- The paper presents a novel audio-language pretraining framework using the diverse CaptionStew dataset to overcome limitations in data scale and caption diversity.
- It systematically compares contrastive and captioning objectives, showing that contrastive methods excel at linear probing while captioning scales better for intricate language tasks.
- The research reaffirms audio-language pretraining as a competitive approach for general-purpose audio representation, with broad applicability across audio domains.
"Revisiting Audio-language Pretraining for Learning General-purpose Audio Representation" (2511.16757)
Introduction
Audio-language pretraining represents a promising yet underexplored avenue for general-purpose audio understanding. This study identifies significant limitations in current audio-LLMs, primarily focusing on their restricted scope as efficient general-purpose encoders compared to their vision-language counterparts like CLIP. The paper introduces three key challenges in audio-language pretraining: limited large-scale audio-text corpora, a lack of caption diversity, and insufficient systematic exploration and evaluation. To address these, the authors present CaptionStew, a comprehensive 10.7 million caption dataset sourced from diverse audio-text corpora, and provide a thorough evaluation of contrastive and captioning objectives for audio representation learning. The key contributions of this paper are systematic data-scaling experiments and analyzing performance across varied audio-related tasks, establishing that audio-language pretraining is competitive in this domain.
Language-Audio Pretraining
The paper explores two principal methodologies for audio-language pretraining: contrastive and captioning objectives (Figure 1). Contrastive pretraining aligns audio and textual representations in a shared embedding space using a symmetric InfoNCE loss. It optimizes model training by maximizing similarity between paired samples and minimizing it between non-paired samples. This method enhances data efficiency, demonstrating superior performance, particularly at smaller scales. Conversely, the captioning objective takes a generative approach, focusing on generating textual descriptions from audio. It offers dense token-level supervision, aligning well with developing trends in comprehensive audio understanding systems and scaling better in language-involved audio tasks.
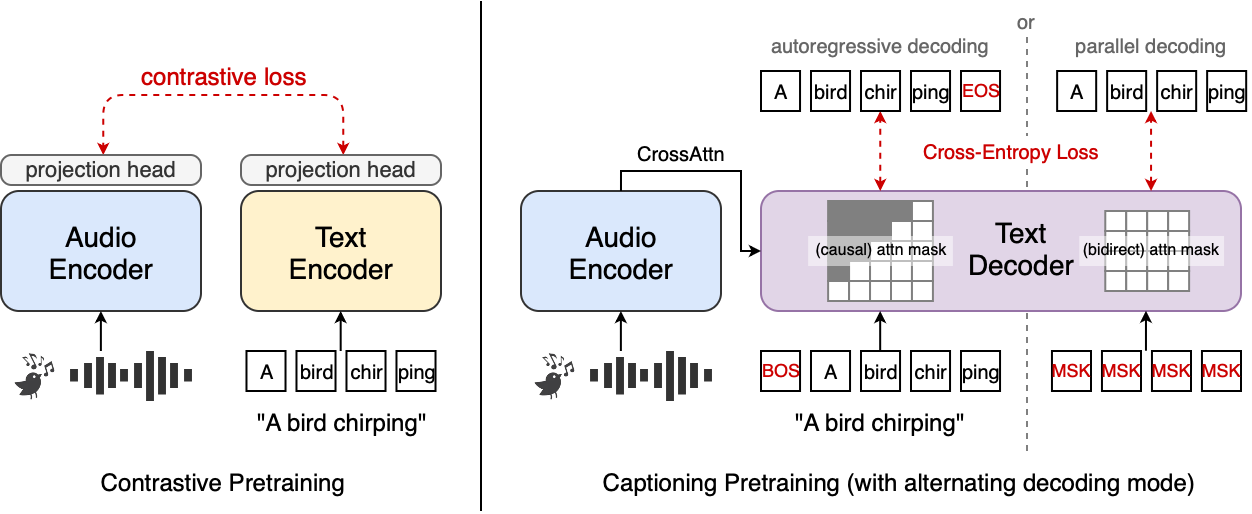
Figure 1: Audio-language pretraining objective studied in this work: contrastive and captioning.
