- The paper introduces PATO, a hierarchical teleoperation system that automates repetitive subtasks to scale robotic data collection.
- It employs a high-level subgoal predictor with a conditional VAE and a low-level policy to reduce operator cognitive load while managing multiple robots.
- User studies demonstrate PATO’s effectiveness in kitchen-inspired tasks by enabling concurrent secondary tasks and robust data collection.
Policy Assisted TeleOperation for Scalable Robot Data Collection
The paper "PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection" proposes a novel approach to enhance the efficiency and scalability of robotic data collection through an innovative system named Policy Assisted TeleOperation (PATO). The necessity for large-scale data in machine learning, especially for training robust robotic systems, drives the exploration of methods to streamline the data collection process by reducing operator burden and expanding operational efficiencies.
The traditional teleoperation for gathering robotic data involves significant operator involvement, typically controlling one robot at a time. This scenario is inefficient for scalable data collection required in contemporary robotic learning systems. Inspired by manual annotation acceleration in other fields, the authors propose PATO, a system that automates repetitive subtasks and prompts human intervention only when the policy faces novel scenarios or is uncertain in its decision-making.
PATO exploits a hierarchical policy structure to manage robotic tasks. The overarching goal is to alleviate the operator's cognitive load while allowing one operator to manage multiple robots concurrently. This is achieved through a trained assistive policy that learns from a pre-collected dataset to determine which tasks can be autonomously executed.
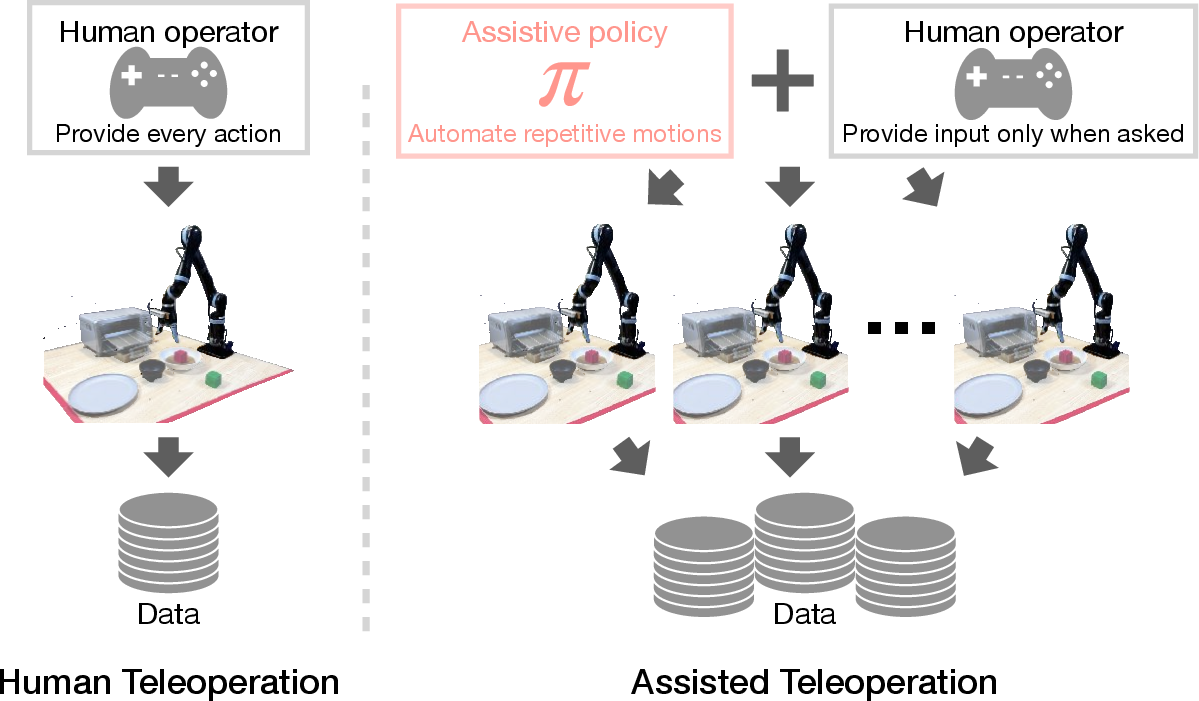
Figure 1: Policy Assisted TeleOperation (PATO) enables large-scale data collection by minimizing human operator inputs and mental efforts with an assistive policy, which autonomously performs repetitive subtasks.
Hierarchical Policy Learning
The hierarchical design is at the heart of PATO's functionality. It consists of a high-level subgoal predictor and a low-level subgoal-reaching policy. This design enables the system to discern between different potential actions, leveraging learning from multi-modal datasets.
The subgoal predictor is trained as a conditional variational auto-encoder (VAE), tasked with ensuring that the system can infer the distribution of possible subgoals using a latent variable. This captures the inherent variability in task execution paths learned from human demonstrations (Figure 2).
