- The paper introduces a novel projector ensemble technique to decouple feature alignment and classification, enhancing knowledge distillation.
- It demonstrates up to 1% improvement in top-1 accuracy on CIFAR-100 and strong performance on ImageNet compared to conventional methods.
- The ensemble of diverse projector initializations reduces overfitting and improves the student network's generalization in CNN compression.
Improved Feature Distillation via Projector Ensemble
Knowledge distillation has emerged as a pivotal methodology for compressing large CNN architectures by transferring knowledge from a high-capacity "teacher" model to a more efficient "student" network. The paper "Improved Feature Distillation via Projector Ensemble" (2210.15274) introduces a novel approach by exploiting the role of feature projectors in the distillation process.
Projector Mechanisms in Feature Distillation
The study identifies a critical gap in existing feature distillation techniques: the insufficient exploration of projectors, which are often necessary to map differently dimensioned feature spaces of student and teacher networks. The authors postulate that even when student and teacher share identical feature dimensions, the inclusion of a projector can ameliorate performance by mitigating overfitting and enhancing feature discrimination.
Multi-task Learning Perspective
The authors posit that without a projector, the student is engaged in multi-task learning, simultaneously attending to discriminative feature extraction for classification and feature alignment for distillation. This dual focus can lead to feature entanglement, resulting in suboptimal classification performance. Adding a projector introduces