- The paper presents the VISE framework that reframes few-shot image classification and segmentation as a visual question answering task using VLMs and off-the-shelf vision tools.
- It employs pretrained models like YOLOv8x for object detection and SAM for segmentation, achieving superior mIoU scores on Pascal-5i and COCO-20i datasets.
- The modular design allows for seamless integration of additional vision-language models and tools, paving the way for future research in training-free FS-CS.
VLM-Based Few-Shot Image Classification and Segmentation
This paper introduces a novel Vision-Instructed Segmentation and Evaluation (VISE) framework that leverages Vision-LLMs (VLMs) and off-the-shelf vision tools to address the challenges of few-shot image classification and segmentation (FS-CS). The method reframes FS-CS as a Visual Question Answering (VQA) problem, enabling the VLM to utilize tools like YOLO and SAM for classification and segmentation, respectively, without requiring additional training. The authors demonstrate state-of-the-art performance on Pascal-5i and COCO-20i datasets.
Core Methodology
The VISE framework operates by first sampling an N-way K-shot FS-CS task. Query images are processed using YOLO to generate bounding boxes, which are then used to formulate a multi-choice VQA task for the VLM. The VLM, guided by visual prompting and in-context learning, identifies the bounding boxes corresponding to the target classes. Finally, SAM is employed to generate precise segmentation masks within the selected bounding boxes. The aggregation of these masks produces the final segmentation for the query image.
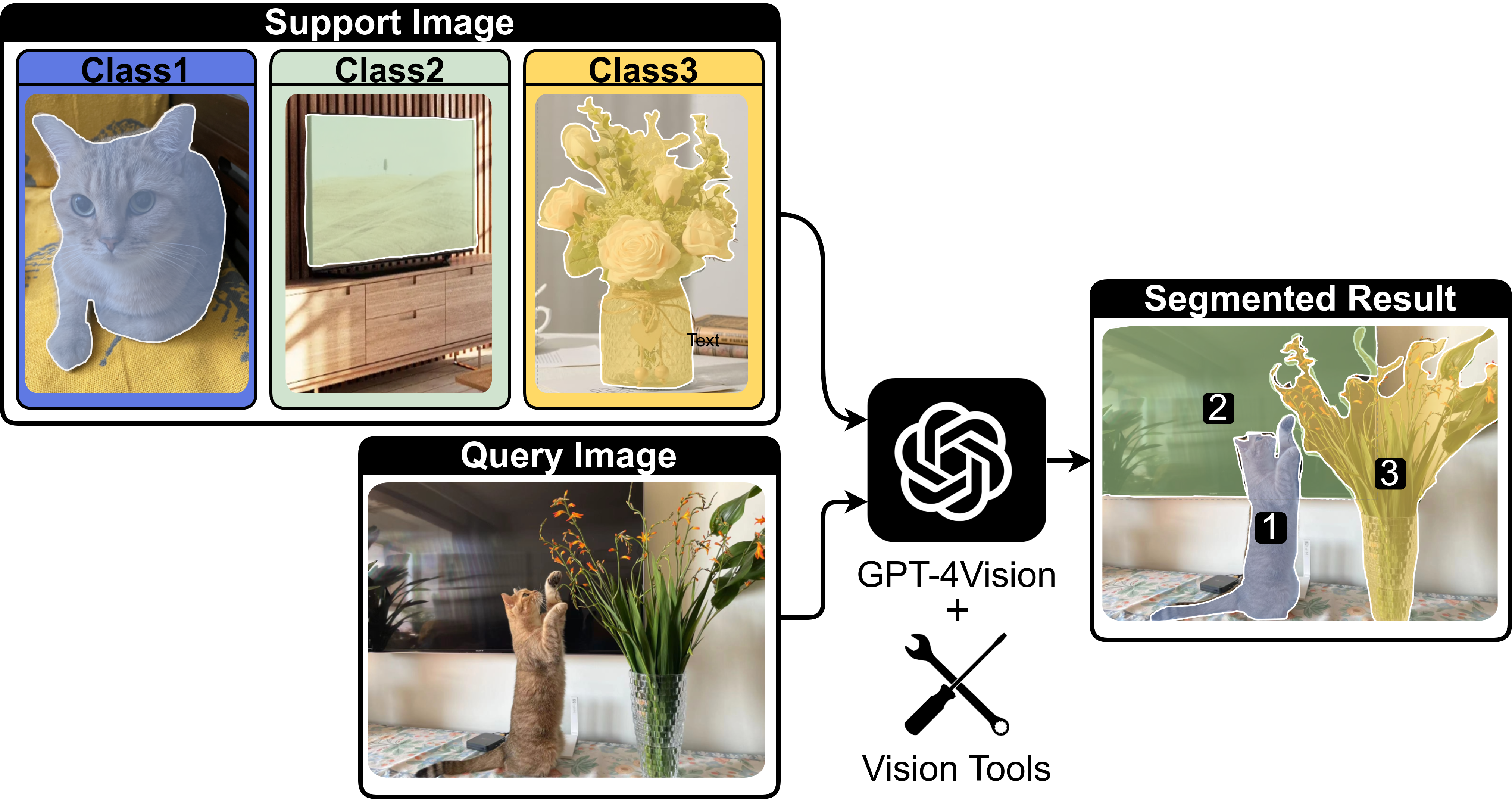
