- The paper presents IRM as a novel framework that efficiently matches intrinsic rewards to extrinsic tasks using EPIC loss minimization.
- It employs task-agnostic skill pretraining and sequential skill compositions to significantly reduce environment interactions during task finetuning.
- Experimental results on robotic benchmarks demonstrate enhanced zero-shot performance and improved sample efficiency compared to traditional baselines.
Skill-Based Reinforcement Learning with Intrinsic Reward Matching
Introduction to Skill-Based Reinforcement Learning
Skill-based reinforcement learning focuses on developing agents that autonomously acquire useful behavioral primitives or skills in a task-agnostic manner. The paper introduces Intrinsic Reward Matching (IRM), a methodology that bridges unsupervised skill discovery and downstream task-specific finetuning by utilizing the learned intrinsic reward signal from the skill discriminator. Unlike conventional methods that discard the discriminator during finetuning and rely on environment interactions to find optimal skills, IRM leverages this intrinsic reward signal to efficiently match and select appropriate skills for new tasks without requiring samples from the environment.
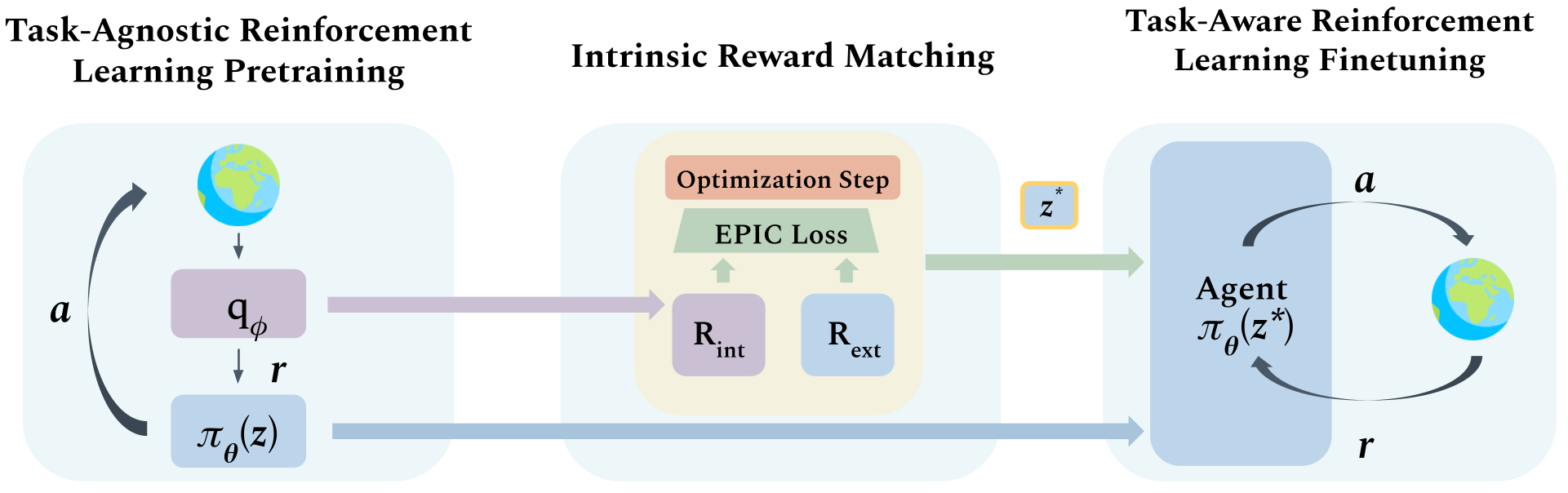
Figure 1: Intrinsic Reward Matching (IRM) Framework: Task-agnostic RL pretraining learns skill primitives with a skill discriminator.
Framework and Methodology
IRM operates through three sequential stages: task-agnostic skill pretraining, intrinsic reward matching, and task-specific finetuning. During pretraining, agents learn various skill policies which inform a skill discriminator capable of determining intrinsic rewards.