an intermediary layer that segregates these learning tasks, allowing the student to prioritize feature extraction while adhering to the guidance from the teacher's feature space.
Ensemble of Projectors
Emphasizing the positive role of projectors, the paper further investigates the potential of projector ensembles to boost performance. The ensemble strategy leverages diverse initializations which create variance in feature transformation, a principle grounded in ensemble learning theory, thus enhancing the student's generalization abilities.
Experimental Validation
The method exhibits consistent improvements across a plethora of dataset and model configurations, notably with CIFAR-100 and ImageNet datasets. Using various teacher-student pairs such as ResNet and VGG architectures, the paper demonstrates not only superior performance over existing distillation methods but also robustness and convergence efficiency.
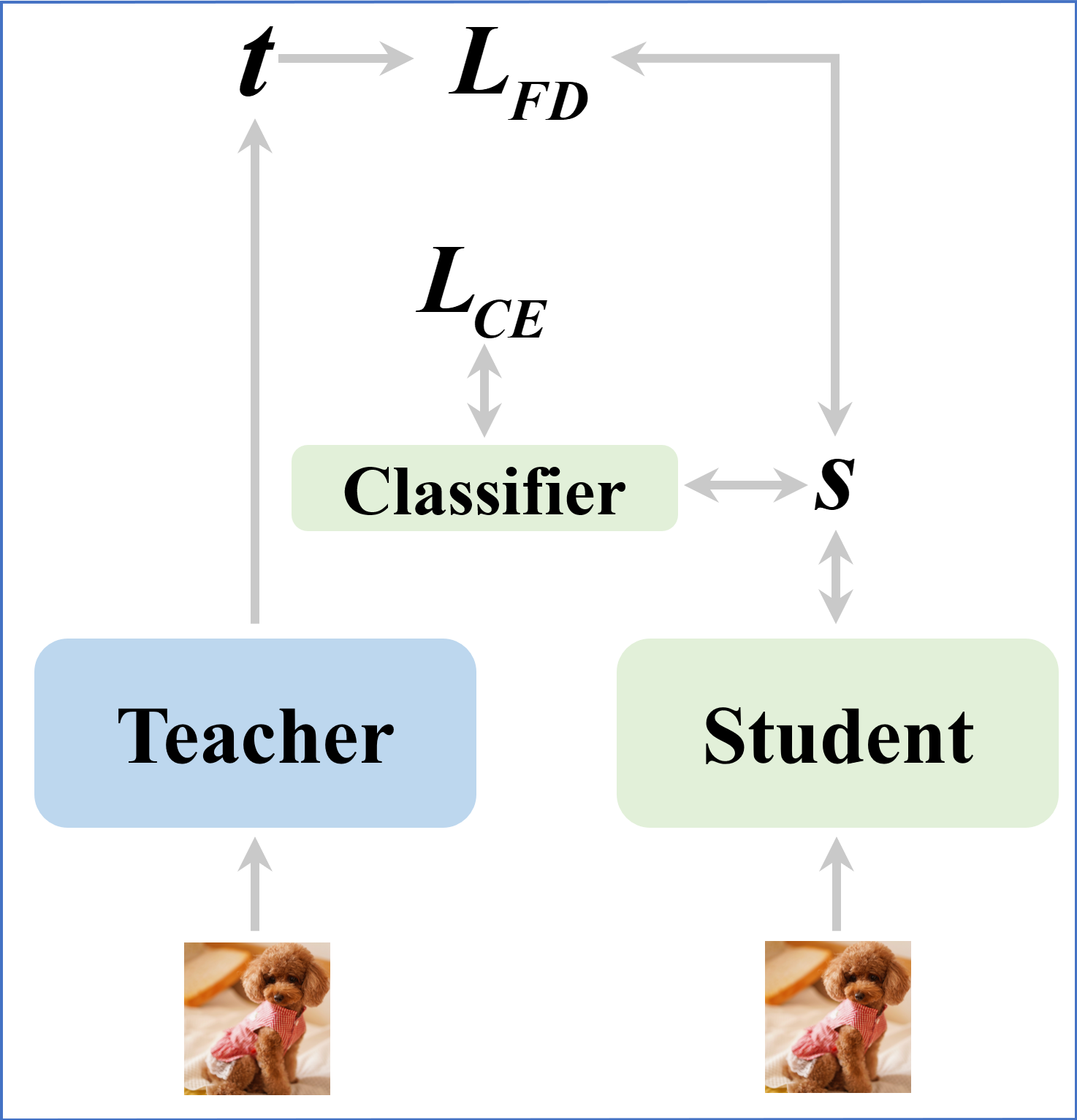
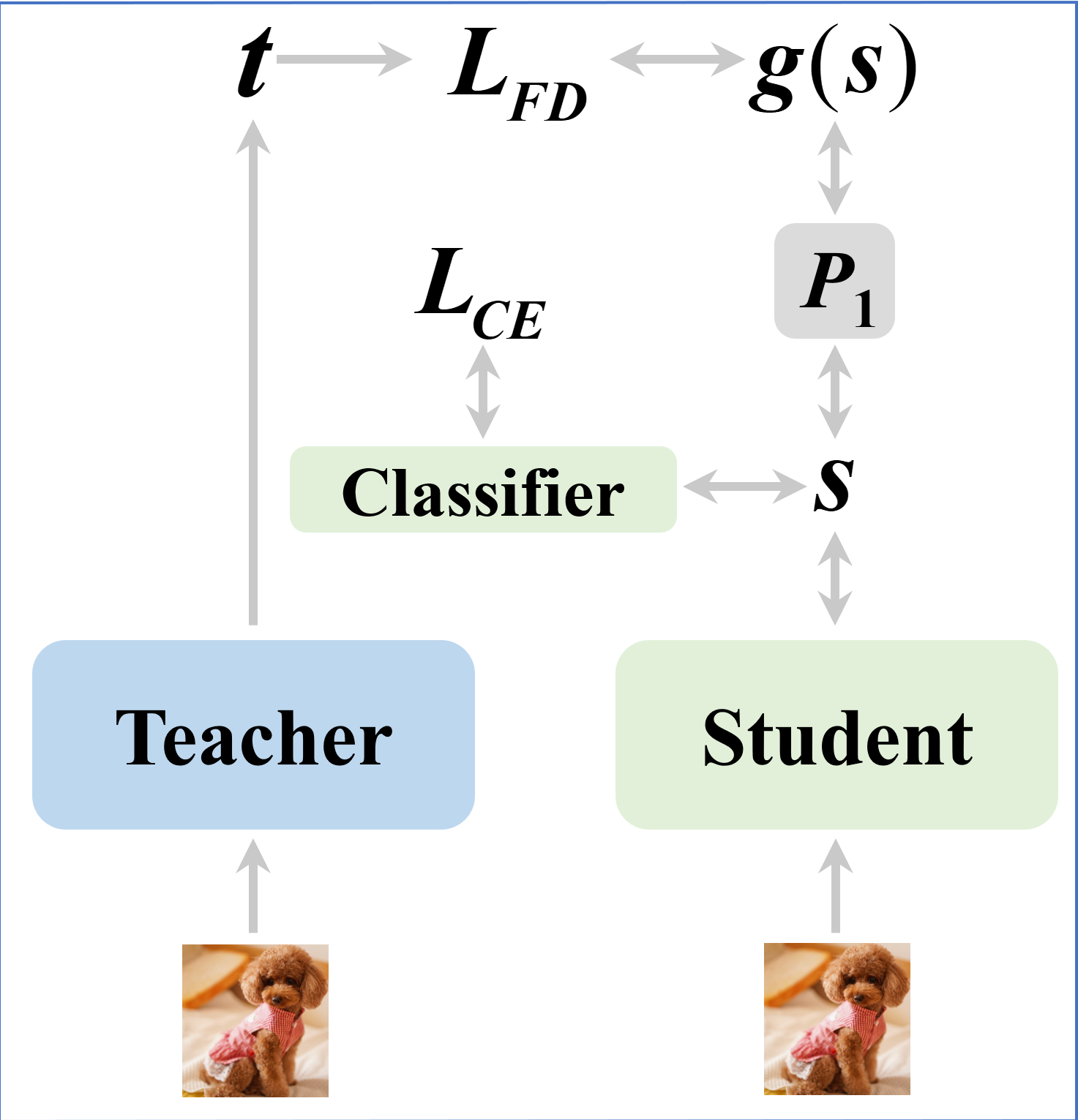
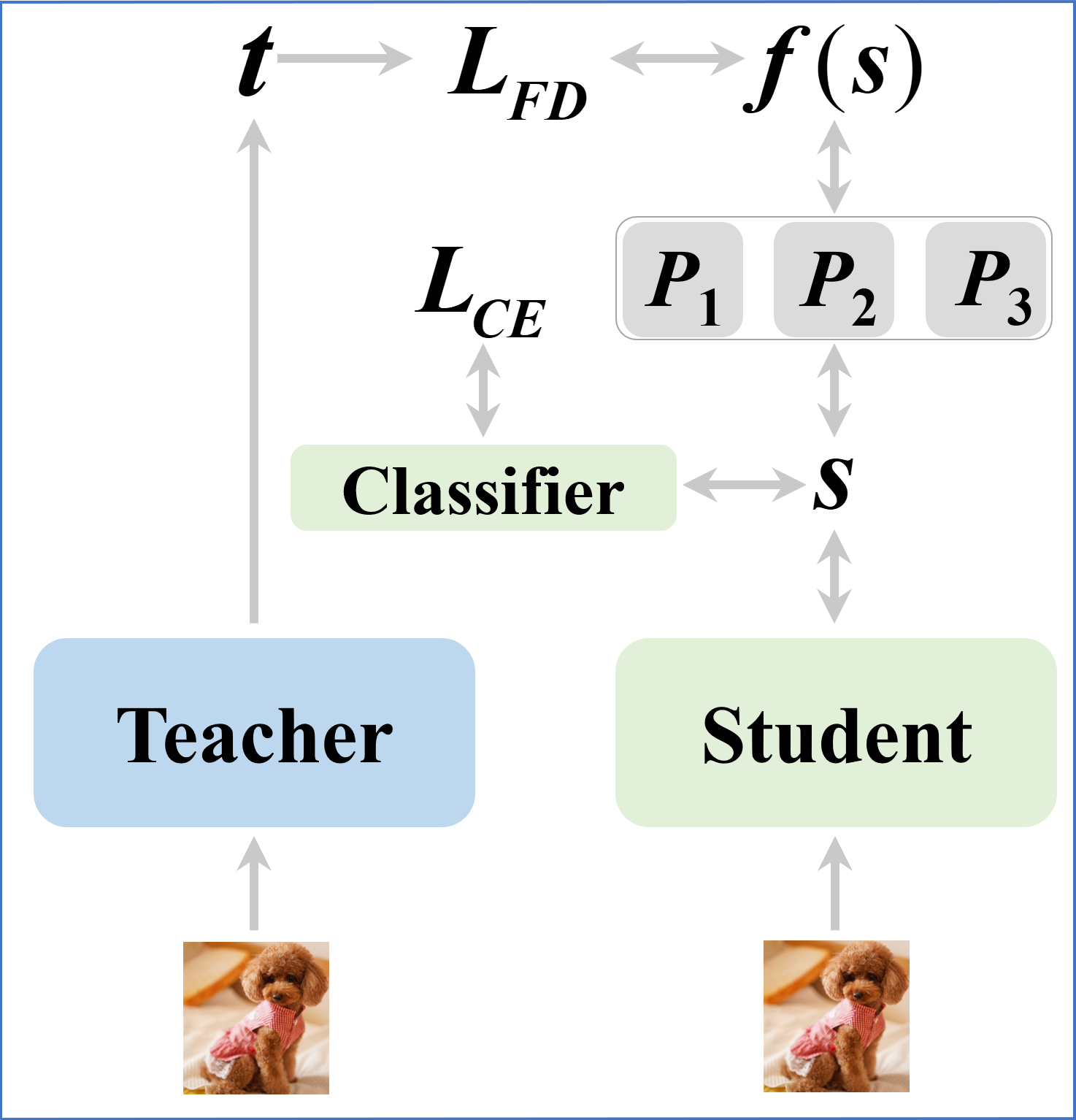
Figure 1: Illustration of (a) feature distillation without a projector when the feature dimensions of the student and the teacher are the same, (b) the general feature-based distillation with a single projector.
Evaluation and Comparison
Extensive experiments delineated in the paper reveal that the proposed framework surpasses conventional distillation methods including KD, CRD, and SRRL, with performance increments of up to 1% in top-1 accuracy on CIFAR-100. Moreover, results on ImageNet indicate that employing a projector ensemble can bridge the gap when distilling knowledge from high-performance teachers, like DenseNet201, to compact students like MobileNet.
