- The paper introduces RAG-end2end, a model that jointly trains the retriever and generator to tackle domain-specific challenges in QA.
- It leverages an auxiliary reconstruction signal and asynchronous re-indexing of the knowledge base to bridge domain gaps.
- Empirical results show significant gains in Exact Match and F1 scores across healthcare, news, and conversational datasets.
Improving the Domain Adaptation of Retrieval Augmented Generation Models
The paper "Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering" focuses on enhancing domain adaptation in RAG models, specifically for tasks outside Wikipedia-based knowledge, targeting specialized domains such as healthcare and news. This involves joint training and introducing a novel auxiliary signal to improve performance across these tasks.
Introduction to RAG and Domain Challenges
RAG models integrate retrieval and generation stages, combining Dense Passage Retrieval (DPR) with a BART generator. While effective for datasets grounded on comprehensive Wikipedia articles, adapting RAG for domains like COVID-19 or conversational datasets remains challenging due to inherent domain-specific context gaps.
RAG-end2end Architecture
The authors propose an extension, RAG-end2end, which synchronously trains the retriever, generator, and updates the knowledge base. This extension leverages domain-specific auxiliary signals that encourage RAG-end2end to reconstruct input sentences from relevant retrieved knowledge, enhancing model adaptation to domain-specific nuances.
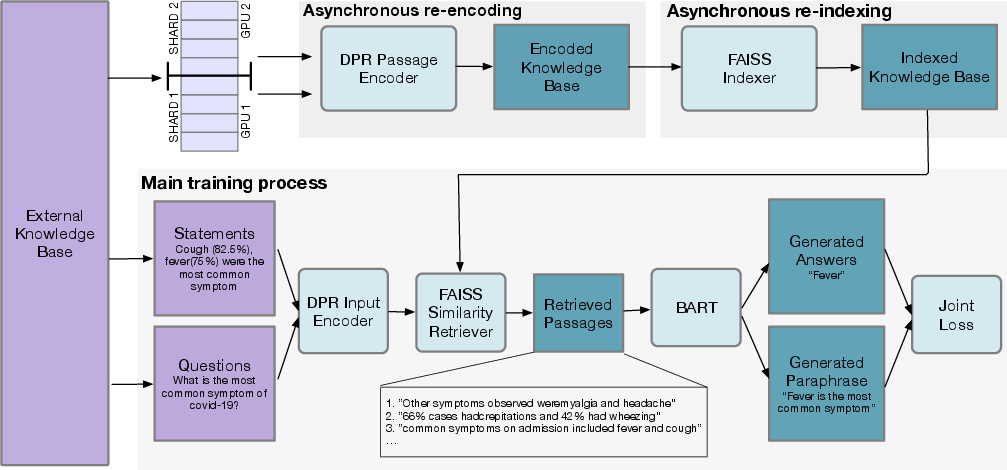
Figure 1: System Overview. The training architecture dynamically optimizes joint QA and paraphrasing signals while re-encoding the knowledge base.
Retraining the Knowledge Base
Knowledge base re-indexing is integral, accomplished via asynchronous updates using FAISS, ensuring scalability even with extensive datasets. This ensures RAG-end2end remains computationally viable without stalling training due to re-indexing latency.
Impact of Joint Training and Statement Reconstruction
RAG-end2end introduces joint fine-tuning for its retriever components, crucial for domain performance. Empirical results demonstrate measurable gains when employing end-to-end training compared to a static retriever setup, particularly citing a significant increase in Exact Match (EM) and F1 scores across varied domains.
The auxiliary statement reconstruction task further augments learning by compelling the model to generate domain-tailored factual content using a tokenized input framework.
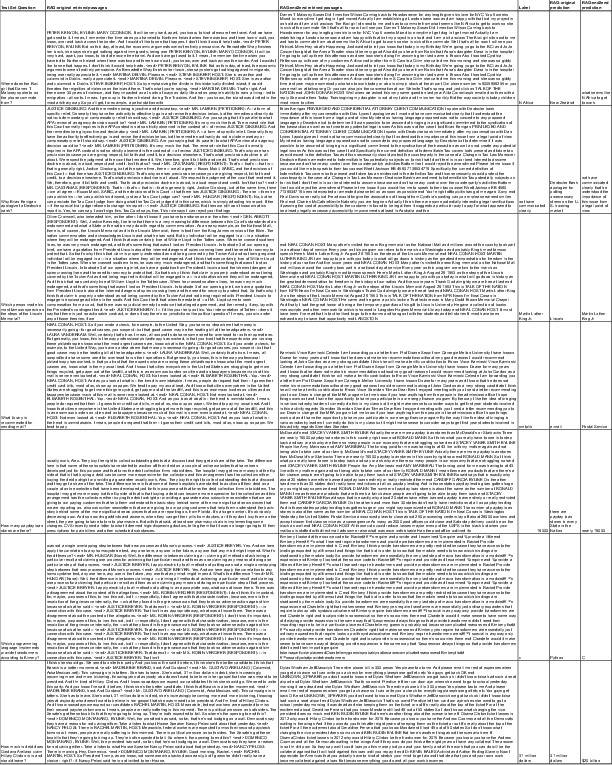
Figure 2: Predicted answers and retrieved passages for a set of questions from the conversational domain.
Evaluation and Results
The model was assessed against COVID-19, News, and Conversation datasets, employing metrics like EM, F1, and retrieval accuracy. Findings consistently exhibited RAG-end2end's superior adaptability resulting from joint training integration. Specific domain metrics, such as a 13-point EM gain in the Conversational domain, and marked increases in retrieval accuracy, substantiate these claims.
Enhancements through Domain-Specific DPR
Additionally, the paper explores finetuning DPR individually using a domain-specific data approach as an alternative mechanism, juxtaposing results against RAG-end2end enhancements. Even so, RAG-end2end's holistic retriever adaptations yielded superior outcomes, reinforcing its domain utility.
Conclusion
The advancements posited by RAG-end2end represent a crucial step towards effectively adapting RAG architectures for domain-specific tasks. By leveraging asynchronous indexing and auxiliary reconstruction signals, the research paves the way for improvements in retrieval augmented models' applicability beyond traditional datasets. Future exploration might focus on extending these techniques to other natural language processing domains, such as summarization or fact-checking, broadening the scope of RAG-end2end's impact.