- The paper introduces a multi-view contrastive learning framework for refining modality-specific representations in multimodal sentiment analysis.
- It combines supervised and self-supervised contrastive methods to enhance feature clustering and multimodal fusion efficiency.
- Experiments on CMU-MOSI, MOSEI, and CH-SIMS datasets show significant improvements in sentiment classification accuracy and correlation metrics.
Improving Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis
The paper explores modality representation learning in multimodal sentiment analysis (MSA) using a multi-view contrastive learning framework. This approach aims to enhance the discriminative power of modality-specific representations, addressing the limitations associated with conventional multimodal fusion methods.
Introduction to Multimodal Sentiment Analysis
Sentiment analysis is a crucial task in NLP, focusing on understanding emotional states through data. Traditional approaches centered on textual data have been extended to multimodal sentiment analysis, leveraging richer datasets that include spoken words, visual attributes, and acoustic features. Multimodal data offers a comprehensive understanding of emotions, especially when textual information is ambiguous.
Existing MSA methods largely focus on multimodal fusion. Early-fusion techniques combine features from various modalities immediately, while late-fusion strategies integrate results post independent modality training. Despite their efficacy, these strategies have yet to fully exploit cross-sample relations that could significantly boost representation distinguishability.
Multi-View Contrastive Learning Framework
Contrastive learning has notably improved representation quality by distinguishing similar and dissimilar samples in a shared embedding space. This paper introduces a three-stage framework to refine modality-specific representations:
- Supervised Contrastive Learning (SCL-1): Initial features are extracted using pre-trained models; these features are refined by pulling samples together within the same class and pushing others apart, enhancing their semantic cohesion.
- Self-Supervised Contrastive Learning (SSCL): Utilizing cross-modal Transformers, modality-specific representations are further refined. Self-supervised pairs are formed from different refinement orders to minimize representation gaps, thus enhancing modality interaction.
- Supervised Contrastive Learning (SCL-2): Final multimodal representations are achieved by self-attention mechanisms, ensuring a robust discriminative representation for sentiment classification tasks.
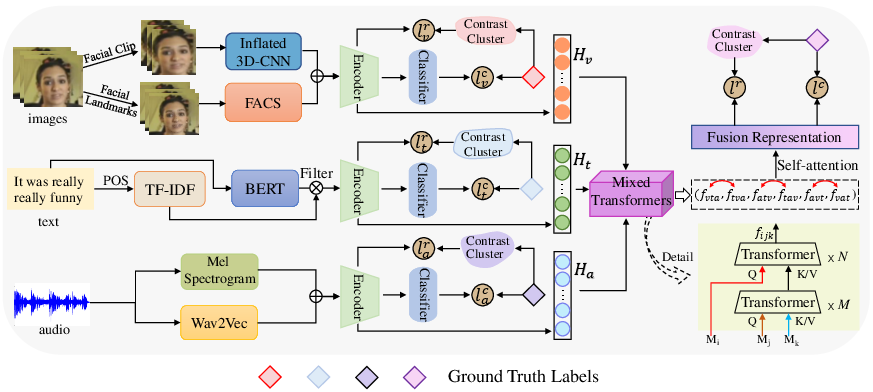
Figure 1: The overview of our proposed method.
Methodology
The framework combines supervised and self-supervised contrastive learning to enhance modality-specific and multimodal representations. The process involves extracting initial modality features, applying Transformers for temporal and spatial information, and implementing contrastive learning strategies to refine and fuse representations effectively.
- Video: Spatial and temporal features extracted using MTCNN and I3D.
- Text: BERT embeddings filtered by part-of-speech tags and enhanced using TF-IDF.
- Acoustic: Features derived using LibROSA and wav2vec2.0, capturing intricate audio nuances.
Contrastive Learning Application
SCL-1 facilitates unimodal representation clustering, utilizing a batch-based contrastive loss function. SSCL refines modality-aimed cross-modal representations via a novel cross-modal Transformer, enhancing feature interaction without requiring additional augmentations. SCL-2 synthesizes these refined multimodal representations, ensuring feature integrity and discriminative accuracy during multiclass predictions.
Experimental Evaluation
The framework's efficacy was tested on three datasets: CMU-MOSI, CMU-MOSEI, and CH-SIMS. Results demonstrate superior performance across multiple metrics such as F1 score, accuracy, MAE, and Pearson correlation when compared to existing fusion-based methods like TFN, LMF, MulT, and MISA. This shows that the proposed contrastive learning significantly improves modality representation quality.
Dataset and Results
- MOSI Dataset: Enhanced performance in most metrics, indicating effective representation refinement but showing slight limitation in accuracy.
- MOSEI Dataset: Overall improvement highlighting refined modality-invariant features.
- CH-SIMS Dataset: Demonstrated the model's adaptability across modality-specific tasks, maintaining high accuracy and correlation scores.
Conclusion
The multi-view contrastive learning framework successfully advances MSA by producing highly discriminative representations. This approach paves the way for improved sentiment analysis accuracy, emphasizing enhanced feature differentiation and interaction through contrastive methodologies. Future research may explore broader applications of contrastive learning across modalities and its integration with other feature extraction techniques.