- The paper introduces FAB, which employs annealed importance sampling with α-divergence (α=2) minimization to reduce importance weight variance.
- FAB uses a prioritized replay buffer to efficiently reuse AIS samples, reducing the need for costly MCMC evaluations.
- FAB outperforms competing methods on tasks like 2D Gaussian mixtures and alanine dipeptide, accurately approximating multimodal target distributions.
Flow Annealed Importance Sampling Bootstrap: A Detailed Summary
This paper introduces Flow Annealed Importance Sampling Bootstrap (FAB), a novel method for training normalizing flows to approximate complex, multimodal target distributions. FAB addresses limitations in existing approaches, such as mode-seeking behavior, reliance on expensive MCMC samples, and high variance stochastic losses. The method leverages annealed importance sampling (AIS) and minimizes the mass-covering α-divergence with α=2, which is shown to minimize importance weight variance.
Key Contributions
- α-Divergence Minimization with AIS: FAB uses the α-divergence with α=2 as its training objective. This choice encourages mass-covering behavior and reduces variance when importance sampling is used to correct for bias. The method employs AIS with the flow as the initial distribution and p2/q as the target, where p is the target distribution and q is the flow.
- Replay Buffer for Sample Re-use: To reduce computational costs, FAB introduces a prioritized replay buffer that re-uses AIS samples during flow updates. This buffer allows the method to efficiently learn from past samples, improving the stability and speed of training.
- Demonstrated Performance on Challenging Problems: FAB is evaluated on a 2D Gaussian mixture model, the 32-dimensional "Many Well" problem, and the Boltzmann distribution of alanine dipeptide. The method outperforms competing approaches, demonstrating its ability to accurately approximate complex, multimodal targets without relying on samples from those distributions.
Methodological Details
Normalizing Flows and the α-Divergence
Normalizing flows use invertible transformations to map a simple base distribution to a complex target distribution. The α-divergence, defined as:
Dα(p∥q)=−α(1−α)∫xp(x)αq(x)1−αdx,
is a measure of dissimilarity between two probability distributions, p and q. The behavior of the α-divergence changes as α varies; for α≤0, it is mode-seeking, while for α≥1, it is mass-covering (Figure 1).
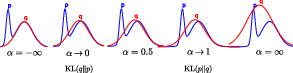
Figure 1: Illustration of unnormalized Gaussian approximating distributions q, shown in red, that minimize the α-divergence for different values of α with respect to a bimodal target distribution p, shown in blue.
The choice of α=2 in FAB minimizes the variance of importance sampling weights, which is beneficial for correcting bias in samples from the flow.
Annealed Importance Sampling (AIS)
AIS is used to generate samples in regions where the flow is a poor approximation of the target. AIS constructs a sequence of intermediate distributions, pi, between the initial distribution q and the target distribution p. Samples are drawn from q and then iteratively transitioned through the intermediate distributions using MCMC. The final sample, xM, is accompanied by an importance weight, wAIS, which accounts for the transformations applied during the transitions.
Flow AIS Bootstrap
FAB trains a flow q to approximate a target p by minimizing Dα=2(p∥q), which is estimated with AIS using q as initial distribution and p2/q as target.
The latter is the minimum variance importance sampling distribution for estimating the Dα=2(p∥q) loss. This process can be seen as a form of bootstrapping, where the flow q is fit using samples generated by itself, after they have been improved with AIS to fit p2/q. The gradient of the loss function is estimated using:
$\nabla_\theta \mathcal{L} (\theta ) = -\operatorname{E}_{\text{AIS} \left[ w_{\text{AIS} \nabla_\theta \log q_\theta(\bar{x}_{\text{AIS}) \right],$
where $\bar{x}_{\text{AIS}$ and $w_{\text{AIS}$ are the samples and weights generated by AIS when targeting p2/q. Gradients are stopped during the AIS sampling to ensure stable training.
Replay Buffer
To reduce the computational cost of AIS, FAB employs a prioritized replay buffer. The buffer stores AIS samples and their corresponding weights. During training, samples are drawn from the buffer with probability proportional to their AIS weights. A correction factor is applied to account for the difference between the current flow parameters and those used to generate the samples in the buffer. This replay buffer allows for the re-use of previously generated samples, reducing the number of target evaluations required.
