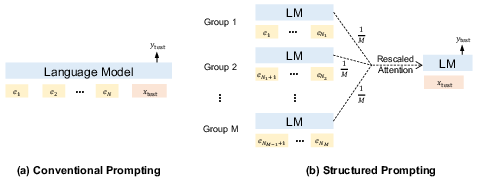
- The paper introduces a novel structured prompting technique that partitions thousands of examples into groups with rescaled attention for efficient in-context learning.
- Experimental results demonstrate 3–5 percentage points improvement in accuracy and reduced variance on tasks such as text classification, multi-choice, and QA.
- The approach achieves linear scalability and stability by balancing computational costs with improved performance in large language models.
Structured Prompting for Large-Scale In-Context Learning: A Technical Analysis
In-context learning (ICL) enables large LMs to adapt to tasks at inference by conditioning on a set of demonstrations without parameter updates. Traditional ICL approaches concatenate a handful (N typically 5–100) of labeled examples with the test input, constrained by context window limits and the quadratic complexity of self-attention. This restricts the number of conditioning examples and limits data utilization, reducing performance and increasing evaluation variance. The paper "Structured Prompting: Scaling In-Context Learning to 1,000 Examples" (2212.06713) addresses the technical challenge of scaling in-context learning from few-shot to thousand-shot regimes within computational constraints.
Methodology: Structured Prompting Architecture
Structured prompting partitions the N demonstrations into M groups, encoding each independently with right-aligned position embeddings so that all groups interface contiguously with the test input in the context window. The core innovation is a rescaled attention mechanism, modifying the attention computation for the test input by multiplying the self-attention scores with the number of groups (M), thus balancing focus between demonstrations and the test input regardless of N.
This formulation achieves two main objectives:
Experimental Results: Benchmarking Across Tasks and Model Sizes
The methodology was evaluated on GPT-like decoder-only LMs ranging from 1.3B to 176B parameters (BLOOM), spanning text classification, multi-choice, and open-ended generation tasks.
Text Classification: The structured prompting approach yields 3–5 absolute percentage point improvements in accuracy over conventional ICL at large shot counts (e.g., 500–1000), with notably reduced variance across random selections and permutations. For instance, on SST-2, accuracy with 13B model increases from 93.8% (max-shot) to 94.1% (1000-shot) and variance drops below 0.5.
Multi-Choice Tasks: Gains are consistent but less pronounced compared to classification, with incremental increases as $N$ increases. Scaling up model size is more impactful than increasing shot count for these tasks.
Open-Ended Generation: Structured prompting produces a monotonic performance increase and decreasing variance (except for NQ), showing substantial improvement in extractive QA benchmarks such as SQuAD.
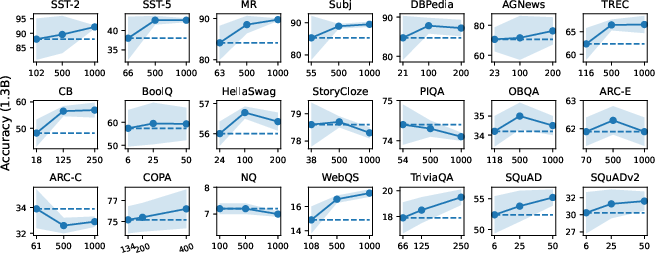
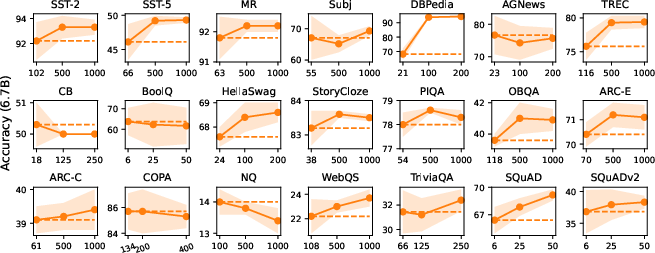
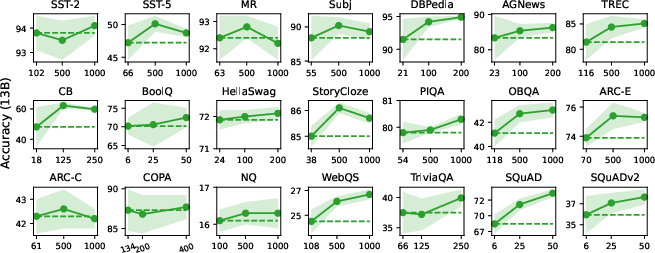
Figure 2: In-context learning accuracy vs. number of conditioning examples, highlighting superior scalability, reduced variance, and improved absolute performance for structured prompting.
