- The paper introduces a novel skill-based RL framework that leverages demonstration datasets and VAE-embedded skills for efficient robotic manipulation.
- The method utilizes a state-conditioned skill prior to focus exploration and a residual policy for fine-tuning actions under new task conditions.
- Experimental evaluations across varied tasks show that ReSkill outperforms state-of-the-art baselines in sample efficiency and final performance.
Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics
Introduction and Background
The paper "Residual Skill Policies" introduces a novel framework for skill-based reinforcement learning (RL) tailored for robotic manipulation, leveraging prior knowledge from demonstration datasets to accelerate learning in new, unseen tasks. This approach emphasizes the use of skills, defined as short sequences of low-level actions, embedded into a latent space from which a high-level RL agent selects actions. Traditional skill spaces can be vast and inefficient to explore; thus, the paper proposes a method to focus exploration and adapt skills dynamically to cope with new task variations.
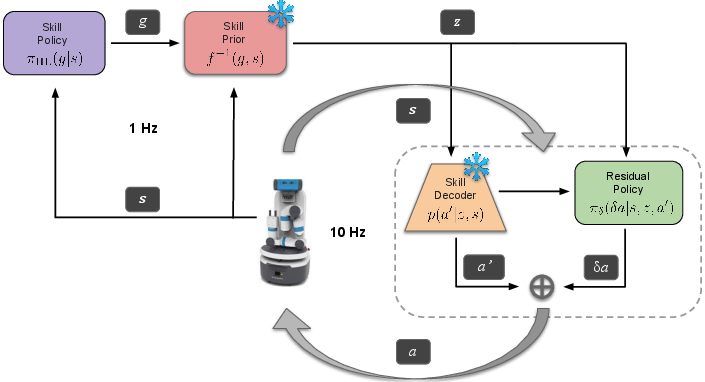
Figure 1: Residual Skill Policies (ReSkill). A skill-based learning framework for robotics.
State-Conditioned Skill Space and Skill Prior
The core innovation lies in a state-conditioned skill space that optimizes exploration by confining it to skills relevant to the current state. The method employs a Variational Autoencoder (VAE) to embed skills into a latent space, with a generative model to capture the conditional probability density that guides exploration efficiently. This multi-modal and expressive prior greatly enhances the utility of learnt skills, facilitating efficient exploration by focusing on high-probability skills pertinent to the state.
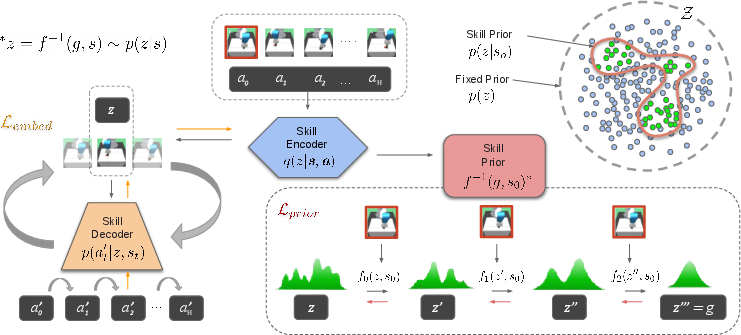
Figure 2: Schematic for learning the state-conditioned skill space.
Residual Policy for Skill Adaptation
Another critical component is a low-level residual policy that allows fine-tuning of skills in response to environmental variations. This policy adds flexibility, enabling adaptation of pre-composed skills when encountering unforeseen task conditions, effectively bridging the gap between high-level policy planning and the practical demand for fine-grained control adjustments.
Training and Evaluation
The proposed approach is validated across four manipulation tasks derived from robotic settings distinct from the training environments of skill extraction. These tasks involve both physical and dynamical deviations, testing the framework's ability to generalize and learn tasks efficiently with existing skill datasets. Performance comparisons with state-of-the-art baselines demonstrate the superiority of ReSkill in both sample efficiency and asymptotic performance.
