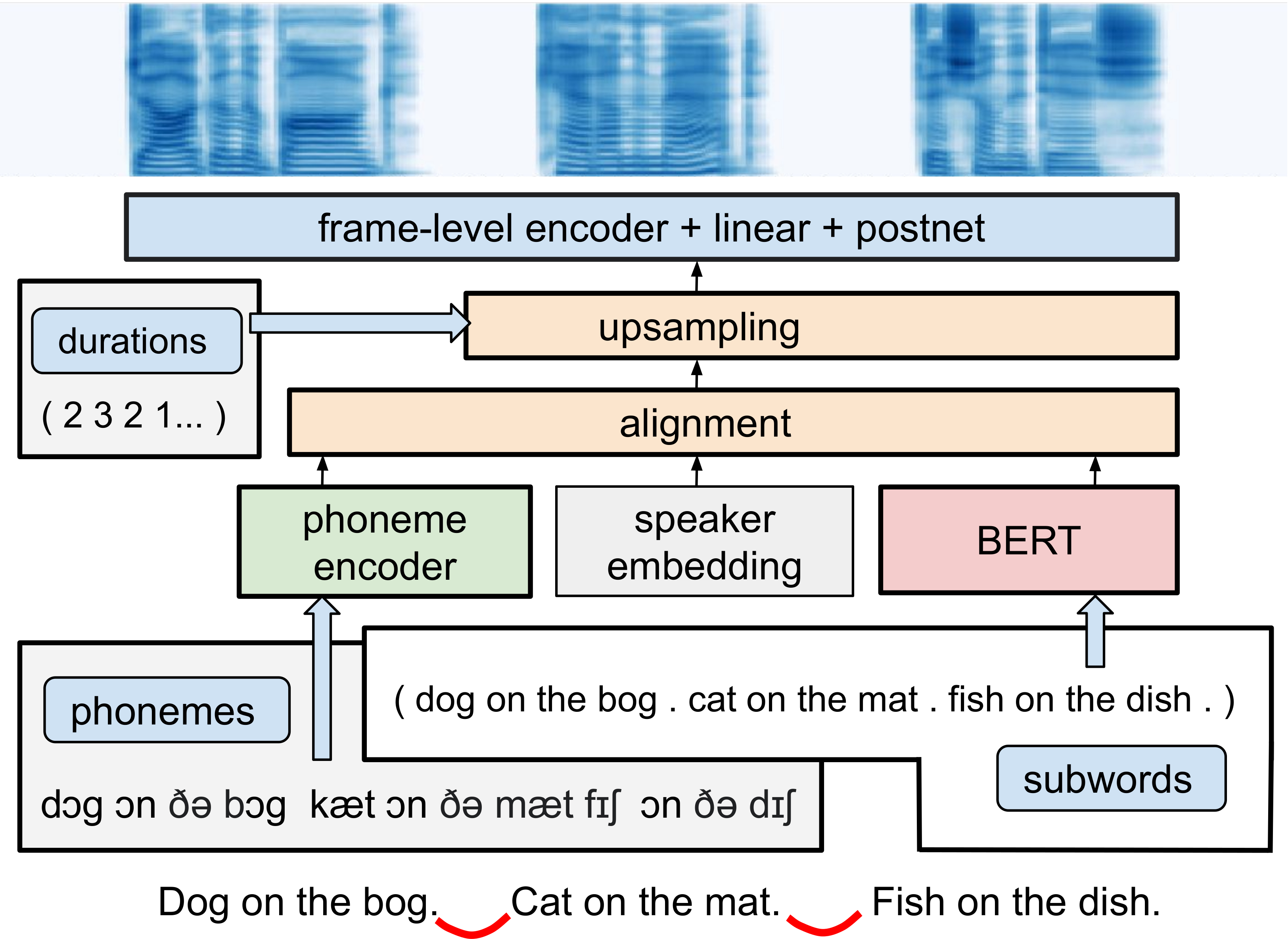
Figure 3: Multi-speaker long-context Transformer-BERT.
Subjective and Objective Metrics
Evaluation on internal datasets highlighted statistically significant improvements in naturalness via MUSHRA testing when multi-speaker and contextual embeddings were employed. The integration of long context catalyzed remarkable enhancements in prosody consistency, particularly evident in inter-sentence pause handling, with the optimized model closely mirroring manual benchmarks.