Scaling to 176B Parameters: Structured prompting generalizes to extremely large models, yielding improved average results and stability across datasets as group number increases (5× groups achieves highest average).
Ablation Studies and Strategic Engineering Insights
- Prompt Length: Longer prompts per group improve accuracy, especially for smaller LMs. Performance degrades with excessive truncation, indicating models rely on autoregressive continuity.
- Scaling Factor: The M multiplier in rescaled attention is empirically optimal. Without scaling, attention distribution becomes pathological, overly biased toward demonstrations.
- Alignment Strategies: "Truncate" padding provides optimal group alignment, minimizing inference disturbance for both FairseqLM and BLOOM. "Pad Space" can degrade performance in absence of appropriate special tokens.
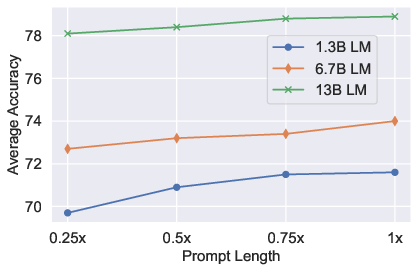
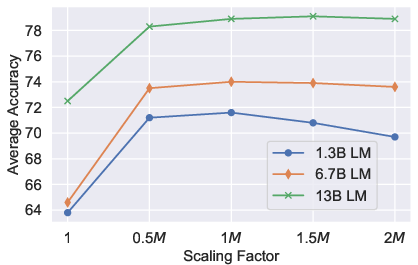
Figure 3: Ablation showing prompt length effects—demonstrating trade-offs between accuracy and memory usage across different group sizes.
Stability and Theoretical Implications
The rescaled attention and grouping strategy substantially mitigates variance inherent to demonstration selection and ordering, addressing major sources of ICL instability previously identified in the literature. Structured prompting makes stability and reliability attainable at scale, especially crucial for high-stakes or production deployments. The approach also highlights a mismatch between LM pretraining and downstream ICL patterns—future work may benefit from introducing group-structured priors during pretraining to further align inference dynamics.
Practical and Theoretical Implications
This work provides a scalable engineering solution to expand ICL utility, bridging the gap between fine-tuning (high supervision, high cost) and ICL (low supervision, limited by window and computation). Structured prompting enables injection of large context (potentially long retrieved documents for retrieval-augmented generation) and supports more robust downstream evaluation.
Theoretically, the methodology demonstrates that autoregressive LMs can exploit parallel context interfaces if positional encoding and attention are appropriately engineered, suggesting that existing self-attention impairments at scale can be mitigated without model re-training.
Future Directions
Future development should focus on pretraining objectives that endow LMs with structured, parallel-context recognition capability, potentially harmonizing pretraining and inference. Coupling structured prompting with retrieval modules or external knowledge bases is likely to further enhance large context utilization. Extensions to non-decoder-only architectures (e.g., encoder-decoder T5, retrieval-augmented transformers) remain fruitful areas for adaptation.
Conclusion
Structured prompting resolves the computational and stability bottlenecks of conventional in-context learning by enabling LMs to condition on over a thousand examples efficiently and robustly. The proposed architecture and rescaled attention facilitate linear scalability, improved accuracy, and significant reduction in evaluation variance across various tasks. This approach lays a foundation for more context-rich, stable, and practical zero/few-shot adaptation paradigms. Further theoretical and engineering advances are anticipated, especially in integrating long-range context and structured supervision into LM training and inference.
(2212.06713)