- The paper presents ITSRN++, which redefines upsampling using an implicit transformer to generate continuous pixel features from screen content images.
- The model integrates a dual branch block that concurrently captures high-frequency details via convolution and low-frequency patterns via attention.
- Evaluation on the SCI2K dataset shows ITSRN++ outperforms existing methods in PSNR and SSIM, while maintaining computational efficiency.
"ITSRN++: Stronger and Better Implicit Transformer Network for Continuous Screen Content Image Super-Resolution" (2210.08812)
Introduction
The paper introduces ITSRN++, an advanced model designed for continuous Screen Content Image Super-Resolution (SCI SR). Addressing the growing trends of remote collaboration and online education, where screen content needs to be magnified beyond its original resolution, ITSRN++ provides a more flexible and sharper solution compared to traditional upsampling methods. It leverages a novel implicit transformer architecture for continuous upsampling and improved feature extraction through an enhanced transformer network.
The proposed implicit transformer based upsampler in ITSRN++ is a notable departure from fixed and integer-scale upsampling methods like deconvolution and pixel-shuffle. By introducing a modulation-based approach, the upsampler generates pixel features in continuous space using a periodic nonlinear function. Specifically, it redefines the upsampling problem into three conceptual steps: coordinate projection, weight generation, and aggregation, each harmonizing with the transformer model's processes.
This method enhances flexibility allowing arbitrary magnification ratios while maintaining image sharpness—enabling seamless integration of high-frequency components essential for screen content that predominantly comprises text and graphics.







Figure 1: Visual comparison of the proposed ITSRN++ with state-of-the-art continuous magnification methods. With continuous upsamplers, images can be magnified with arbitrary ratios.
To bolster feature extraction capabilities, ITSRN++ introduces a parallel structure combining convolution and attention mechanisms in its dual branch block (DBB). Unlike sequential stacking that only modulates either local or global features per layer, the parallel setup captures both simultaneously. The convolution branch addresses high-frequency components, while the attention branch focuses on low-frequency patterns in screen content, optimizing the retention of sharp edges and repetitive patterns.
This strategic hybridization outperforms traditional dense and channel attention-based networks by creating richer high-trust operational space within the transformer model, significantly improving SCI SR quality.
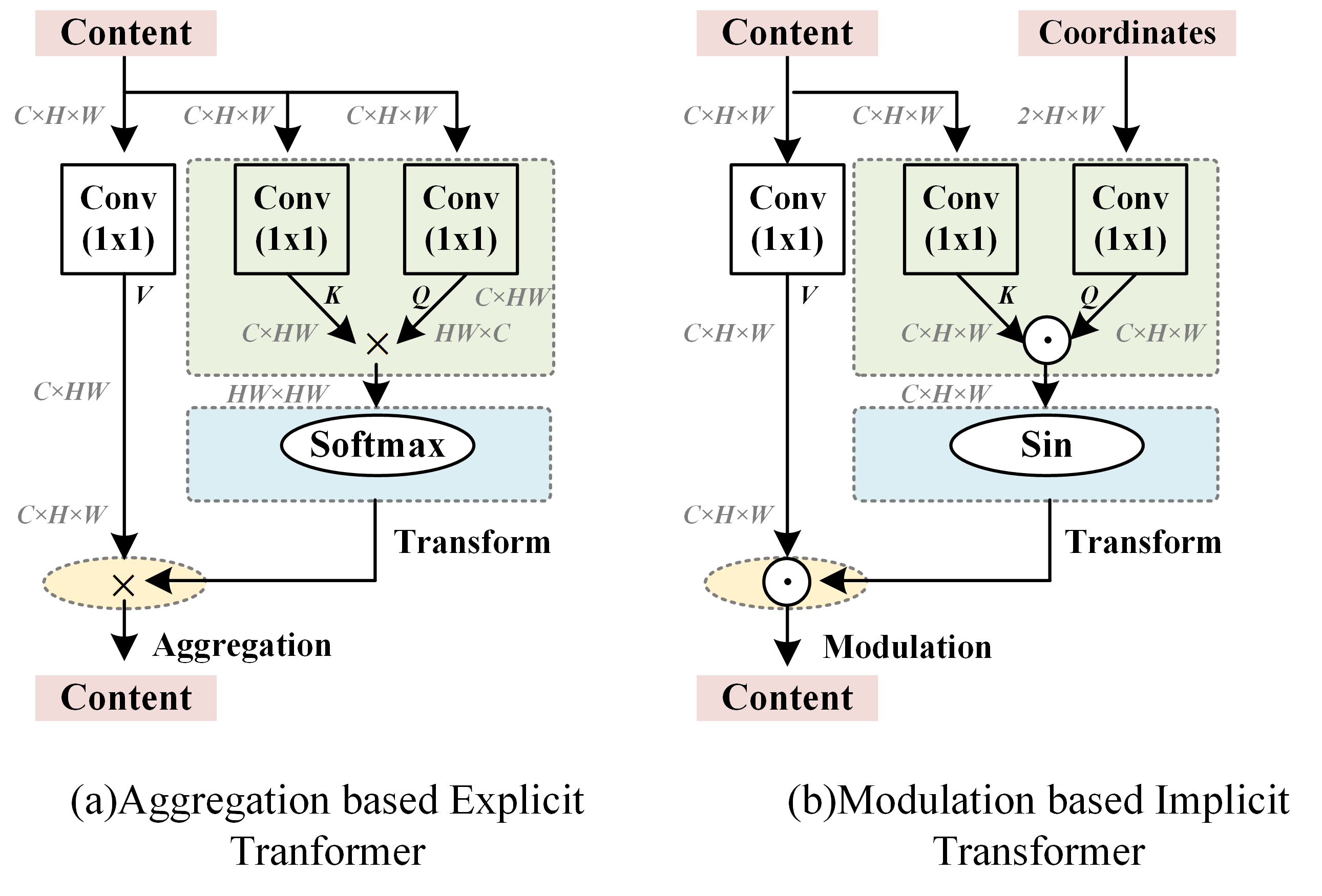
Figure 2: Illustration of aggregation based explicit transformer and modulation based implicit transformer.