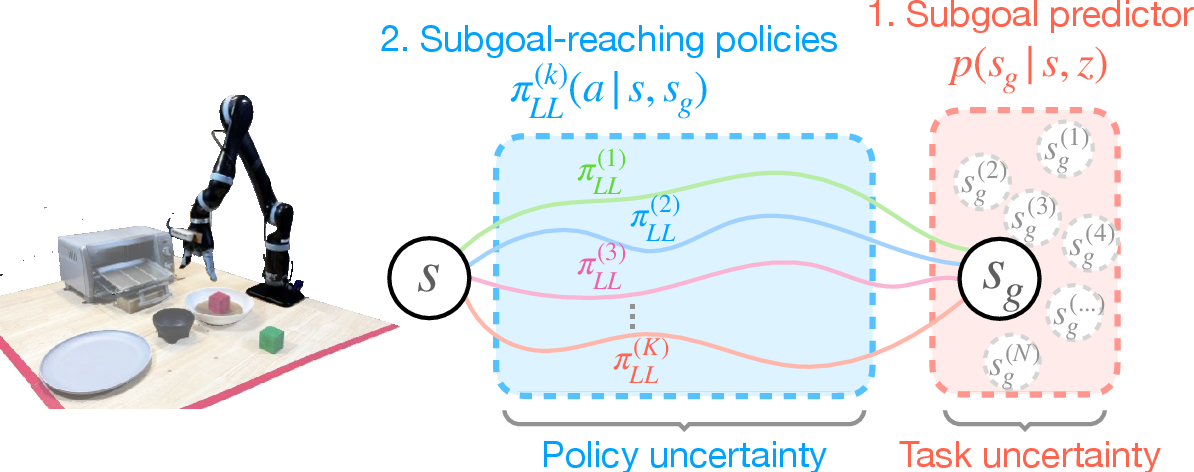
Figure 2: PATO is hierarchical: a high-level subgoal predictor and a low-level subgoal-reaching policy.
An essential aspect of PATO is its ability to intelligently request human operator input. This is based on the system's self-assessed uncertainty, which arises due to states not present in the training data or inherently ambiguous task continuations.
The decision to query human input is informed by two main uncertainty types: policy uncertainty and task uncertainty. Policy uncertainty is detected using an ensemble of stochastic policies, where the variance in predicted actions indicates an unfamiliar state. Task uncertainty is gauged through the variance in sampled subgoals, revealing ambiguities in task continuation.
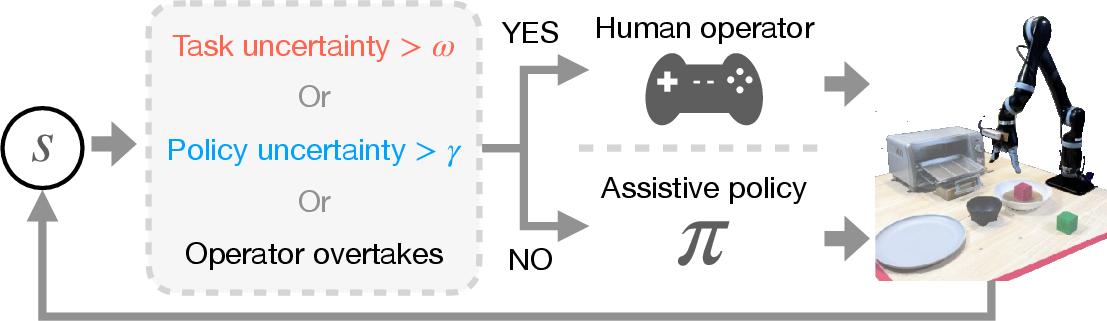
Figure 3: Our approach asks for human inputs when the assistive policy is uncertain about which subtask or action to take, reducing the workload of the human operator.
User Study and Implementation
The effectiveness of PATO was evaluated through a series of user studies involving teleoperation tasks with both real and simulated robots. A significant finding from these studies was PATO's ability to enable operators to perform secondary tasks concurrently, further demonstrating its potential to reduce mental workload and elevate data collection efficiency.
The study utilized a real-world robotic setup where users managed kitchen-inspired tasks. The hierarchical policy operated in an environment that required complex, goal-oriented manipulation sequences, underscoring the policy's adeptness at automated control under realistic conditions.

Figure 4: User study setup with a Kinova Jaco arm for diverse, kitchen-inspired tasks.
Implications and Future Work
PATO's capabilities to scale robotic data collection signify a substantial step forward in creating more efficient machine learning models for robotics. By minimizing operator involvement and enabling control over multiple robots, the system potentially disrupts conventional teleoperation limitations. This opens avenues for more extensive and versatile datasets, facilitating robust robotic learning algorithms.
Future work could focus on evolving PATO's capabilities, particularly its adaptation to novel, dynamic environments without requiring extensive retraining. Continuous learning from ongoing teleoperation scenarios could enhance its robustness, offering a pathway towards fully autonomous robotics systems capable of executing complex tasks with minimal human oversight.
Conclusion
"Policy Assisted TeleOperation for Scalable Robot Data Collection" introduces a promising paradigm in robotic data collection. By implementing hierarchical assistive policies that balance automated action with strategic human guidance, PATO achieves significant improvements in data collection throughput, ultimately fostering advancements in machine learning applications for autonomous robots. This work sets the stage for ongoing research into scalable, intelligent systems poised to transform teleoperation in robotics.