- The paper presents a novel DRL framework that reframes backtest overfitting as a hypothesis test to filter out overoptimistic trading agents.
- It employs combinatorial cross-validation across multiple market splits to ensure robust validation of DRL strategies.
- Experimental results show improved cumulative returns and reduced volatility, highlighting effective overfitting mitigation.
Introduction
The paper "Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting" discusses the challenges of designing profitable trading strategies in the volatile cryptocurrency market using Deep Reinforcement Learning (DRL). The authors address the issue of backtest overfitting, a prevalent problem leading to misleading positive results due to model overfitting in DRL applications. They propose a methodology to detect and mitigate this overfitting by framing it as a hypothesis test and validating agents through combinatorial cross-validation.
Detection of Backtest Overfitting Via Hypothesis Testing
Backtest overfitting is a critical concern in DRL strategies for cryptocurrency trading. The authors propose to cast this problem as a hypothesis test, fundamentally evaluating the probability p of overfitting. In this framework, H0: p<α denotes that an agent is not overfitted, while H1: p≥α suggests overfitting, where α is the chosen significance level. This test aims to filter out agents that deliver overoptimistic returns during backtesting due to overfitting, induced either by hyperparameter sensitivities or information leakage.
In their method, the significance level α is set based on the Neyman-Pearson framework to effectively manage Type I errors. In practice, this translates to rejecting trained agents with logit distributions that suggest p≥α, facilitating the identification and deployment of robust, less-overfitted agents in real market settings.
Combinatorial Cross-Validation for Estimating Overfitting Probability
To estimate the probability that a DRL agent is overfitted, the authors leverage combinatorial cross-validation. This technique involves multiple data splits, allowing for validation across distinct market scenarios. Specifically, they simulate the market environment and perform extensive trials, systematically varying hyperparameters to train the agents across different splits, estimating their mean performance. This approach is more informative than traditional K-fold methods, as it accounts for potential information leakages inherent in IID assumptions.
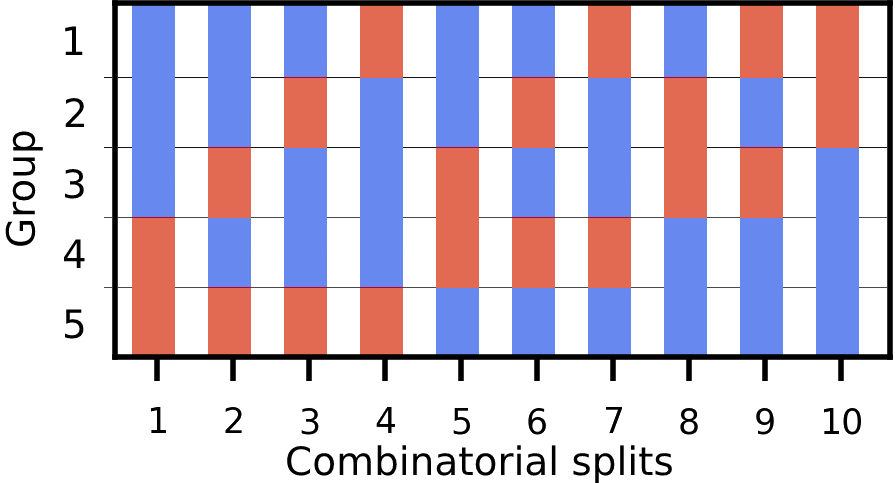
Figure 1: Illustration of combinatorial splits. Split the data into N=5 groups, k=2 groups for the train set (red) and the rest N−k=3 groups for the validation set (blue).
From each validation trial's return vector, a probability of overfitting is systematically computed. This operationalizes the backtest overfitting detection, ensuring the selection of agents that generalize better in various conditions.
The experimental results demonstrate that agents selected via the proposed approach perform notably better than conventional DRL agents under identical hyperparameter setups. Evaluations on 10 cryptocurrencies over a volatile market test period illustrate significant improvements in cumulative returns alongside lower volatility figures.
The probability of overfitting for conventional and DRL agents was quantitatively assessed using logit distributions of return ranks across in-sample (IS) and out-of-sample (OOS) splits, demonstrating distinctly lower probabilities (p<α) for agents passing the hypothesis test compared to those trained through traditional methods.