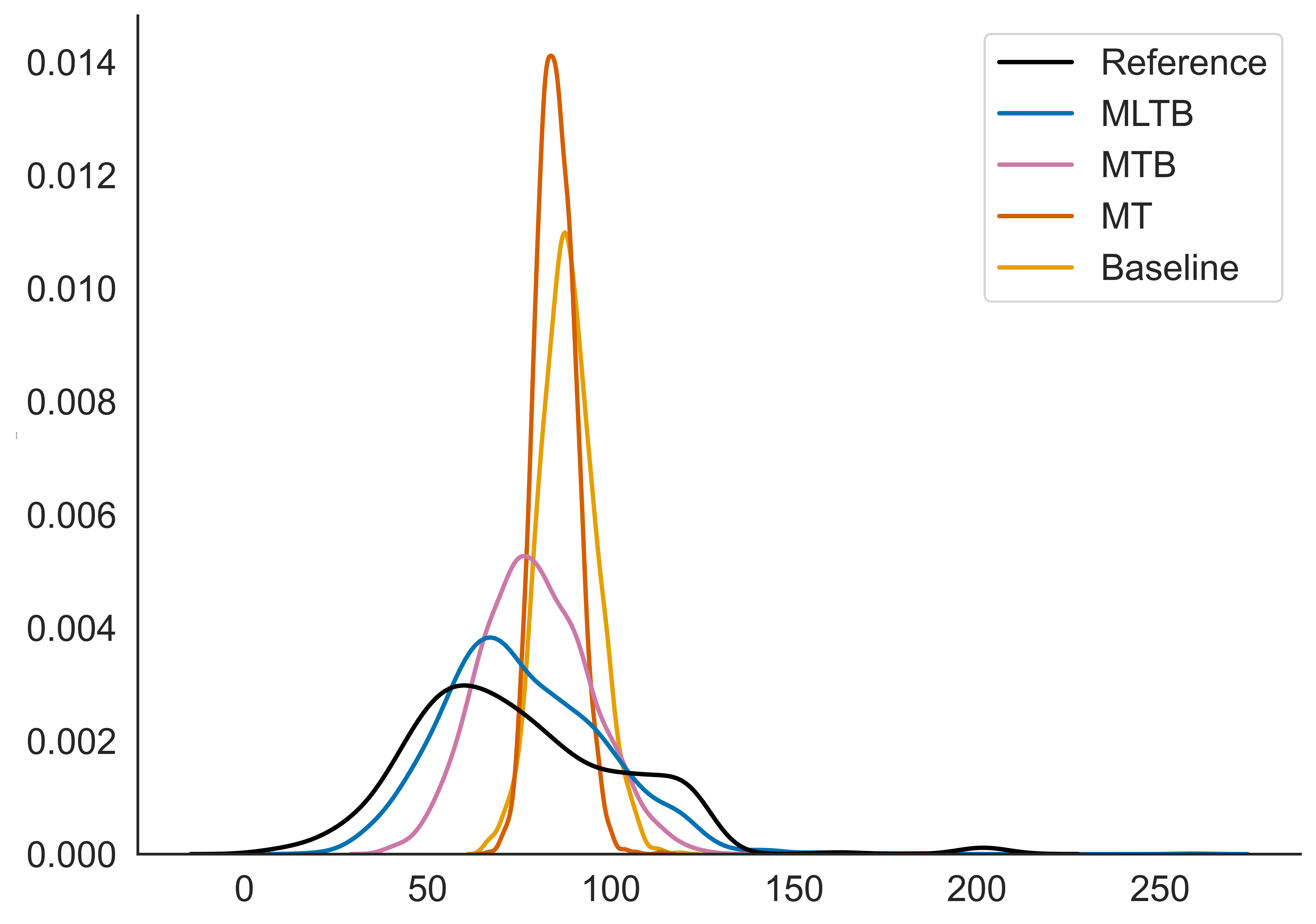
Figure 4: Distribution of inter-sentence pauses in frames.
Key performance metrics showcased improvements in mean squared error (MSE) and coefficient of determination (R2) for phoneme duration predictions, underscoring the refined granularity of prosodic delivery with extended context utilization.
Implications and Future Prospects
The findings demonstrate that aggregative utilization of long context, multi-speaker environments, and sophisticated linguistic embeddings can address inherent limitations of single-sentence TTS models, particularly for applications demanding nuanced prosody such as audiobooks and conversational agents. Future work could explore deeper integration with other NLP advancements to further enhance TTS system robustness and flexibility across varied linguistic landscapes.
Conclusion
This paper validates the applicability and efficacy of straightforward system enhancements to refine prosodic expressiveness and coherence in multi-sentence TTS deployments. By leveraging synergies among long-context incorporation, contextual embeddings, and multi-speaker training, it sets a foundational precedent for future explorations aimed at optimizing AI-driven speech generation at scale.