Zero-shot point cloud segmentation by transferring geometric primitives
Abstract: We investigate transductive zero-shot point cloud semantic segmentation, where the network is trained on seen objects and able to segment unseen objects. The 3D geometric elements are essential cues to imply a novel 3D object type. However, previous methods neglect the fine-grained relationship between the language and the 3D geometric elements. To this end, we propose a novel framework to learn the geometric primitives shared in seen and unseen categories' objects and employ a fine-grained alignment between language and the learned geometric primitives. Therefore, guided by language, the network recognizes the novel objects represented with geometric primitives. Specifically, we formulate a novel point visual representation, the similarity vector of the point's feature to the learnable prototypes, where the prototypes automatically encode geometric primitives via back-propagation. Besides, we propose a novel Unknown-aware InfoNCE Loss to fine-grained align the visual representation with language. Extensive experiments show that our method significantly outperforms other state-of-the-art methods in the harmonic mean-intersection-over-union (hIoU), with the improvement of 17.8\%, 30.4\%, 9.2\% and 7.9\% on S3DIS, ScanNet, SemanticKITTI and nuScenes datasets, respectively. Codes are available (https://github.com/runnanchen/Zero-Shot-Point-Cloud-Segmentation)
- Joint 2d-3d-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105 (2017).
- SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proc. of the IEEE/CVF International Conf. on Computer Vision (ICCV).
- Zero-shot semantic segmentation. Advances in Neural Information Processing Systems 32 (2019).
- nuScenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027 (2019).
- Unsupervised learning of intrinsic structural representation points. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9121–9130.
- Runnan Chen. 2023. Studies on attention modeling for visual understanding. HKU Theses Online (HKUTO) (2023).
- Towards Label-free Scene Understanding by Vision Foundation Models. arXiv preprint arXiv:2306.03899 (2023).
- CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7020–7030.
- Towards 3d scene understanding by referring synthetic models. arXiv preprint arXiv:2203.10546 (2022).
- 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12547–12556.
- Mitigating the hubness problem for zero-shot learning of 3d objects. arXiv preprint arXiv:1907.06371 (2019).
- Transductive zero-shot learning for 3d point cloud classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 923–933.
- Zero-shot learning on 3d point cloud objects and beyond. arXiv preprint arXiv:2104.04980 (2021).
- Zero-shot learning of 3d point cloud objects. In 2019 16th International Conference on Machine Vision Applications (MVA). IEEE, 1–6.
- 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3075–3084.
- MMDetection3D Contributors. 2020. MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.
- ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE.
- Devise: A deep visual-semantic embedding model. Advances in neural information processing systems 26 (2013).
- Paraphrase generation with latent bag of words. Advances in Neural Information Processing Systems 32 (2019).
- Context-aware feature generation for zero-shot semantic segmentation. In Proceedings of the 28th ACM International Conference on Multimedia. 1921–1929.
- Uncertainty-aware learning for zero-shot semantic segmentation. Advances in Neural Information Processing Systems 33 (2020), 21713–21724.
- Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11108–11117.
- Rethinking range view representation for lidar segmentation. arXiv preprint arXiv:2303.05367 (2023).
- Benchmarking 3D Perception Robustness to Common Corruptions and Sensor Failure. In International Conference on Learning Representations 2023 Workshop on Scene Representations for Autonomous Driving.
- Robo3d: Towards robust and reliable 3d perception against corruptions. arXiv preprint arXiv:2303.17597 (2023).
- Consistent structural relation learning for zero-shot segmentation. Advances in Neural Information Processing Systems 33 (2020), 10317–10327.
- Segment Any Point Cloud Sequences by Distilling Vision Foundation Models. arXiv preprint arXiv:2306.09347 (2023).
- See More and Know More: Zero-shot Point Cloud Segmentation via Multi-modal Visual Data. arXiv preprint arXiv:2307.10782 (2023).
- Learning unbiased zero-shot semantic segmentation networks via transductive transfer. IEEE Signal Processing Letters 27 (2020), 1640–1644.
- Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Clouds. In 2021 International Conference on 3D Vision (3DV). IEEE, 992–1002.
- Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
- Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems 26 (2013).
- Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 1532–1543.
- Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 652–660.
- Hubs in space: Popular nearest neighbors in high-dimensional data. Journal of Machine Learning Research 11, sept (2010), 2487–2531.
- Ridge regression, hubness, and zero-shot learning. In Joint European conference on machine learning and knowledge discovery in databases. Springer, 135–151.
- Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems 33 (2020), 596–608.
- Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF international conference on computer vision. 6411–6420.
- Hanna M Wallach. 2006. Topic modeling: beyond bag-of-words. In Proceedings of the 23rd international conference on Machine learning. 977–984.
- Zero-shot learning—a comprehensive evaluation of the good, the bad and the ugly. IEEE transactions on pattern analysis and machine intelligence 41, 9 (2018), 2251–2265.
- Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 16024–16033.
- Human-centric Scene Understanding for 3D Large-scale Scenarios. arXiv preprint arXiv:2307.14392 (2023).
- Hui Zhang and Henghui Ding. 2021. Prototypical matching and open set rejection for zero-shot semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 6974–6983.
- Learning a deep embedding model for zero-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2021–2030.
- Cylindrical and asymmetrical 3d convolution networks for lidar segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9939–9948.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Bridging Language and Geometric Primitives for Zero-shot Point Cloud Segmentation — Explained Simply
What is this paper about?