Figure 1: Few-Shot Classification Segmentation Task Solved by Vision LLMs, demonstrating the use of VLMs with vision tools for training-free FS-CS.
The VQA task formulation involves providing the VLM with detailed descriptions of the objects within each bounding box, along with contextual clues to aid in classification. This approach leverages the VLM's ability to learn from contextual cues and make informed decisions based on minimal supervision.
Implementation Details
The authors utilized pre-trained YOLOv8x for object detection and SAM VitH for segmentation. GPT-4Vision from OpenAI was used as the VLM, and the framework was implemented using LangChain. Experiments were conducted on an Nvidia RTX 4090 GPU, with a confidence threshold of 0.5 applied to the YOLOv8x bounding box proposals.
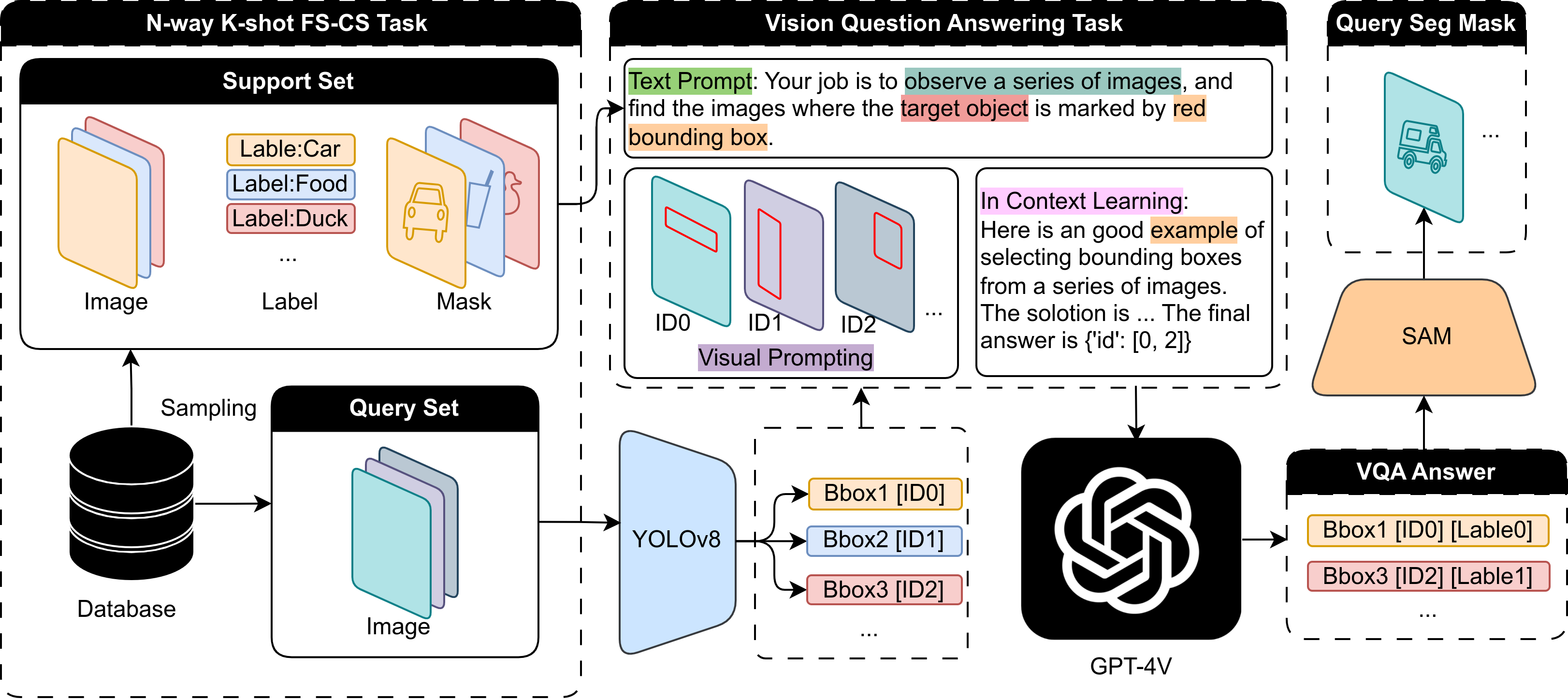
Figure 2: The VISE framework transforms FS-CS into a VQA task, utilizing VLMs and visual tools for classification and segmentation.
Experimental Results and Analysis
The VISE framework achieved state-of-the-art results on the Pascal-5i and COCO-20i datasets. On Pascal-5i, the method outperformed existing approaches in segmentation mIoU for both 1-way 1-shot and 2-way 1-shot settings (Table 1). Similarly, on COCO-20i, the framework demonstrated superior performance in segmentation mIoU, achieving 40.4% and 46.0% for 1-way 1-shot and 2-way 1-shot tasks, respectively (Table 2). Ablation studies showed that integrating specialized vision tools like YOLOv8 and SAM significantly improved performance compared to relying solely on the VLM for object detection and segmentation.