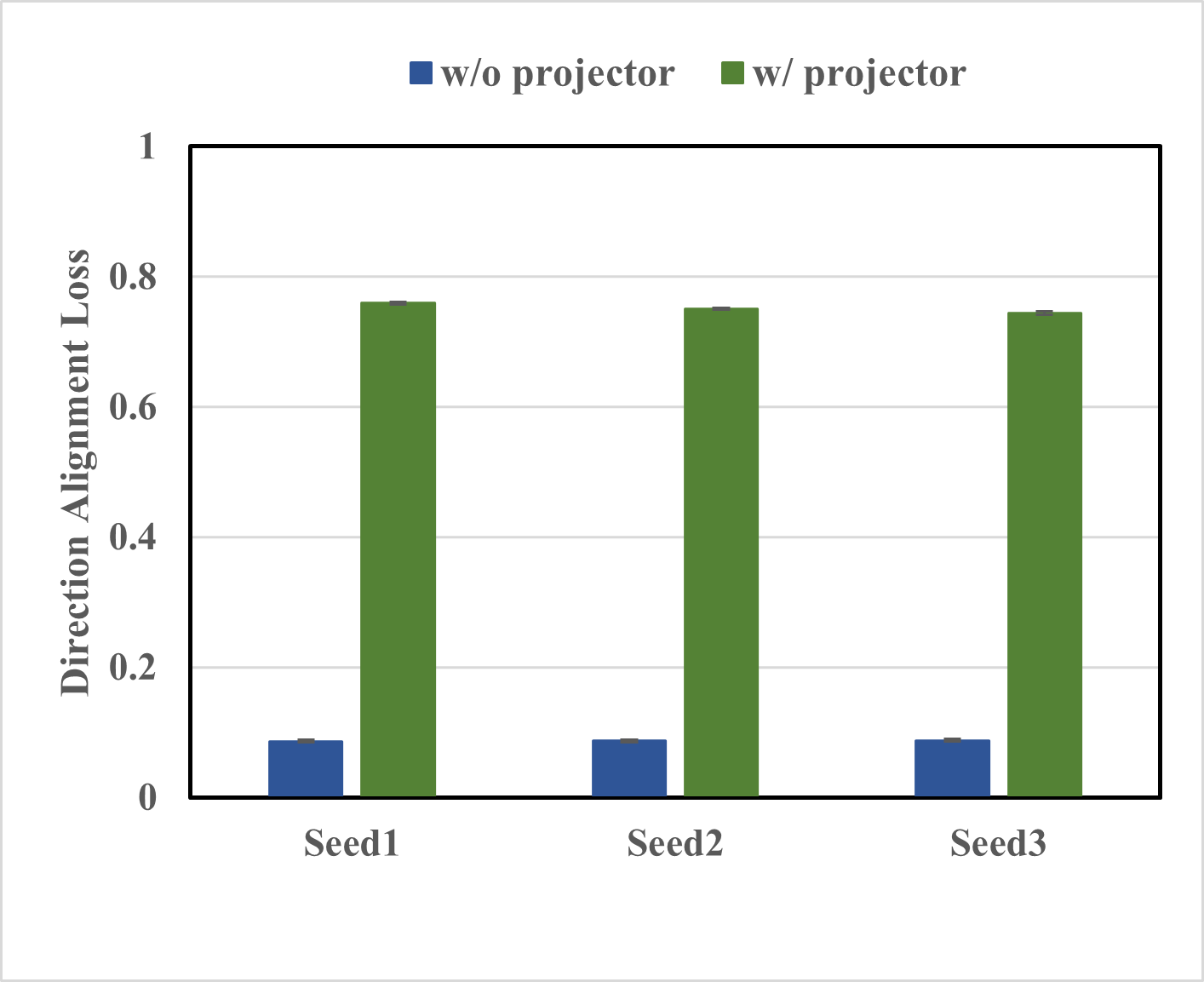
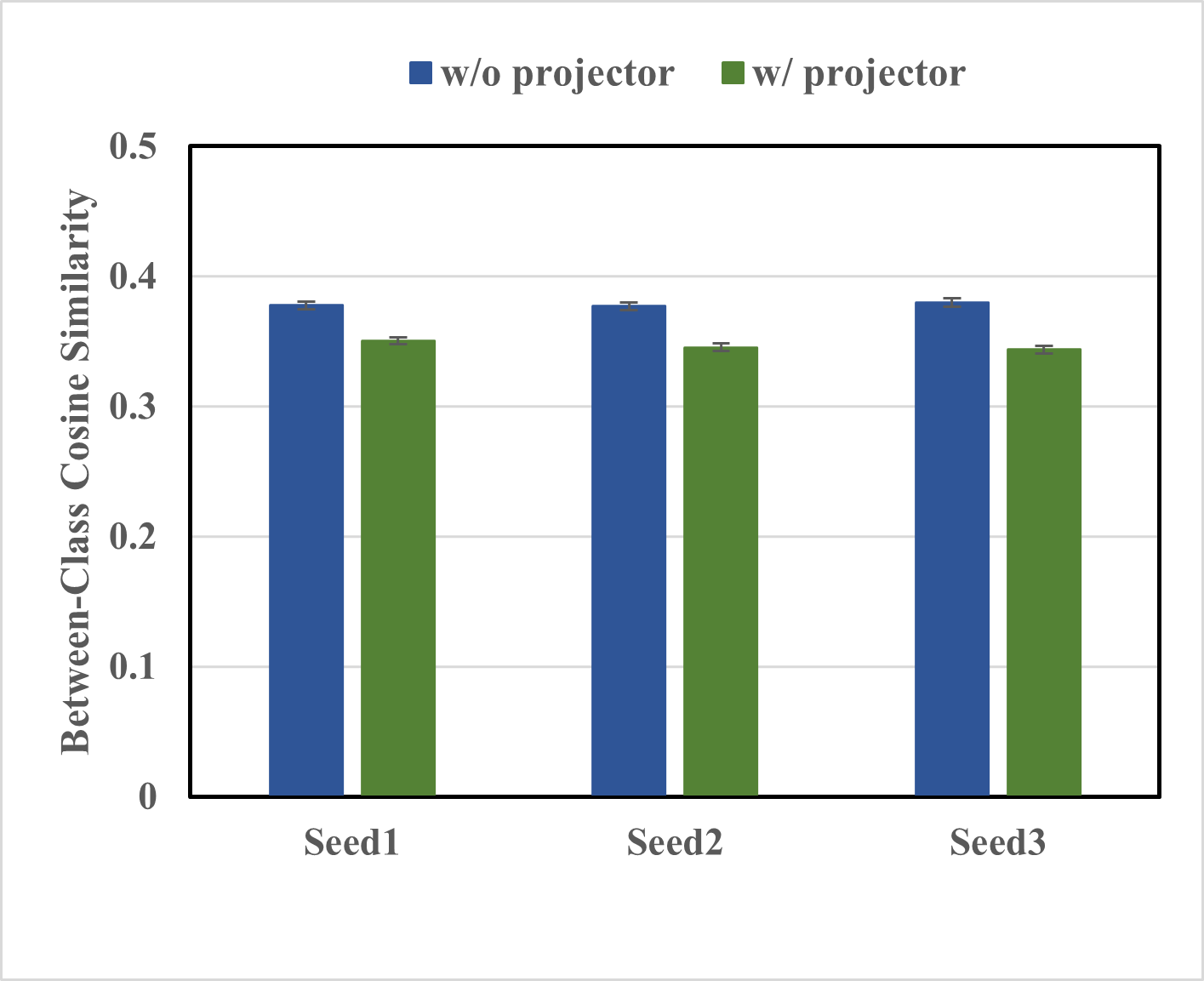
Figure 2: The left figure displays the direction alignment loss between teacher and student features with and without a projector. The right figure displays the average between-class cosine similarities in students' feature spaces.
The study underscores the efficacy of direction alignment loss, simplifying the distillation process by focusing solely on feature disparities. A comparative analysis reflecting top-1/top-5 accuracies robustly positions the projector ensemble method as a state-of-the-art solution.
