- The paper introduces GFS-VL, which integrates noisy 3D VLM pseudo-labels with refined few-shot samples for robust point cloud segmentation.
- It employs prototype-guided pseudo-label selection and adaptive infilling to enhance novel class detection while preserving base class integrity.
- The framework achieves significant improvements on ScanNet benchmarks, boosting harmonic mean by 28.57% and mIoU-N by 23.37% in 5-shot settings.
Generalized Few-shot 3D Point Cloud Segmentation with Vision-LLM: Technical Summary
Introduction and Motivation
Generalized few-shot 3D point cloud segmentation (GFS-PCS) addresses the challenge of adapting segmentation models to novel classes with minimal supervision, while retaining performance on base classes. Traditional few-shot segmentation methods are constrained by the sparsity of support samples and typically ignore base classes during inference. Recent advances in 3D vision-LLMs (3D VLMs) offer open-vocabulary capabilities, but their predictions are often noisy. This work introduces GFS-VL, a framework that synergistically combines dense but noisy pseudo-labels from 3D VLMs with precise few-shot samples, aiming to maximize the strengths of both modalities for robust GFS-PCS.
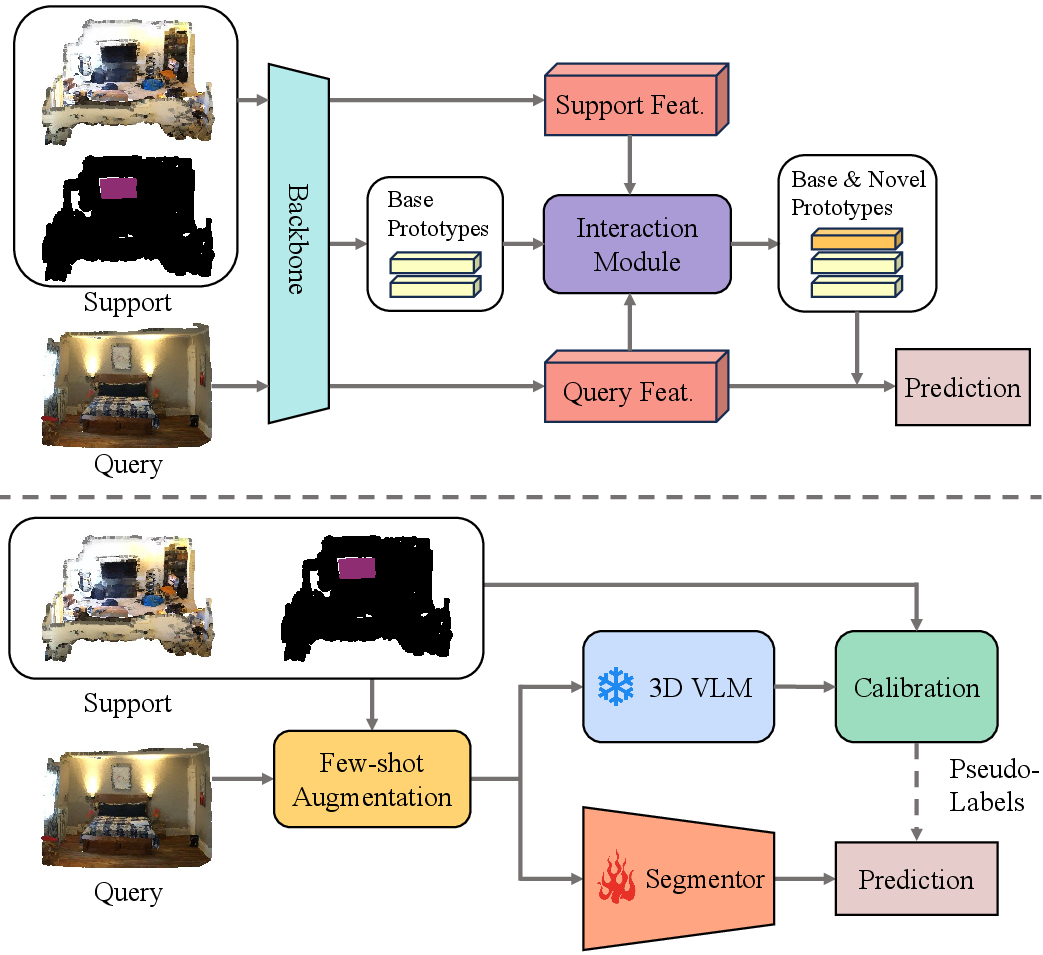
Figure 1: Comparison of the GFS-VL framework with prior work, highlighting the integration of open-world knowledge from 3D VLMs and calibration with few-shot samples.