Experimental Results
FAB was evaluated on three challenging problems:
- 2D Gaussian Mixture Model: FAB, with and without the replay buffer, accurately fit all modes of a complex 2D Gaussian mixture model. Other methods, such as those based on KL divergence, often failed to capture all modes due to mode-seeking behavior. (Figure 2)
Figure 2: Contour lines for the target distribution p and samples (blue discs) drawn from the approximation qθ obtained by different methods on the mixture of Gaussians problem.
- 32D "Many Well" Problem: FAB demonstrated strong performance on the 32D "Many Well" problem, a high-dimensional distribution with a large number of modes. FAB, particularly with the replay buffer, achieved results comparable to training with maximum likelihood, while other methods struggled. (Figure 3)
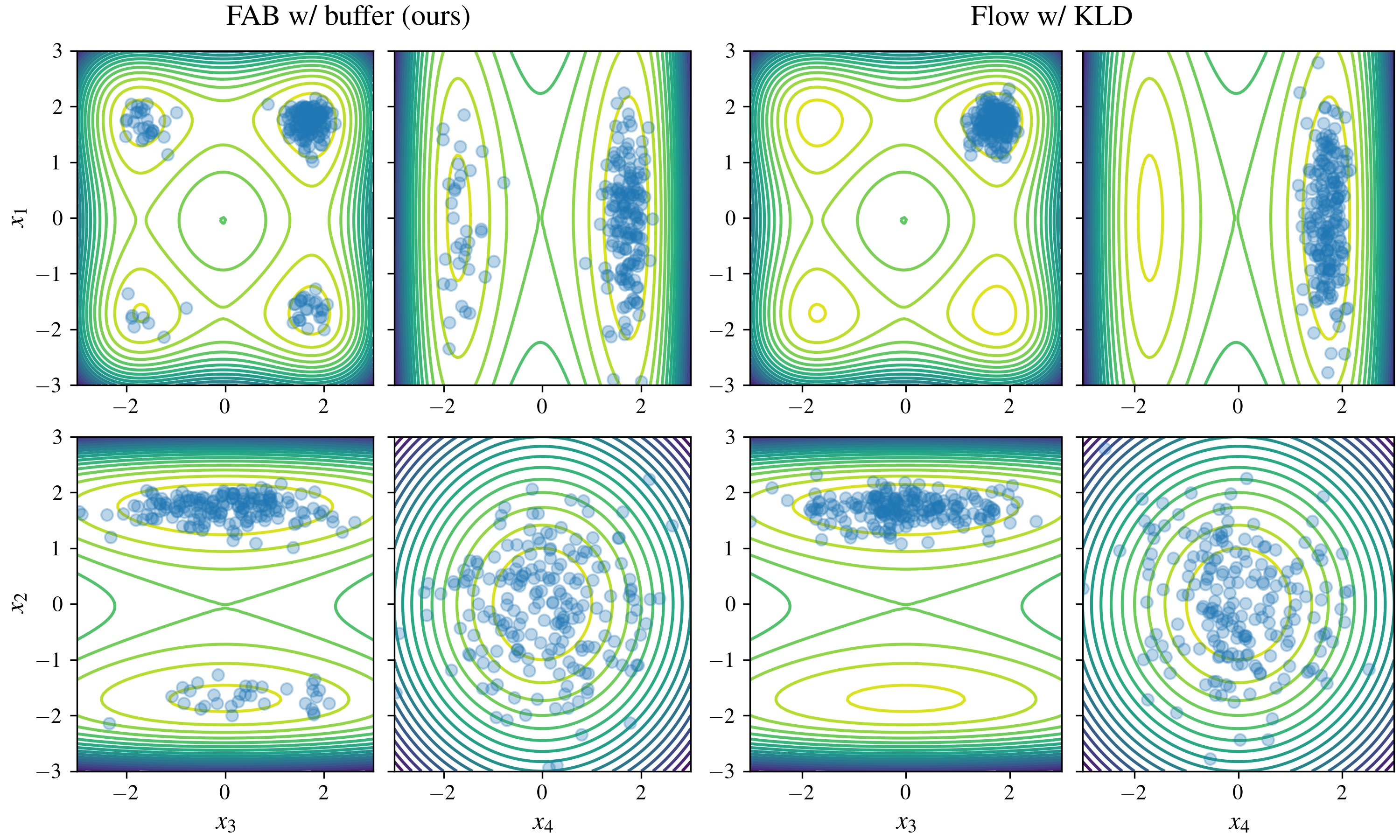
Figure 3: Samples from qθ and target contours for marginal distributions over the first four elements of x in the 32 dimensional Many Well Problem.
