- The paper introduces vision transformer-based models employing spatiotemporal attention to detect distracted and drowsy driving.
- It utilizes the Video Swin Transformer and benchmark datasets (NTHU-DDD, DMD) to evaluate performance, achieving 97.5% accuracy in distraction detection.
- The study highlights overfitting challenges in drowsiness detection while emphasizing the potential of transformer models for enhancing automotive safety.
Introduction
The application of computer vision techniques in the automotive industry, specifically for detecting distracted and drowsy driving, is explored through the deployment of vision transformers. In response to the increasing rate of traffic accidents involving distracted or drowsy drivers—comprising 45% of car crashes—this study proposes the utilization of vision transformers as a low-cost, accurate, and minimally invasive detection mechanism. Previous methods employing EEGs, alcohol monitors, and lane detection systems are critiqued for being costly and impractical for comprehensive detection across various unfit driving categories. Vision transformers, as introduced in recent literature, hold significant promise for addressing these challenges by leveraging sophisticated attention mechanisms and adaptable processing architectures.
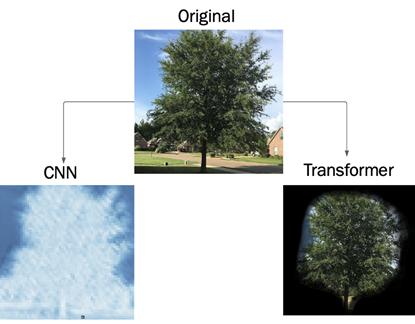
Figure 1: Difference in processing methods for convolutional neural networks and transformers. CNNs extract edges while the transformer extracts the most important spatial information from the input data.
Methodology
The study investigates two distinct scenarios using video-based classification models: drowsiness detection and distraction recognition. Utilizing the Video Swin Transformer architecture, known for its advanced handling of spatiotemporal data through shifted windows and tubelet embeddings, the research employs datasets NTHU-DDD and DMD for model training and evaluation.
Drowsy Driving Detection
For detecting drowsiness, the Video Swin Transformer processes video sequences from the National Tsing Hua University Drowsy Driving Dataset (NTHU-DDD). The data undergoes preprocessing stages including dimensionality reduction via CNN-based feature maps and encoding through transformer layers to capture per-pixel details. The model is trained over 10 epochs on a Tesla K80 GPU, striving for an optimal balance between computational efficiency and prediction accuracy.
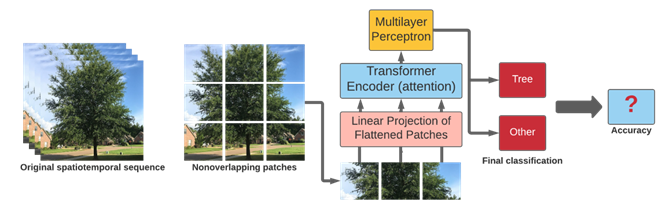
Figure 2: Illustration of the vision transformer architecture adapted from \cite{Dosovitskiy2021}, inferencing on spatiotemporal data to output a prediction of drowsy/alert.
Distracted Driving Detection
In the distraction recognition scenario, the Driver Monitoring Dataset (DMD) serves as the benchmark, embodying nine classes related to driver distractions. The Video Swin Transformer utilizes a comprehensive patch extraction method, forming embeddings through overlapping spatial-temporal windows. This setup considers higher GFLOPs, accommodating the architecture's complexity and higher data fidelity requirements. Model training on a Tesla T4 GPU underscores the computational demands while delivering superior accuracy.
Results
The experiments reveal distinct outcomes for the two scenarios tested. The drowsy driving transformer struggled to surpass existing CNN approaches on NTHU-DDD, achieving only 44% accuracy—indicative of overfitting and insufficient data representation (exemplified by high loss values).
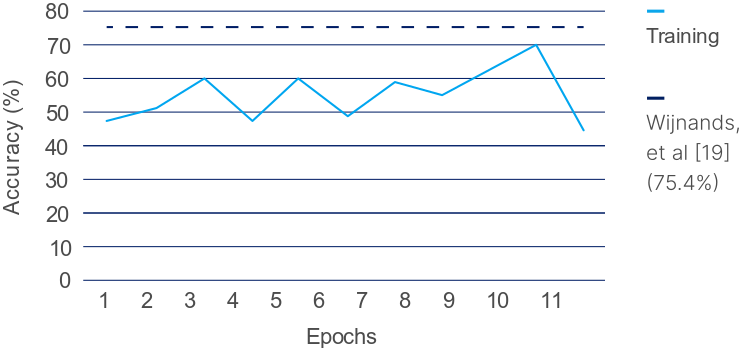
Figure 3: Training accuracy of the vision transformer on NTHU-DDD compared to the previous state-of-the-art with a CNN-based architecture.
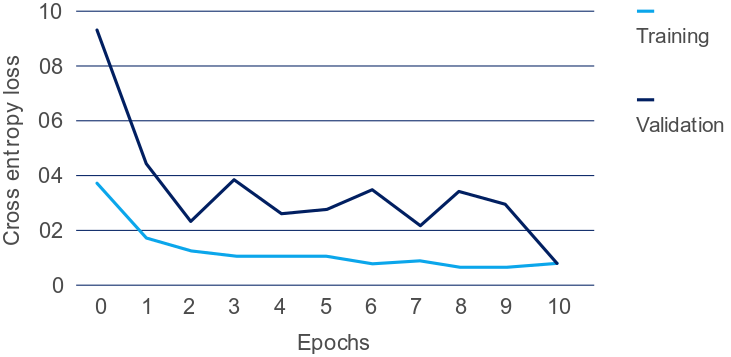
Figure 4: Training and validation cross-entropy loss over 10 epochs for detecting drowsy driving on NTHU-DDD with Video Swin Transformer.
Conversely, for distracted driving detection on DMD, the Video Swin Transformer achieved a notable 97.5% accuracy, a marginal yet significant improvement over the prior state-of-the-art results, confirming the model's adequacy for distraction-related categorizations.
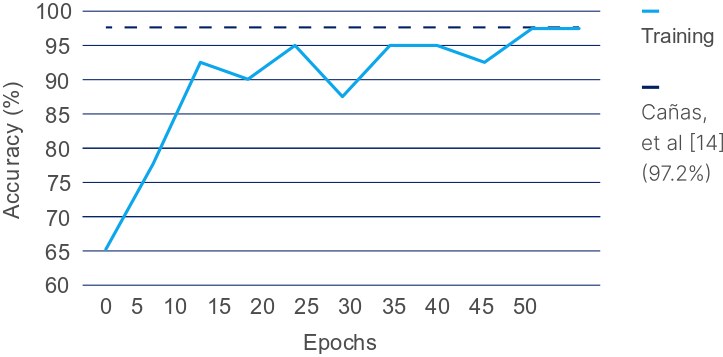
Figure 5: Training accuracy of the Video Swin Transformer on DMD compared to the previous state-of-the-art \cite{canas_dmd}.
Conclusion
This study presents an initial exploration into deploying vision transformers for detecting various forms of unfit driving, with promising outcomes particularly for distraction recognition. The capability of vision transformers to outperform traditional CNN methods in certain contexts underscores their potential in automotive safety systems. Nonetheless, challenges remain in extending such success across all categories of unfit driving, particularly for drowsiness detection. Future work should focus on enriching datasets, incorporating newer transformer variants like TokenLearner, and integrating models into scalable real-world solutions, including mobile device deployments. As automation and driver monitoring systems advance, these techniques may substantially impact automotive safety measures and legal requirements mandating driver monitoring systems.