ITSRN++'s effectiveness is reinforced with the introduction of the SCI2K dataset, a comprehensive screen content database featuring 2K resolution images. This dataset facilitates extensive benchmarking and has revealed ITSRN++ to excel in both PSNR and SSIM metrics across various SCI SR benchmark datasets, outperforming previously competitive models like SwinIR and RCAN in sharpness and edge retention.
Moreover, the model's architecture ensures it remains computationally tractable, optimizing feature extraction and upsampler efficiency.
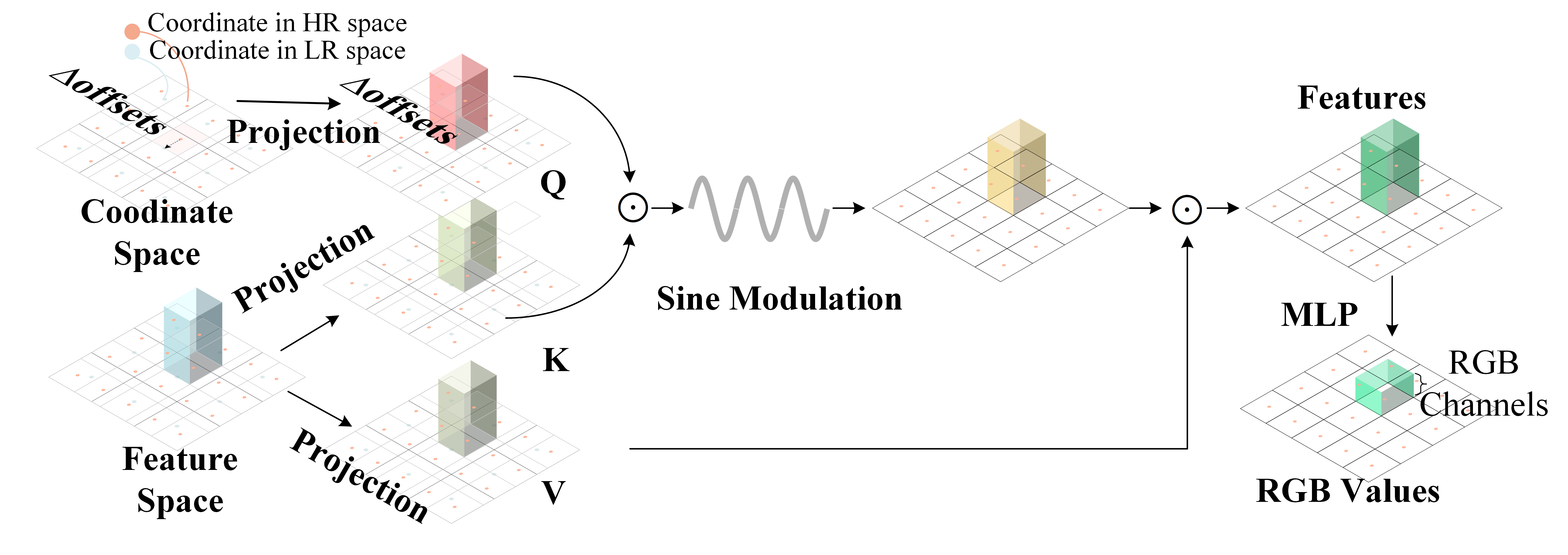
Figure 3: The proposed implicit transformer based upsampler, which can generate pixel values in continuous space. The orange coordinates are in HR space and the blue coordinates are in LR space.
Conclusion
ITSRN++ sets a new paradigm in SCI SR through innovative implicit transform techniques and enhanced feature extraction methodologies. The work exemplifies the integration of advanced neural network architectures to adapt to specific content needs, providing a versatile yet powerful toolset for high-resolution screen content analysis. Future directions may involve optimizing computational load, aiming for real-time applications without compromising the upsampling quality and resolution flexibility.