CaptionStew Dataset
The authors address the limitations of existing audio-caption datasets by introducing CaptionStew, an extensive dataset compiling 9.3 million audio samples with 10.7 million captions. This dataset spans multiple domains, such as speech, music, and environmental sounds, enhancing both the scale and diversity necessary for robust model training. CaptionStew emphasizes the importance of caption diversity and semantic richness, drawing from various established open-source corpora. These include Audiocaps and WavCaps, among others, ensuring broad coverage of audio-related semantics. This diverse dataset serves as a foundation for evaluating model performance across different pretraining objectives.
Experimental Setup
The experimental framework leverages the Zipformer-M architecture (Figure 2) for audio encoding, chosen due to its efficiency with long sequences and rapid convergence. The model evaluation spans three primary protocols: linear probing, audio-language alignment, and open-form question answering. This setup enables an analysis of representation capabilities across audio domains, ensuring a comprehensive evaluation of pretrained models. The paper systematically compares pretrained models against several benchmarks using these evaluation protocols.
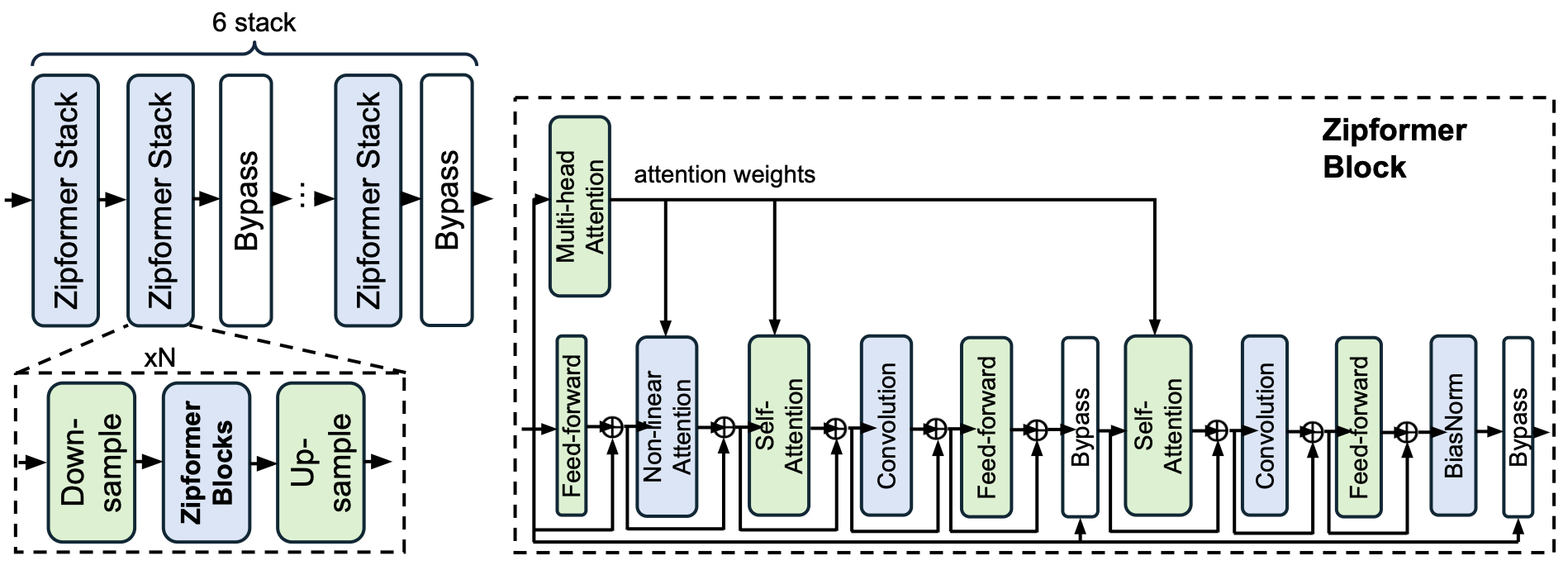
Figure 2: Model diagram of Zipformer.
Main Results
The study demonstrates that contrastive pretraining tends to outperform the captioning approach on linear probing tasks, especially on discriminative tasks like audio event classification and speaker identification. However, captioning objectives show better scalability for tasks requiring intricate language understanding, especially when paired with generative tasks. The paper also sheds light on the diminishing returns of initializing models with supervised pretraining, challenging established practices in the field. Notably, CaptionStew-trained models show strong cross-domain applicability, suggesting their potential in developing general-purpose audio representations.