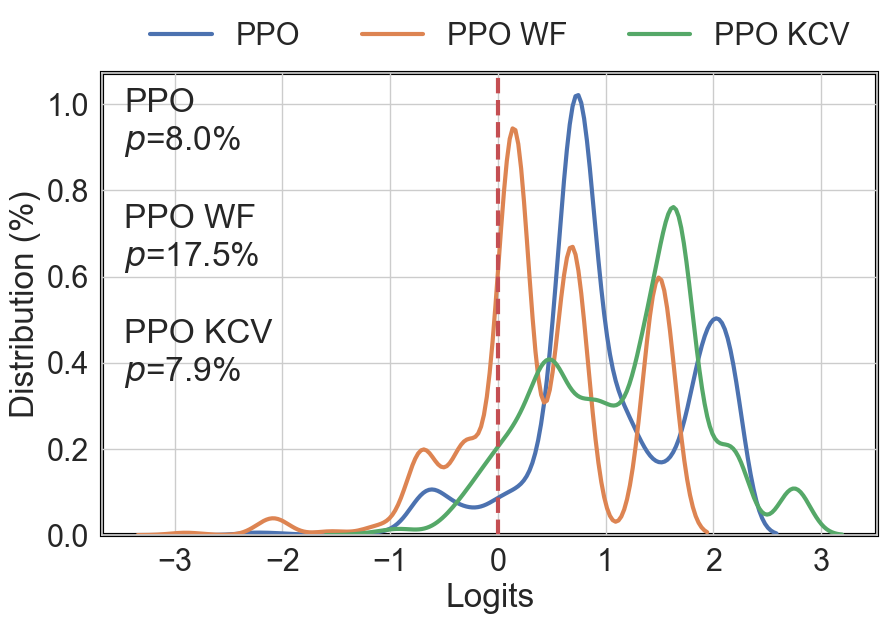
Figure 2: Logit distribution f(λ) of three conventional agents.
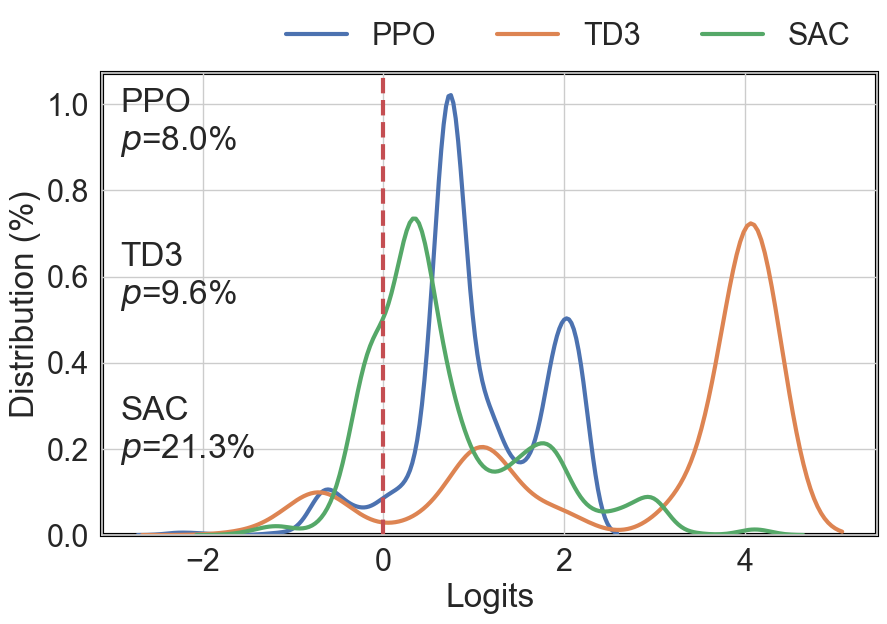
Figure 3: Logit distribution f(λ) of three DRL agents.
Conclusion
The authors successfully address the backtest overfitting challenge using combinatorial cross-validation and carefully crafted hypothesis tests to vet DRL agents for cryptocurrency trading. The proposed methodology not only aids in selecting robust agents but also provides a statistically grounded framework to predict out-of-sample performance. Future enhancements could include evolving the probability assessment during agent training, exploring more sophisticated limit order integrations, or examining larger-scale datasets with enriched feature spaces. This work lays a comprehensive foundation for deploying effective DRL strategies in real-world cryptocurrency trading environments.