The core innovation of IRM is the utilization of the discriminator's learned intrinsic reward function to match extrinsic rewards of an unseen task, thus selecting the most semantically aligned skill without interacting with the environment. The reward alignment is quantified using the EPIC loss, a metric for measuring the proximity of reward functions, ensuring that equivalent-policy invariance is maintained.
Algorithmic Implementation
IRM’s practical implementation can significantly boost sample efficiency by pre-sampling canonical and Pearson distributions during skill selection, enabling a swifter reward matching process. The selection of skills through EPIC loss minimization can be configured using techniques like gradient descent or Cross-Entropy Method (CEM), adhering to constraints of minimizing environment samples during skill selection.
IRM's generalization capacity to complex tasks is manifested in sequential skill compositions where multiple skills are selected to address long-horizon tasks. This capability supersedes traditional hierarchical RL methods requiring manager policies, streamlining joint finetuning of selected skills.
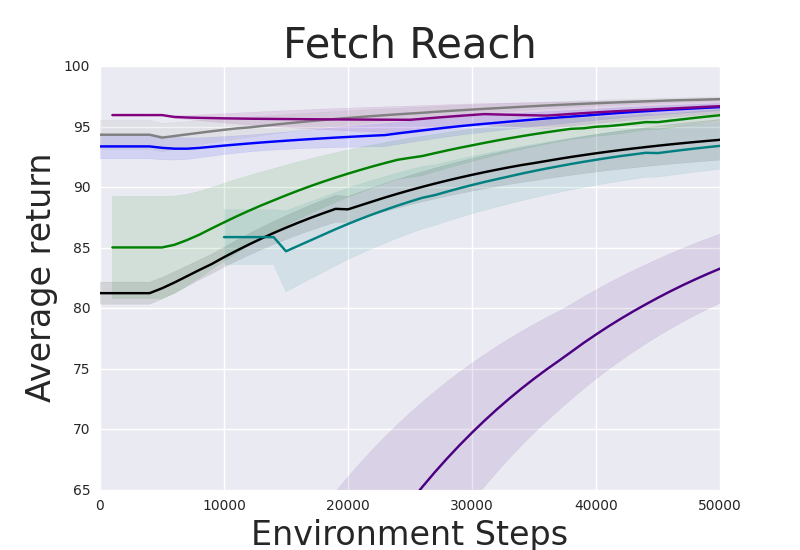
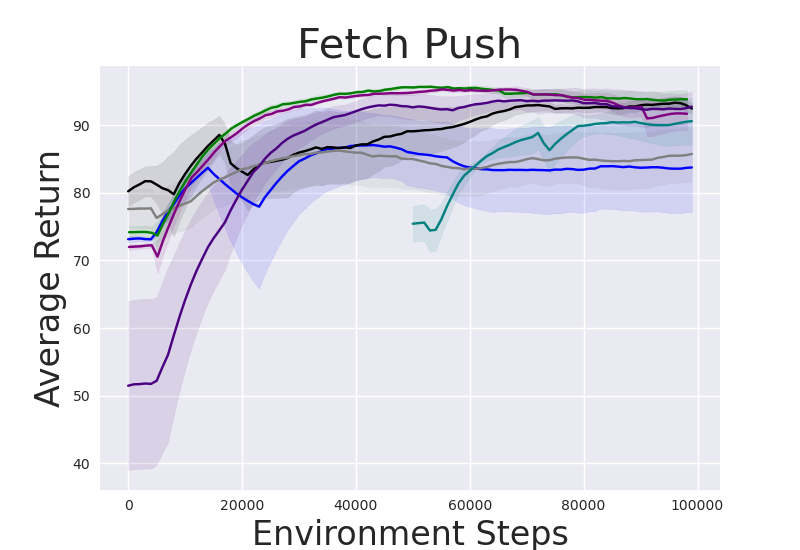
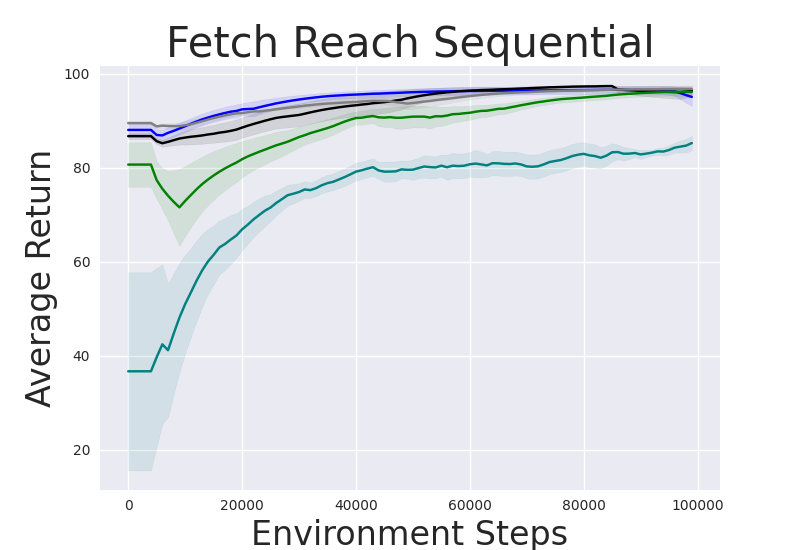
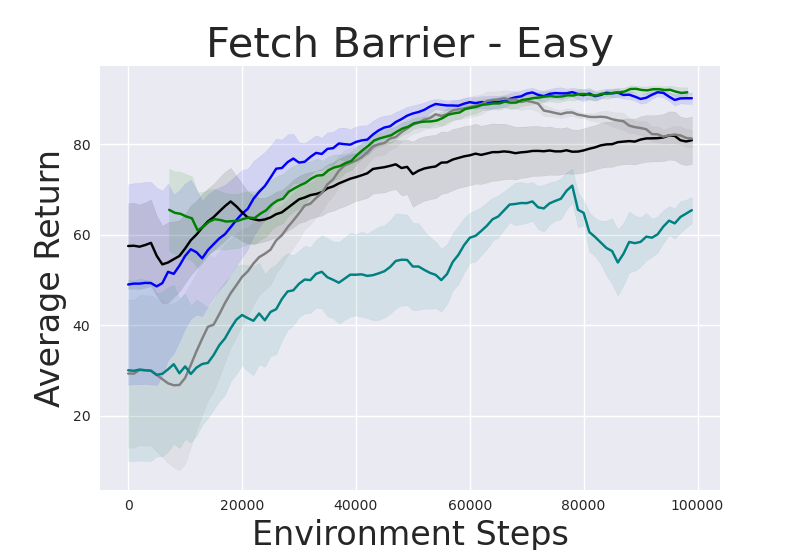

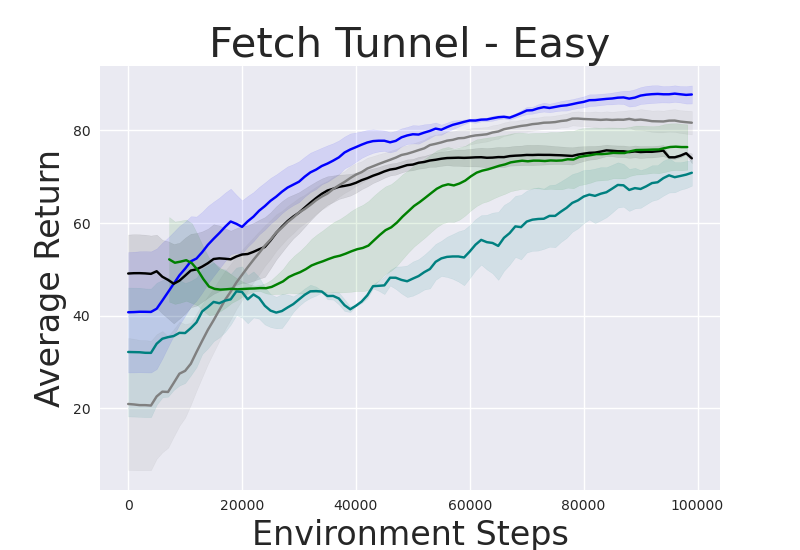
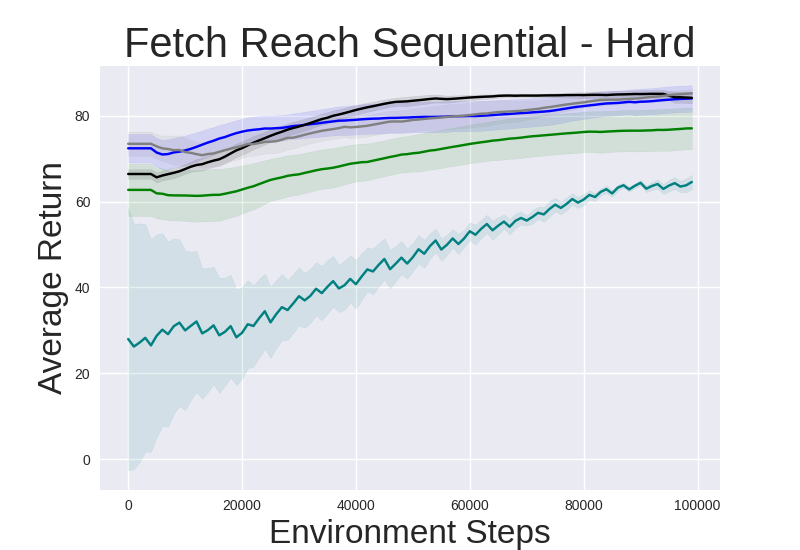
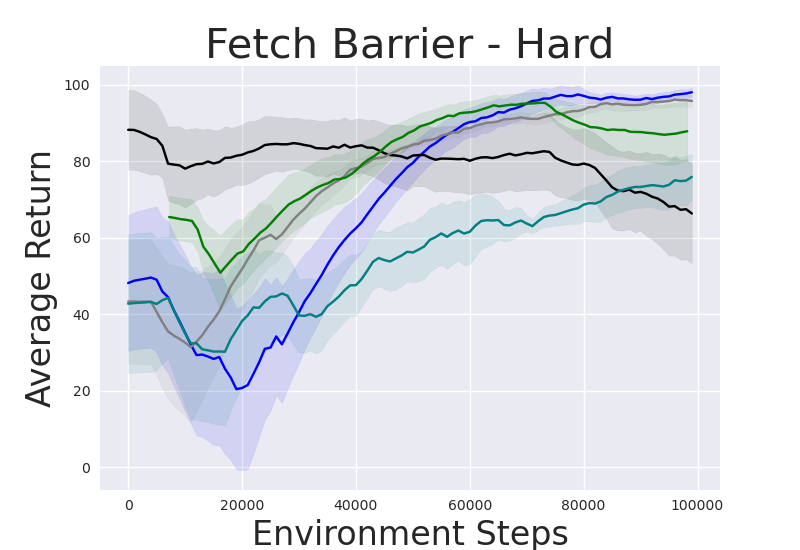
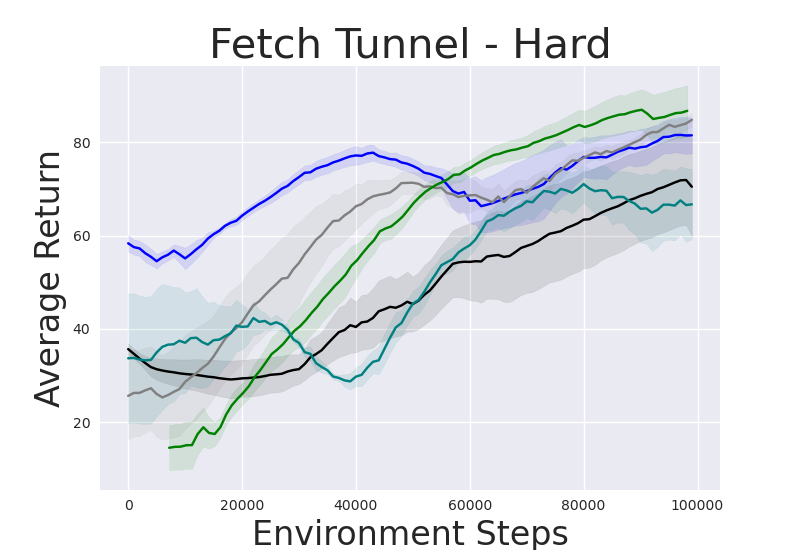

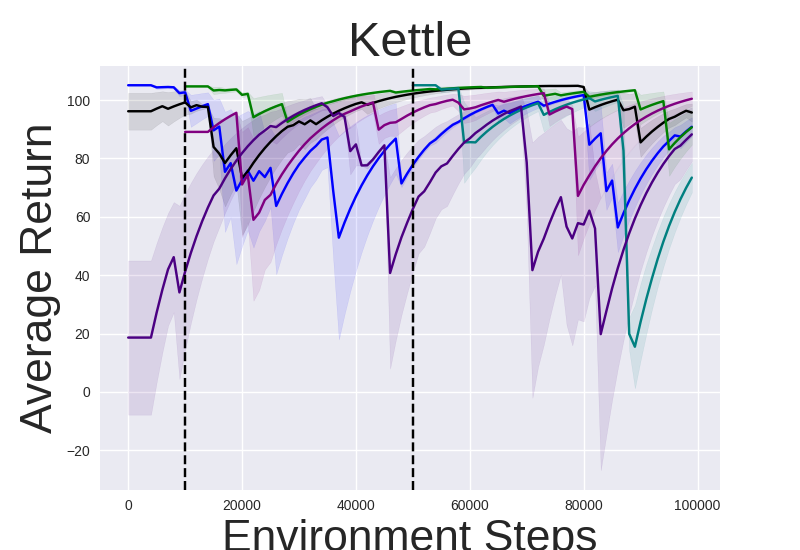
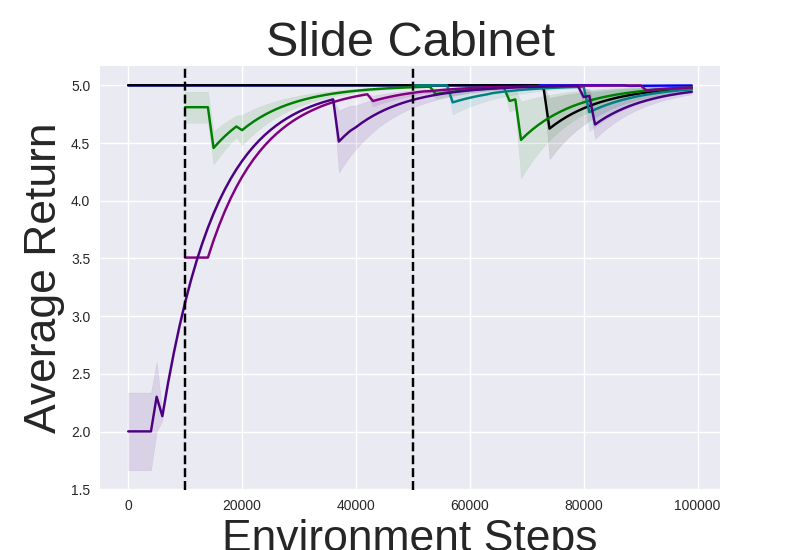
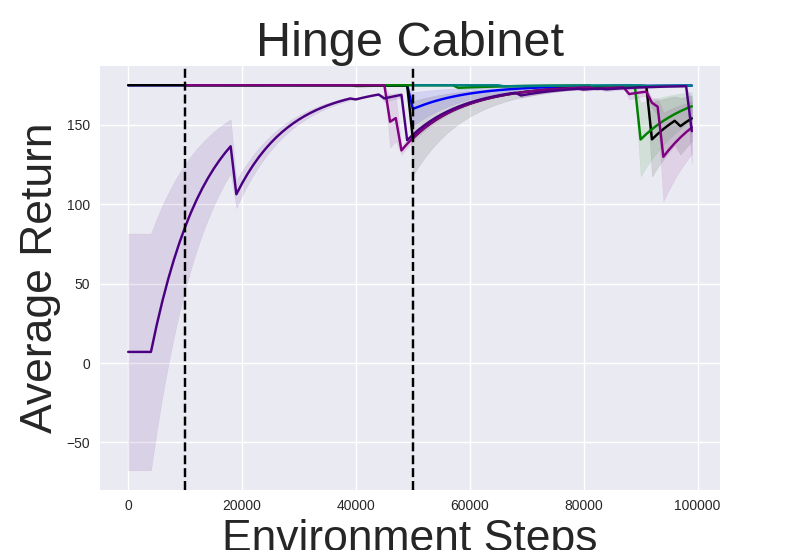
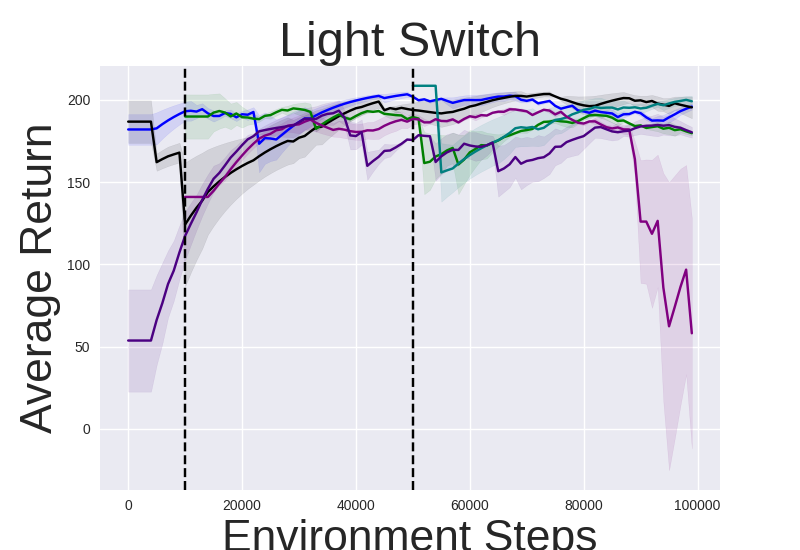

Figure 2: Performance gap illustrating the efficiency of IRM-based methods compared to random skill selection.
Experimental Validation
IRM demonstrates superior performance across various robotic manipulation tasks, including Fetch Robot and Franka Kitchen benchmarks. The validation against baseline methods showcases enhanced zero-shot and finetuning sample efficiency. IRM's ability to perform skill selection without environment interaction allows for efficient task adaptation, valuable in domains where sample collection is costly.
Notably, IRM’s zero-shot adaptation effectively deploys pretrained skills for instant task resolution in manipulation settings, reducing the inherent exploratory burden in reinforcement learning tasks.
Analysis and Interpretations
Insightful analyses confirm the negative correlation between the EPIC loss and extrinsic reward, validating EPIC loss as a reliable proxy for optimal skill selection. Skill trajectories associated with lower EPIC losses adequately demonstrate the desired behaviors on unseen tasks, affirming the efficiency of interaction-free skill identification.