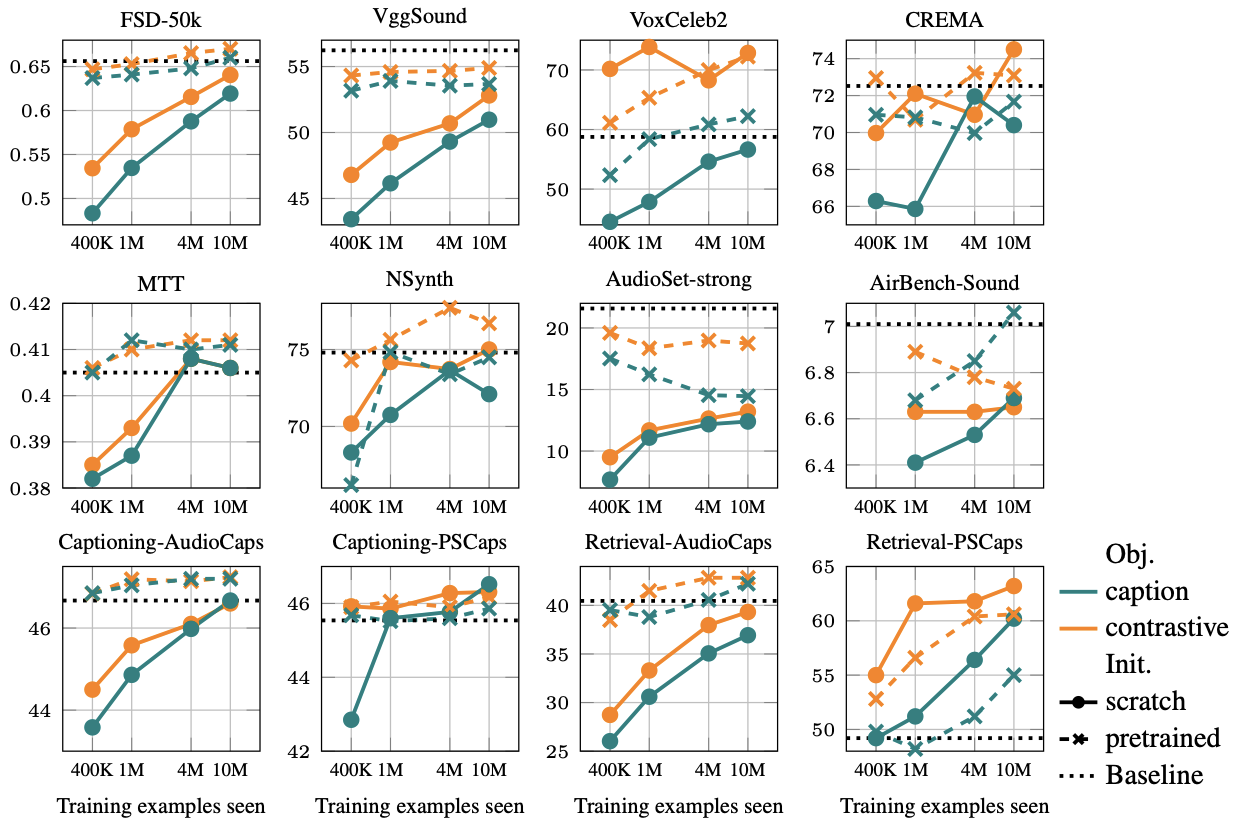
Figure 3: Data scaling behavior of contrastive vs. captioning objectives across representative tasks.
Conclusion
The research re-establishes audio-language pretraining as a viable pathway for general-purpose audio representation learning. By demonstrating that diverse linguistic sources can enhance semantic richness and representation robustness, the study sets a new direction for future research. This paper's insights into the scaling behavior of contrastive versus captioning objectives and the impact of supervised initialization offer practical guidance for audio representation learning frameworks. Overall, the authors provide essential tools, models, and datasets that pave the way for future advancements in universal audio understanding.