Methodology
Framework Overview
GFS-VL employs a canonical segmentor architecture with a backbone and linear classification heads for base and novel classes. The model is first trained on base classes, then adapted to novel classes using few-shot samples. The key innovation is the integration of 3D VLM pseudo-labels, which are filtered and refined using prototype guidance from few-shot data.
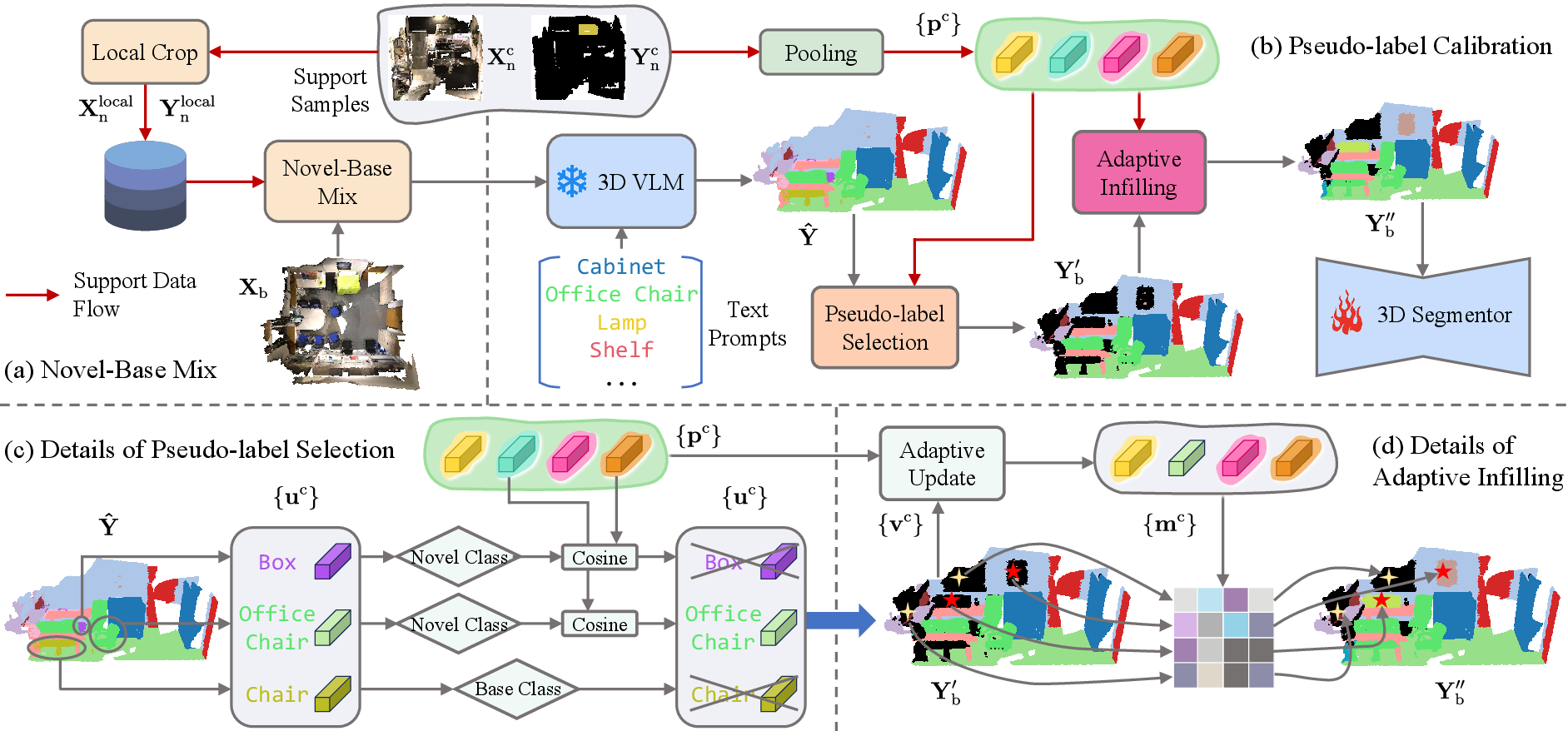
Figure 2: Overview of GFS-VL, illustrating novel-base mix, pseudo-label selection, and adaptive infilling for robust supervision.
Prototype-Guided Pseudo-label Selection
Raw pseudo-labels from 3D VLMs are filtered using cosine similarity between predicted prototypes and support prototypes derived from few-shot samples. Only high-confidence regions are retained, mitigating the impact of noisy VLM predictions. This process is efficiently implemented via mask-based indexing.