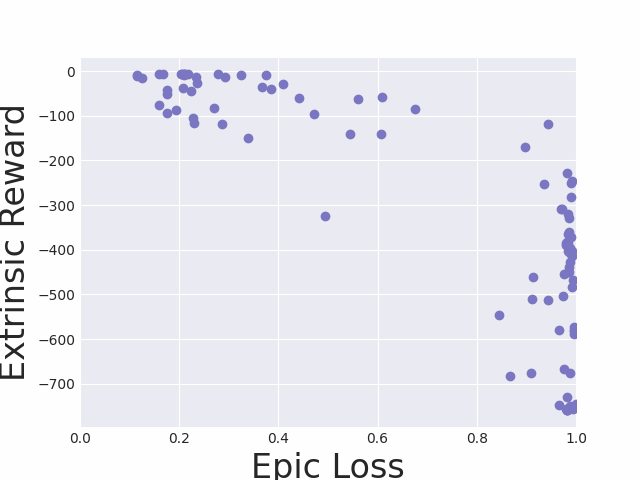
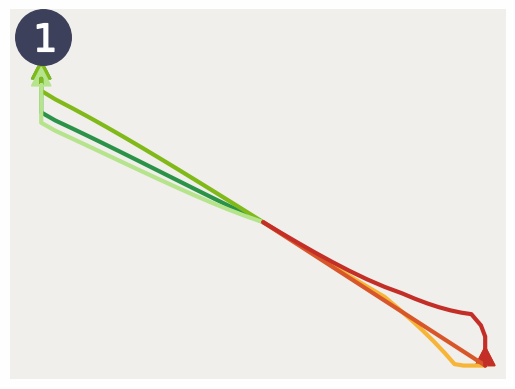
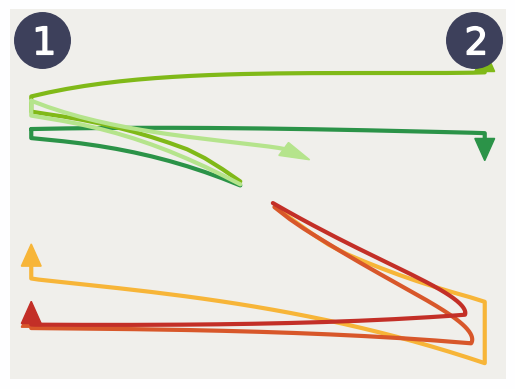
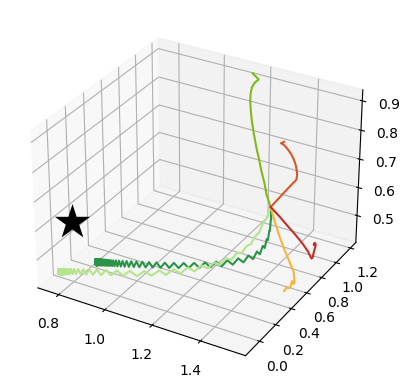




Figure 3: Visualizations linking EPIC loss with reward signal, displaying trajectories across planar goal-reaching tasks.
Implications and Future Directions
The IRM framework proposes a pivotal shift towards sample-efficient reinforcement learning, promoting interaction-free skill selection in both short and long horizon settings. While IRM effectively relies on known reward functions, potential future directions include investigating generative models for reward inference and exploring improved approximations of environment samples through learned models.
IRM could integrate seamlessly with online meta-learning strategies, broadening its applicability to scenarios with dynamic reward function specifications. This evolution presents promising prospects for robust AI deployments in real-time, resource-constrained environments.
Conclusion
IRM introduces a cohesive framework unifying skill-based pretraining and task-specific adaptation within reinforcement learning, exhibiting substantial enhancement in sample efficiency through its novel use of intrinsic reward signals. As IRM sheds conventional skill selection paradigms reliant on environment interactions, it establishes an innovative precedent for scalable reinforcement learning applications, poised to advance the integration of AI in practical, task-driven domains.