- Alanine Dipeptide Boltzmann Distribution: FAB was used to learn the Boltzmann distribution of alanine dipeptide, a challenging problem in molecular dynamics. FAB produced better results than training via maximum likelihood on MD samples, while using 100 times fewer target evaluations. Unbiased histograms of dihedral angles, nearly identical to the ground truth, were obtained after reweighting samples (Figure 4).
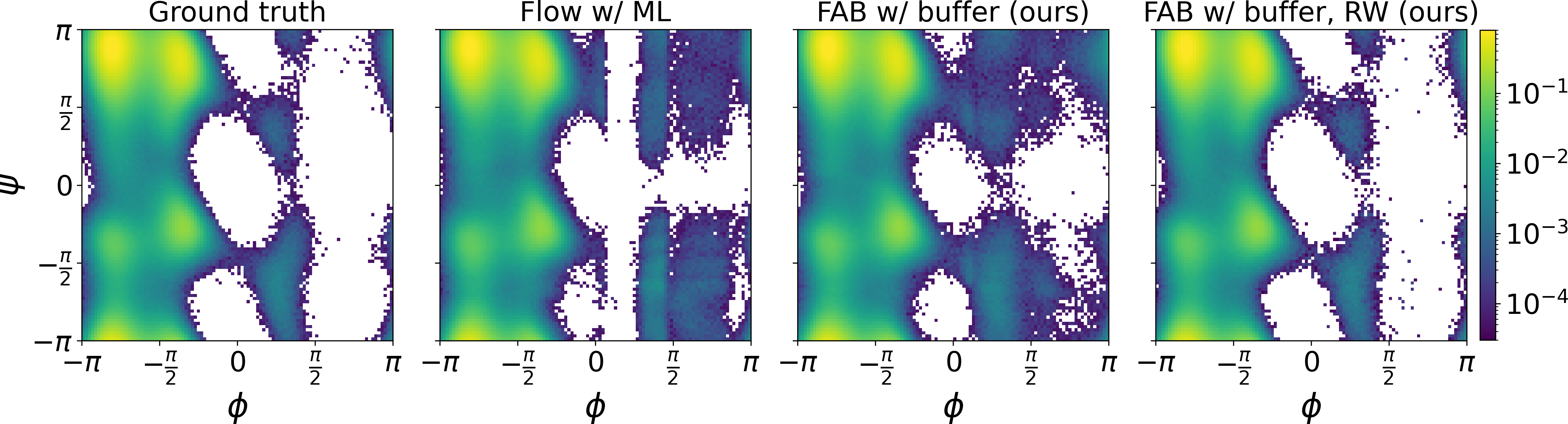
Figure 4: From left to right, Ramachandran plots of the ground truth generated by MD, a flow model trained by ML on MD samples, and by FAB using a replay buffer before and after reweighting samples to eliminate bias.
The paper relates FAB to other methods that combine flows with MCMC, such as Stochastic Normalizing Flows (SNFs) and Continual Repeated Flow Annealed Transport (CRAFT). FAB differs from these methods in its use of the α-divergence and the AIS bootstrap mechanism. The work also discusses connections to research on improving transition kernels and intermediate distributions in MCMC and AIS.
Implications and Future Directions
The results of this paper suggest that FAB is a promising approach for training normalizing flows to approximate complex target distributions. The method's ability to avoid mode-seeking behavior and reduce reliance on expensive MCMC samples makes it well-suited for problems in various fields, including molecular dynamics, computational physics, and Bayesian inference.
Future work could explore:
- Scaling FAB to even higher-dimensional problems, such as modeling the Boltzmann distribution of larger proteins.
- Combining FAB with more expressive flow architectures or with techniques for learning transition kernels in MCMC.
- Investigating the use of control variates and defensive importance sampling to further reduce variance in the loss estimate.
- Applying FAB to other types of models, such as diffusion models.
Conclusion
FAB offers a novel and effective approach for training normalizing flows. By combining α-divergence minimization with an AIS bootstrapping mechanism, FAB can accurately approximate complex, multimodal target distributions without relying on samples from those distributions. The use of a prioritized replay buffer further enhances the efficiency and stability of the method. The experimental results demonstrate the potential of FAB for solving challenging problems in various scientific and engineering domains.