- The paper presents a novel contrastive learning pipeline that integrates audio and language modalities using feature fusion and keyword-to-caption augmentation.
- It demonstrates state-of-the-art performance in text-to-audio retrieval and classification tasks on the large-scale LAION-Audio-630K dataset.
- The study effectively handles variable-length audio inputs by fusing both global and local features, paving the way for robust model generalization.
Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
This paper addresses the challenge of developing effective audio representations by utilizing contrastive learning in a multimodal context involving audio data and natural language descriptions. The study introduces a novel pipeline for contrastive language-audio pretraining that incorporates feature fusion and keyword-to-caption augmentation to enhance model performance across various tasks.
Introduction
While audio data is ubiquitous, effective representation learning is hindered by the labor-intensive annotation process, posing challenges in leveraging large-scale datasets. The contrastive learning paradigm, particularly inspired by CLIP, offers a promising approach by matching data in a shared latent space to overcome these limitations. This work extends such methodologies to audio and language domains, aligning natural language descriptions with corresponding audio data.
Dataset and Methodology
LAION-Audio-630K
The research introduces LAION-Audio-630K, comprising 633,526 audio-text pairs from multiple sources. This large-scale dataset, enhanced through keyword-to-caption augmentation, serves as a foundational resource for training models in an unsupervised manner, promoting richer, more versatile audio representations.
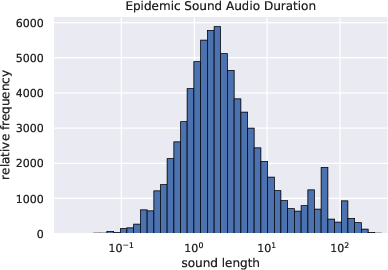
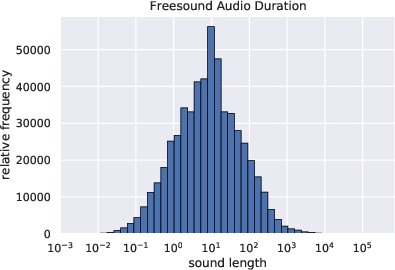
Figure 1: The audio length distribution of Epidemic Sound.
Model Architecture
The proposed architecture synergizes audio and text encoders to facilitate robust training on audio-text pairs. The audio encoder options include PANN and HTSAT, while BERT, RoBERTa, and CLIP transformer serve as text encoders. These encoders project their respective modalities into a shared space for contrastive learning.
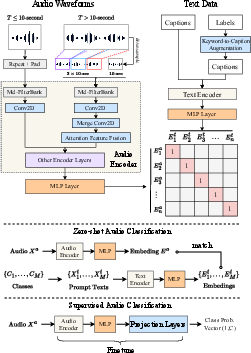
Figure 2: The architecture of our proposed model, including audio/text encoders, feature fusion, and keyword-to-caption augmentation.
Feature Fusion
To accommodate variable-length audio, the feature fusion technique integrates both global and local audio features, ensuring efficient processing and model performance. This mechanism is essential for handling diverse input lengths, which is pivotal for realistic audio applications.
Experimental Results
Text-to-Audio Retrieval
The proposed model, utilizing HTSAT-RoBERTa, demonstrates superior performance in text-to-audio retrieval tasks compared to existing benchmarks. The results highlight the efficacy of both large-scale data and innovative training methods like feature fusion and data augmentation.
Audio Classification
The model exhibits strong zero-shot and supervised classification capabilities across multiple datasets, achieving state-of-the-art results in tasks involving environmental sounds and complex audio data.
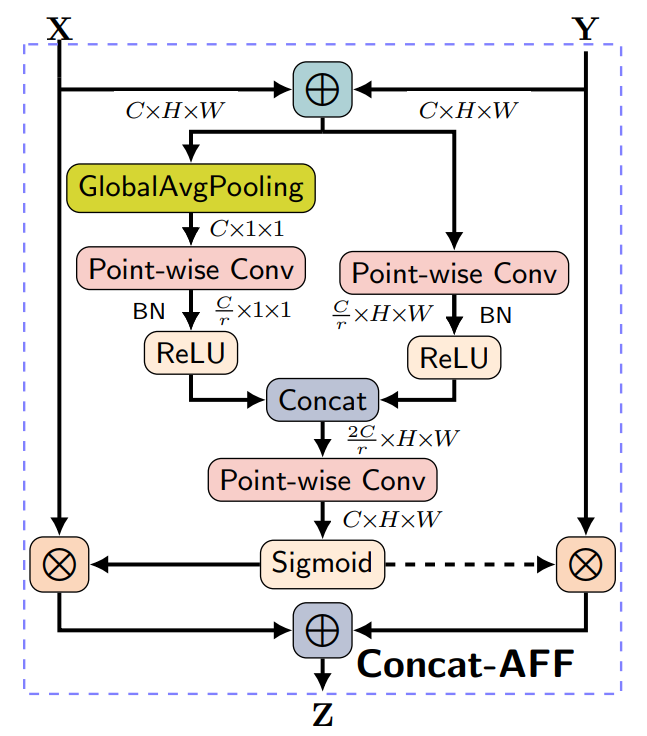
Figure 3: The attentional feature fusion architecture from \cite{aff}.
Conclusion
The study successfully advances the field of audio-text representation learning through extensive use of contrastive methods and dataset augmentation. The integration of keyword-to-caption augmentation notably enriches the dataset, paving the way for enhanced model generalization. Future research will explore broader dataset applications and refine the model for more downstream audio tasks.
In summary, the paper evidences the potential of large-scale contrastive language-audio pretraining in bridging the gap between audio and language modalities, offering significant improvements in both retrieval and classification tasks.