This paper is about teaching computers to understand 3D scenes made of “point clouds” (lots of 3D dots that form objects like chairs, tables, and cars). The goal is to color each point with the correct object type — a task called semantic segmentation. The twist: the computer should also recognize new object types it has never been told about during training. This is called zero-shot learning.
The big idea is to connect language (the names of objects, like “chair” or “desk”) with basic 3D shapes (like cubes and cylinders) so that the computer can use shape clues and word meanings to recognize new objects.
What questions does the paper try to answer?
The authors ask:
- How can a system label 3D points as different objects, even for object types it hasn’t been trained on?
- Can we use simple 3D shapes (geometric “building blocks”) and the meaning of words together to help the system figure out new objects?
- How do we stop the system from mistakenly calling an unseen object by the name of a similar seen object (like calling a “desk” a “table”)?
How did they do it? (Methods in simple terms)
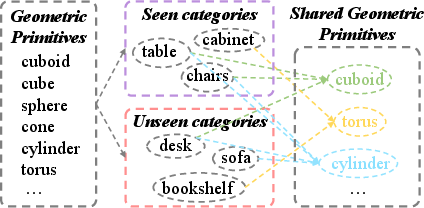
Think of every 3D object as being built from basic shapes — like LEGO bricks:
- A chair might be “one flat cuboid” for the seat and “four cylinders” for legs.
- A bookshelf might be “a big cuboid with smaller cuboids (shelves).”
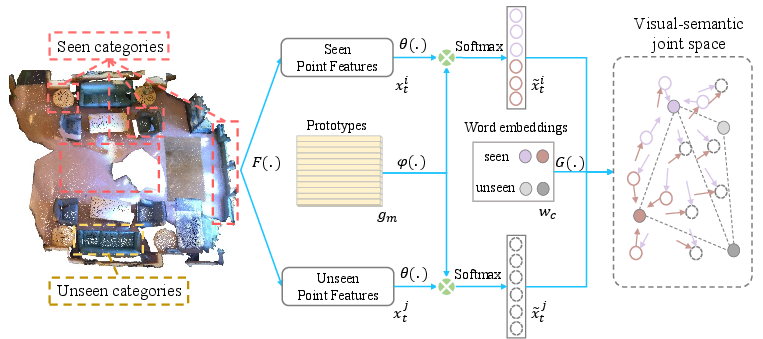
The method has three key parts:
- Learn basic shape “prototypes”
- The system learns a set of “prototypes,” which act like templates for basic 3D shapes (such as “cube-like,” “cylinder-like,” “corner-like”). These aren’t hand-made; the computer figures them out from data.
- For each point in the scene, the system measures how similar it is to each prototype. This gives a vector like a shape “mix” — for example, 60% cylinder-like, 30% cuboid-like, 10% corner-like.
- Represent word meanings in a matching way
- The system also represents each object name (like “chair,” “sofa,” “desk”) as numbers that capture word meaning (from tools like word2vec/GloVe).
- Because real objects are made of multiple shapes, they split a word’s meaning into several parts and combine them — like saying “desk” = a mixture of shape meanings. This helps align word meanings with shape mixes.
- Align shapes with words and avoid confusion
- They train the system so that the shape mix of a point matches the meaning of the correct word for seen classes (pulls matching pairs together).
- For unlabeled points of unseen classes (we know they’re from new classes but don’t know which), they push these away from the meanings of seen words. This reduces “bias” where the model would otherwise label new things as known ones. For example, it stops a “desk” (unseen) from being mislabeled as a “table” (seen) just because the words are similar.
- This training rule is called an Unknown-aware contrastive loss (a kind of “push-pull” learning). “Contrastive” means it learns by comparing: bring the right pairs closer, push the wrong ones apart.
During testing, the system:
- Turns each point into its “shape mix” (how much it looks like each prototype).
- Compares that mix to the meanings of all class names (both seen and unseen).
- Chooses the closest match.
What did they find, and why does it matter?
The method was tested on four large 3D datasets:
- S3DIS and ScanNet (indoor rooms with furniture)
- SemanticKITTI and nuScenes (outdoor traffic scenes from self-driving sensors)
They measured performance with a score called hIoU (harmonic mean intersection-over-union), which balances how well the model does on both seen and unseen classes. Their method beat previous best results by:
- +17.8% on S3DIS
- +30.4% on ScanNet
- +9.2% on SemanticKITTI
- +7.9% on nuScenes
Why it matters:
- It recognizes new objects without needing new hand-made labels.
- It works in both dense indoor scans and sparse outdoor LiDAR scans.
- It reduces common mistakes like calling a “desk” a “table” by using both geometry and language smartly.
What’s the impact of this research?
- Saves time and effort: Labeling 3D data point-by-point is slow and expensive. This approach can help auto-label new classes with minimal manual work.
- Makes robots and self-driving cars smarter: They can adapt to new environments or unfamiliar objects by relying on shape patterns and word meanings.
- Builds a general bridge between language and 3D shape: This could help future systems understand 3D scenes more like humans do — by recognizing objects as combinations of simple parts and connecting them to words.
In short, the paper shows a practical and clever way to recognize new 3D objects by combining the “building blocks” of shapes with the meanings of words, leading to big improvements over earlier methods.
Collections
Sign up for free to add this paper to one or more collections.