- The paper presents an adaptive re-ranking system (Gar) that uses corpus graphs to iteratively expand candidate pools, enhancing recall and precision.
- Gar leverages document similarity and the clustering hypothesis to integrate high-scoring neighbors into the re-ranking process.
- Experimental evaluations on TREC Deep Learning 2019 and MS MARCO datasets show significant improvements in nDCG and R@1k metrics with minimal overhead.
"Adaptive Re-Ranking with a Corpus Graph" (2208.08942): An Essay
Introduction
Search systems depend heavily on the effectiveness of re-ranking processes to achieve high retrieval performance. Traditional re-ranking focuses on assigning new scores to the documents in a candidate pool, utilizing complex scoring functions that are computationally intensive. This approach, however, encounters significant limitations in recall due to the restricted initial candidate pool. The paper "Adaptive Re-Ranking with a Corpus Graph" addresses this challenge by introducing a novel re-ranking strategy that extends the candidate pool during the re-ranking process using a corpus graph, leveraging document similarity to iteratively enhance the ranking pool.
Methodology
The Graph-based Adaptive Re-ranking (Gar) system proposed in the paper employs a feedback mechanism rooted in the clustering hypothesis: documents closely related to high-scoring entries are likely to also yield high scores. Gar adapts the candidate pool dynamically by adding documents most similar to the top-ranked entries at each re-ranking step. This process not only allows the re-ranking of documents that might be missed due to limited budget but also identifies additional relevant documents that were not present in the original candidate set.
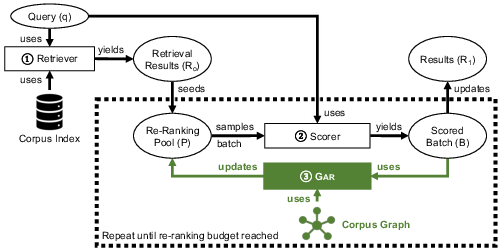
Figure 1: Overview of Gar. Traditional re-ranking exclusively scores results seeded by the retriever. Gar (in green) adapts the re-ranking pool after each batch based on the computed scores and a pre-computed graph of the corpus.
The Gar approach constructs a corpus graph offline where nodes represent documents, and edges signify document similarity, calculated lexically or semantically. The graph's sparsity is controlled by limiting the number of edges per node, hence maintaining a feasible memory footprint. The re-ranking strategy alternates between processing items from the initial ranking pool and exploring the frontier set formed by the graph neighbors of high-scoring documents.
Experimental Evaluation
Experiments were conducted on TREC Deep Learning 2019 and MS MARCO datasets to evaluate Gar's efficacy. Test results indicate substantial improvements in both precision and recall metrics across various re-ranking pipelines. Notably, Gar enhances recall by incorporating documents initially absent from re-ranking candidates, leading to a significant increase in the nDCG and R@1k metrics when applied to BM25 candidate retrieval enhanced with dense re-ranking, e.g., MonoT5-base.
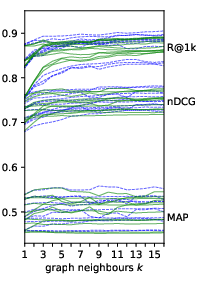
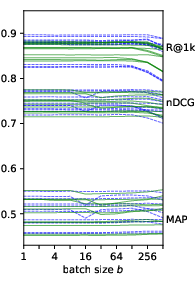
Figure 2: Performance of Gar when the number of neighbours in the corpus graph k and the batch size b vary. Each line represents a system from Table~\ref{tab:comp}
Implications and Future Work
The results underline the potential of incorporating document similarity-based feedback within re-ranking workflows. This paradigm shift allows search systems not only to improve recall without additional retrieval steps but also to maintain high-precision scores. Future research directions include optimizing the trade-off between computational efficiency and ranking quality, potentially exploring adaptive mechanisms within the re-ranking cycle to dynamically balance these concerns.
Moreover, Gar's foundation suggests a more strategic approach to closed-loop learning and explore-exploit scenarios in information retrieval systems. The use of corpus graphs could further be enhanced with learned embeddings and optimized for higher-order connections, broadening its applicability across various domains of information systems and retrieval-centric applications.
Conclusion
The paper makes a significant contribution to the field of information retrieval by addressing recall limitations inherent to traditional re-ranking methodologies. By embedding a feedback loop in re-ranking, Gar effectively identifies overlooked relevant documents, thus enhancing both recall and precision. The adaptability and minimal overhead associated with Gar offer a promising step towards more responsive and precise search systems. The innovative use of corpus graphs to guide adaptive re-ranking lays the groundwork for future explorations into sophisticated retrieval mechanisms that integrate clustered document contexts.