- The paper introduces TF-GridNet, a dual-path neural network that integrates full- and sub-band modeling for effective speech separation.
- It achieves state-of-the-art SI-SDR improvements by employing complex spectral mapping to predict real and imaginary signal components.
- The approach robustly addresses various acoustic conditions, offering potential for real-time applications in teleconferencing and hearing aids.
"TF-GridNet: Integrating Full- and Sub-Band Modeling for Speech Separation" (2211.12433) Overview
The paper "TF-GridNet: Integrating Full- and Sub-Band Modeling for Speech Separation" introduces TF-GridNet, a novel deep neural network architecture designed for speech separation tasks. This model leverages both full-band and sub-band modeling within the time-frequency (T-F) domain to enhance speaker separation performance. The architecture is composed of several blocks, each incorporating an intra-frame full-band module, a sub-band temporal module, and a cross-frame self-attention module. The network is trained to perform complex spectral mapping by predicting the real and imaginary components of target signals based on the input signal components. This approach has demonstrated state-of-the-art results across multiple datasets and conditions, including monaural and multi-channel setups, as well as various noise and reverberation scenarios.
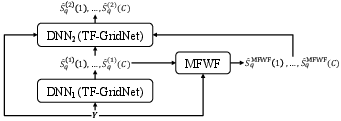
Figure 1: System overview.
Design and Methodology
TF-GridNet distinguishes itself by utilizing a grid-like modeling strategy in the complex T-F domain, effectively capturing spectro-temporal information. The model operates in a dual-path fashion with several distinct modules within each block:
- Intra-Frame Full-Band Module: This module captures spectral and spatial information by viewing each frame as a separate sequence along the frequency domain.
- Sub-Band Temporal Module: Sequences are modeled along the time axis for each frequency, leveraging temporal coherence within sub-bands.
- Cross-Frame Self-Attention Module: Long-range context across frames is captured, enabling direct information flow between distant frames.
The unique ability of TF-GridNet to integrate full-band and sub-band information is further enhanced by employing complex spectral mapping to predict target signal components.
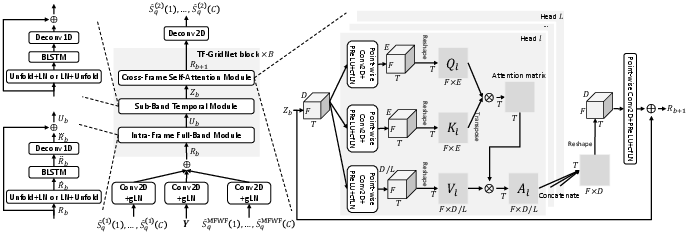
Figure 2: Proposed TF-GridNet based DNN_2.
TF-GridNet demonstrates notable improvements in scale-invariant signal-to-distortion ratio (SI-SDR) across several standard datasets:
- On WSJ0-2mix (anechoic speaker separation), TF-GridNet achieves a SI-SDR improvement of 23.5 dB, outperforming previous best scores significantly.
- In reverberant conditions tested with SMS-WSJ, TF-GridNet consistently achieves superior results, showing its robustness to reverberation and noise.
- For noisy-reverberant conditions evaluated using WHAMR!, TF-GridNet's performance is superior, further underscoring its effectiveness in adverse acoustic environments.
Its capability is further extended to multi-microphone conditions. The paper integrates TF-GridNet into a two-DNN system combined with a novel multi-frame Wiener filter, showcasing enhanced results for multi-channel processing tasks.
Implications and Future Directions
The TF-GridNet framework presents significant advancements both theoretically and practically:
- Theoretically, it introduces a robust way to handle complex T-F representations, a challenge in the field of speech separation.
- Practically, TF-GridNet is versatile, offering enhancements in both monaural and multi-channel environments. This versatility points to potential applications in real-world scenarios such as teleconferencing systems, hearing aids, and noise-cancellation devices.
Future research directions may involve exploring real-time and low-latency configurations, optimizing TF-GridNet for deployment on resource-constrained hardware, and further integrating advanced beamforming techniques. Overall, this work highlights that T-F domain methods, when appropriately designed, are competitive and effective for various speaker separation scenarios.
Conclusion
TF-GridNet represents a significant advancement in the field of speech separation, capable of achieving state-of-the-art performance across diverse acoustic scenarios. By effectively integrating full- and sub-band modeling, this approach paves the way for future innovations in complex spectral mapping and T-F domain processing.