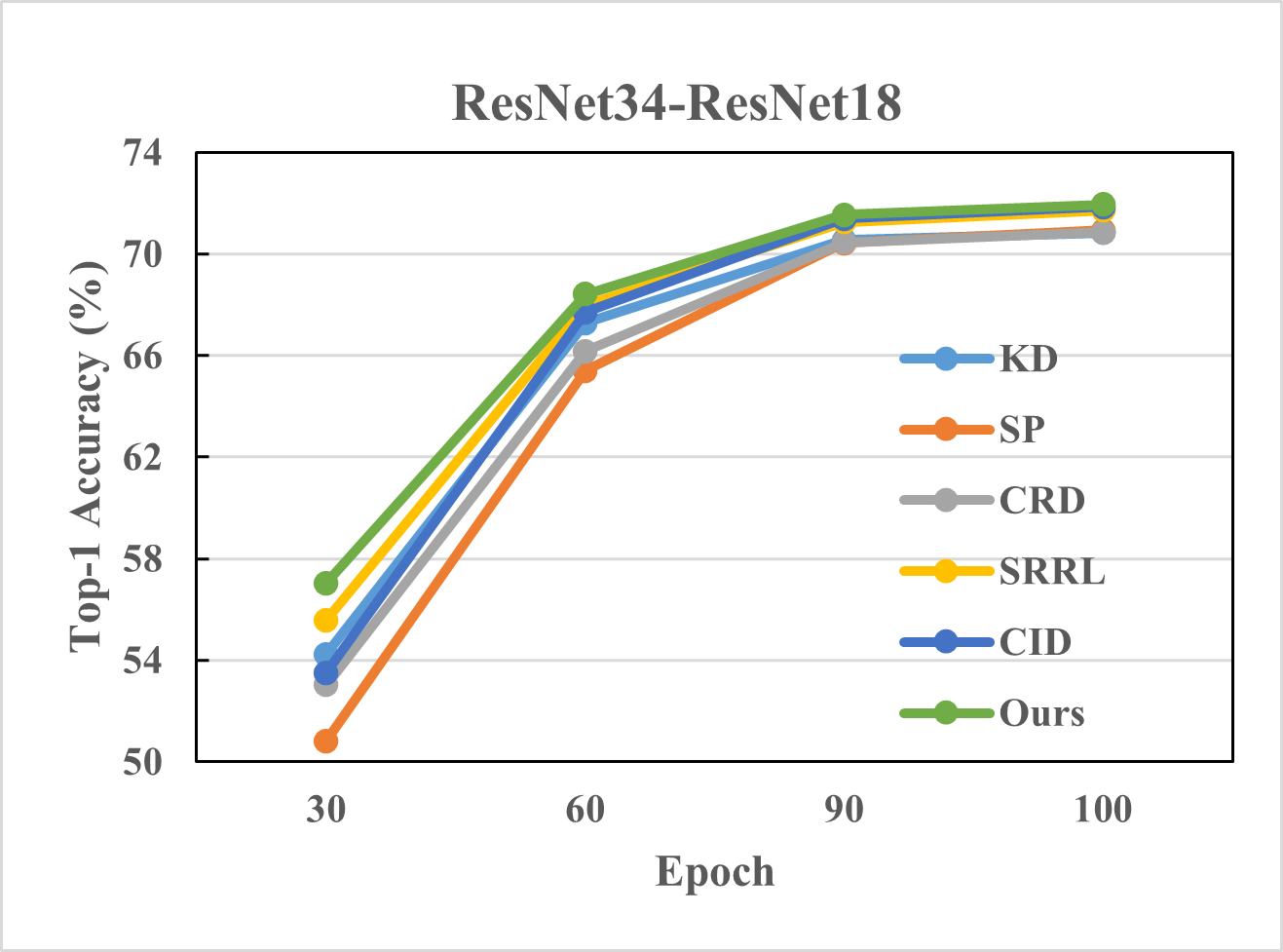
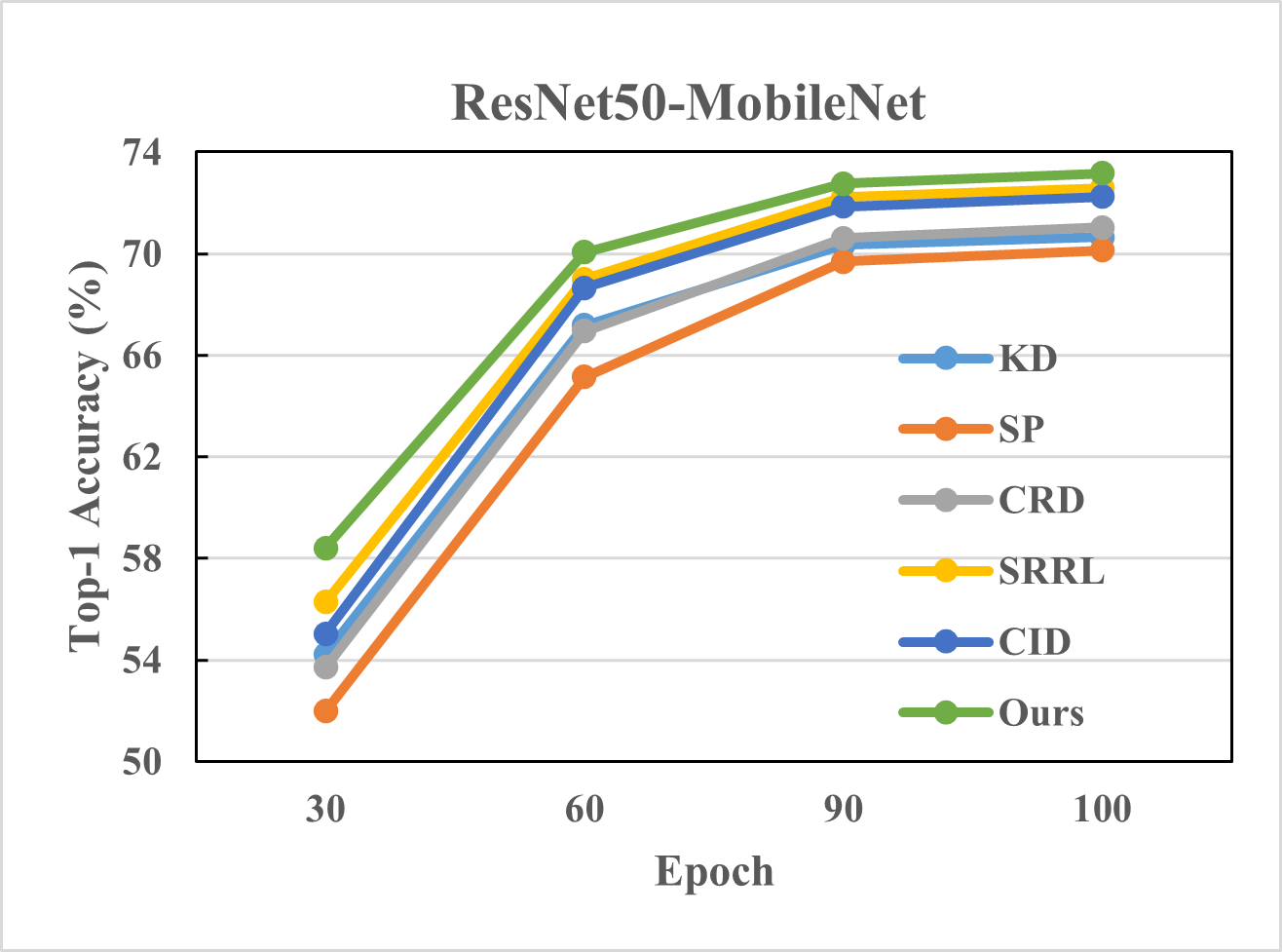
Figure 3: Top-1 accuracy of different methods on ImageNet with different number of epochs and different teacher-student pairs.
Projector Diversity
An intriguing observation is the convergence of projector diversity during training. The results suggest scalable potential in crafting diverse projectors via varied initialization schemes, further refined by regularization techniques.
Conclusion
The investigation into projector roles in knowledge distillation reveals substantial opportunities to enhance model compression techniques. By advancing the discourse with projector ensembles, the method paves a feasible path forward for improved performance and efficiency in neural network training and deployment. While the study primarily concentrates on image classification, broadening the application to other domains such as object detection remains an exciting future avenue.