Adaptive Infilling
Filtered pseudo-labels often leave regions unlabeled. Adaptive infilling constructs an adaptive prototype set from both current pseudo-labels and support prototypes, assigning novel class labels to unlabeled regions if their feature similarity exceeds a threshold. This mechanism enables both completion of partial masks and discovery of missed novel classes.
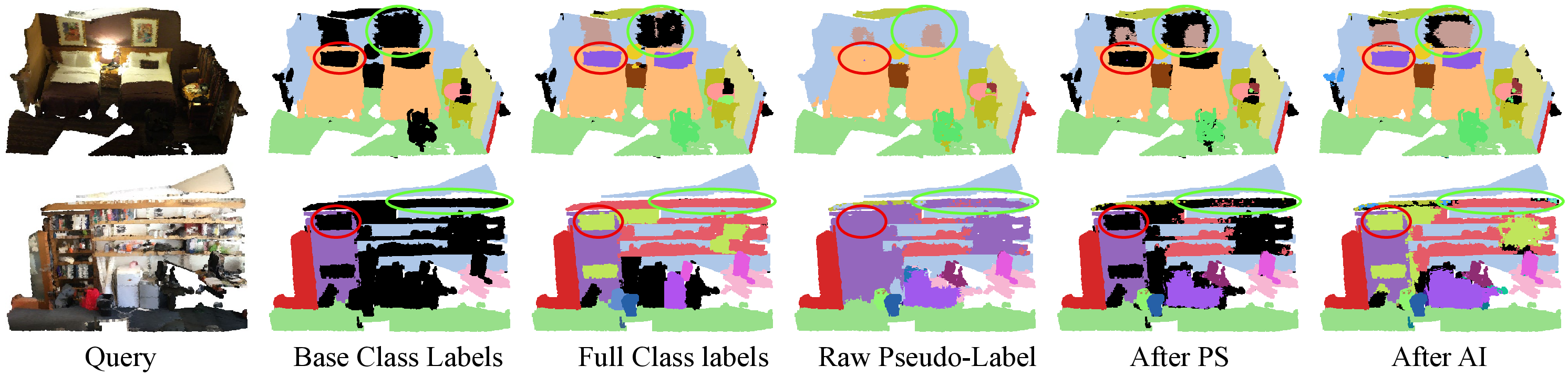
Figure 3: Visualization of pseudo-label refinement, showing improvements after applying pseudo-label selection and adaptive infilling.
Novel-Base Mix Augmentation
To further exploit few-shot samples, the novel-base mix strategy embeds support samples into training scenes while preserving contextual cues. Unlike conventional 3D augmentation, which often disrupts context, this approach aligns novel objects with base scenes using spatial anchors, maintaining scene integrity and enhancing novel class recognition.
Benchmarking and Evaluation
Recognizing the limited diversity in existing GFS-PCS benchmarks, the authors introduce two new benchmarks based on ScanNet200 and ScanNet++, featuring 40 and 18 novel classes, respectively. These benchmarks provide a more comprehensive evaluation of generalization capabilities.
Experimental results demonstrate that GFS-VL achieves substantial improvements over state-of-the-art baselines across all metrics and datasets. On ScanNet200, GFS-VL improves harmonic mean (HM) by 28.57% and mIoU-N by 23.37% over the closest baseline in the 5-shot setting. Similar gains are observed on ScanNet++ and the traditional ScanNet benchmark.