Figure 3: Example of a 2-way 1-shot FS-CS task in the COCO-20i dataset.
\textbf{The results showed a significant performance boost, particularly in segmentation tasks.} For example, the mIoU for the 2-way 1-shot task in COCO-20i is 46.0%.
Implications and Future Directions
The VISE framework offers a promising approach for addressing FS-CS tasks by leveraging the strengths of VLMs and readily available vision tools. The modular design of the framework allows for easy replacement or addition of vision models and VLMs, facilitating continuous improvement and expansion to new domains.
Future research directions could explore the use of more advanced VLMs, the incorporation of additional vision tools, and the development of more sophisticated VQA task formulations. Additionally, investigating methods for mitigating the impact of dataset noise and improving the robustness of the framework to challenging environmental conditions could further enhance performance. The integration of VLMs with high-performance vision tools offers a synergistic effect that significantly elevates the accuracy and reliability of FS-CS tasks.

Figure 4: VQA formulation for VLM, showing how the task is framed as a question-answering problem.
Conclusion
The VISE framework demonstrates the effectiveness of combining VLM reasoning with specialized vision models for FS-CS. By reframing the problem as a VQA task and leveraging tools like YOLO and SAM, the framework achieves state-of-the-art performance on benchmark datasets. This work contributes to the growing body of research on VLM-based methods for computer vision tasks and highlights the potential for future advancements in this area.