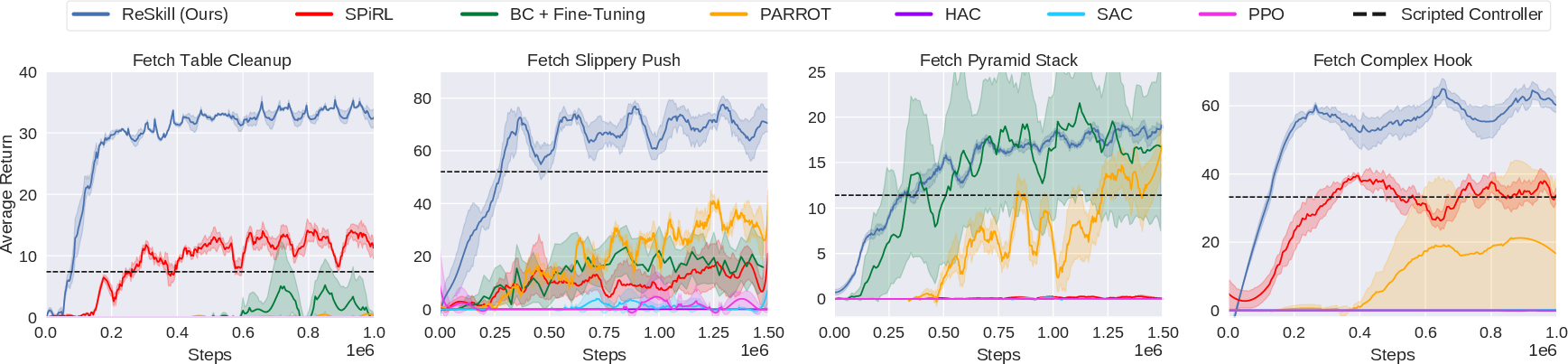
Figure 3: Training Performance. ReSkill outperforms baselines in sample efficiency and final policy performance.
Ablation Studies and Insights
The paper conducts extensive ablation studies to underline the importance of each system component. The state-conditioned skill prior shows significant improvement in exploration efficacy, while the low-level residual policy is crucial for adapting skills to variations, enabling the policy to reach higher reward states reliably even in challenging environments.
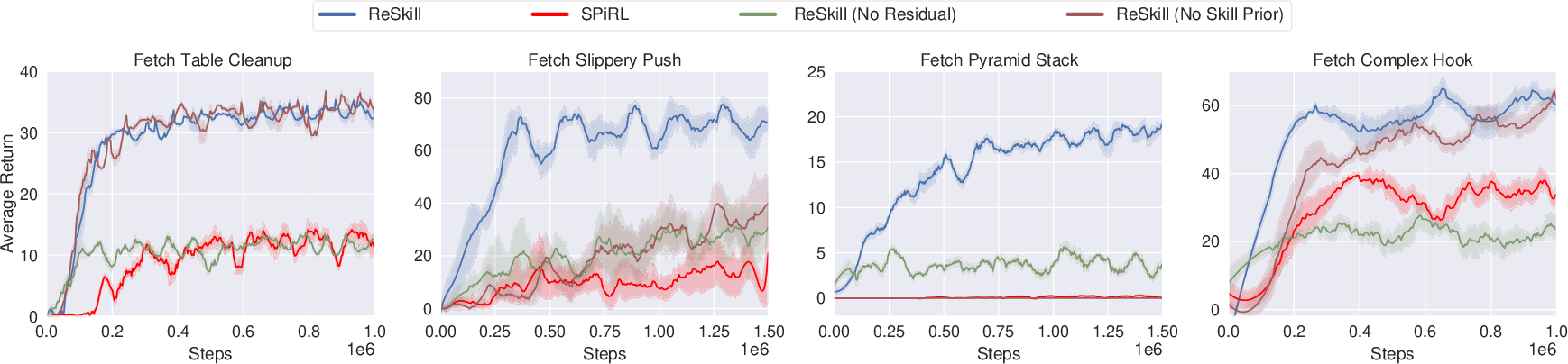
Figure 4: Ablation Study demonstrating the influence of the skill prior and residual policies.
Computational Requirements and Implementation Considerations
Implementing the ReSkill framework necessitates several training phases, including the skill embedding using VAE and the training of the normalising flow-based skill prior. The RL components, both high-level and low-level policies, are trained using on-policy algorithms, which, while requiring substantial environment samples, are stabilized by initializing without residual actions initially. Potential future work could explore integrating off-policy methods to improve sample efficiency further.
Conclusion
The ReSkill framework represents a significant advance in leveraging learned skills for robotic manipulation, showing robust performance across varied tasks without needing vast, task-specific datasets. This underscores potential applications in autonomous robotics where adaptability and efficiency are paramount. Future directions may include reducing sample complexity and expanding adaptation capabilities to further extend the framework's versatility across diverse robotic domains.