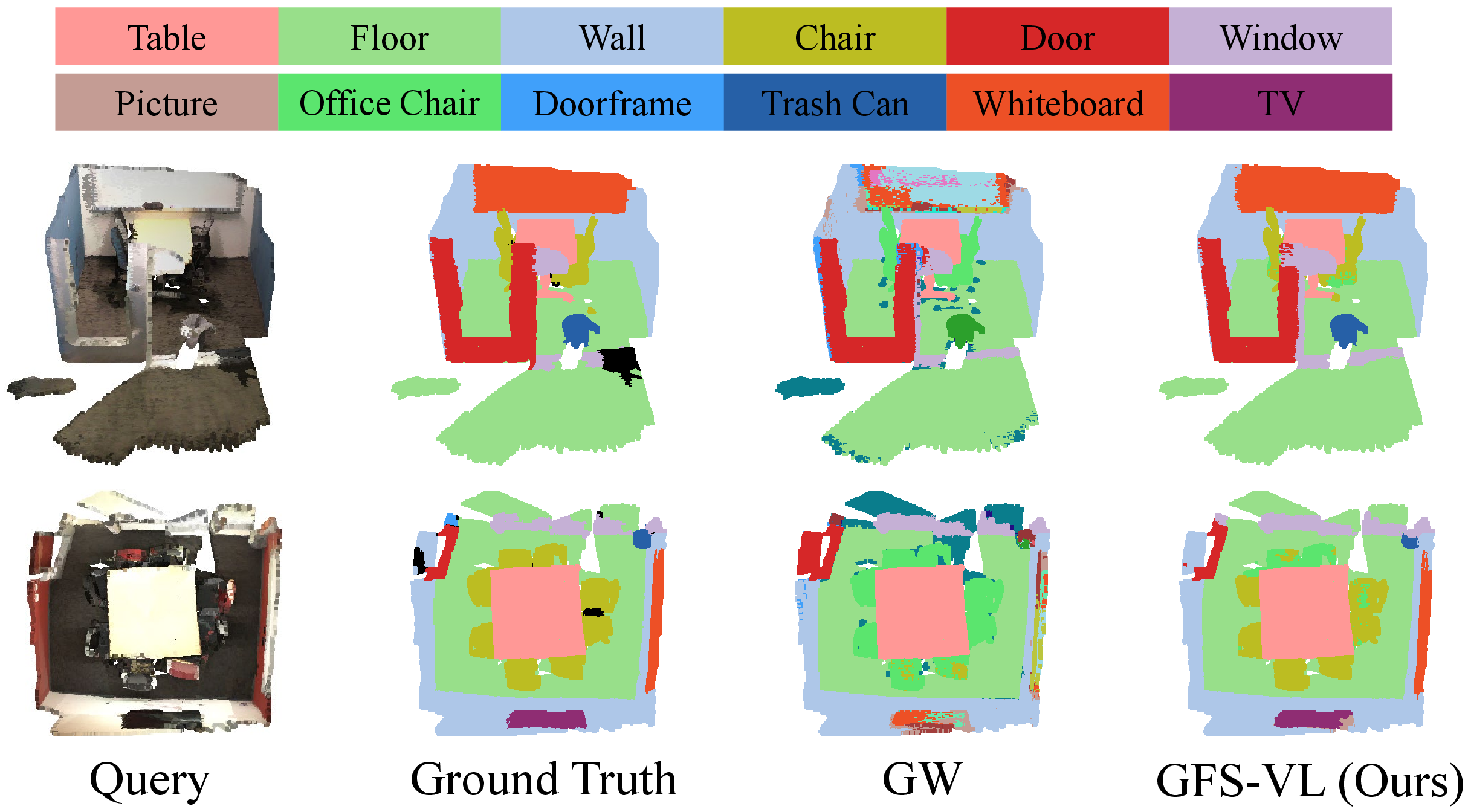
Figure 4: Qualitative comparison between GW and GFS-VL on ScanNet200, illustrating superior segmentation accuracy and novel class generalization.
Ablation and Analysis
Ablation studies confirm the effectiveness of each module:
- Pseudo-label Selection: Significantly improves pseudo-label quality and segmentation performance.
- Adaptive Infilling: Further enhances coverage of novel classes, especially in unlabeled regions.
- Novel-Base Mix: Outperforms alternative mix strategies by preserving local context, critical for challenging novel class recognition.
The framework is robust to backbone and 3D VLM choices, demonstrating generalizability. Thresholds for prototype similarity and infilling are not overly sensitive, indicating stable performance.
Implementation Considerations
- Computational Requirements: The framework is lightweight, leveraging a simple segmentor and efficient mask-based operations. Training and inference are feasible on commodity GPUs.
- Scalability: The modular design allows scaling to larger datasets and more novel classes without significant overhead.
- Deployment: The method is suitable for real-world scenarios, as it operates on full scenes and does not require support samples at inference.
Implications and Future Directions
GFS-VL establishes a new paradigm for GFS-PCS by effectively integrating open-world semantic knowledge from 3D VLMs with the precision of few-shot samples. The introduction of diverse benchmarks sets a higher standard for evaluation, revealing limitations of prior baselines and guiding future research toward more realistic generalization.
Potential future developments include:
- Enhancing pseudo-label refinement with uncertainty modeling or active learning.
- Extending the framework to other modalities (e.g., LiDAR, multi-sensor fusion).
- Investigating the impact of larger-scale foundation models and more sophisticated augmentation strategies.
Conclusion
GFS-VL presents a principled approach to generalized few-shot 3D point cloud segmentation, leveraging the complementary strengths of 3D VLMs and few-shot supervision. The framework achieves state-of-the-art results on challenging benchmarks, demonstrating robust generalization and practical applicability. The proposed methods and benchmarks provide a solid foundation for advancing research in open-world 3D semantic understanding.