Structured Prompting Enables More Robust, Holistic Evaluation of Language Models
Abstract: As LMs are increasingly adopted across domains, high-quality benchmarking frameworks that accurately estimate performance are essential for guiding deployment decisions. While frameworks such as Holistic Evaluation of LLMs (HELM) enable broad evaluation across tasks, they often rely on fixed prompts that fail to generalize across LMs, yielding unrepresentative performance estimates. Unless we estimate each LM's ceiling (maximum achievable via changes to the prompt), we risk underestimating performance. Declarative prompting frameworks, such as DSPy, offer a scalable alternative to manual prompt engineering by crafting structured prompts that can be optimized per task. However, such frameworks have not been systematically evaluated across established benchmarks. We present a reproducible DSPy+HELM framework that introduces structured prompting methods which elicit reasoning, enabling more accurate LM benchmarking. Using four prompting methods, we evaluate four frontier LMs across seven benchmarks (general/medical domain) against existing HELM baseline scores. We find that without structured prompting: (i) HELM underestimates LM performance (by 4% average), (ii) performance estimates vary more across benchmarks (+2% standard deviation), (iii) performance gaps are misrepresented (leaderboard rankings flip on 3/7 benchmarks), and (iv) introducing reasoning (chain-of-thought) reduces LM sensitivity to prompt design (smaller Δ across prompts). To our knowledge, this is the first large-scale benchmarking study to empirically characterize LM behavior across benchmarks and prompting methods, showing that scalable performance ceiling estimation enables more decision-useful benchmarks. We open-source (i) DSPy+HELM Integration (https://github.com/stanford-crfm/helm/pull/3893) and (ii) Prompt Optimization Pipeline (https://github.com/StanfordMIMI/dspy-helm).
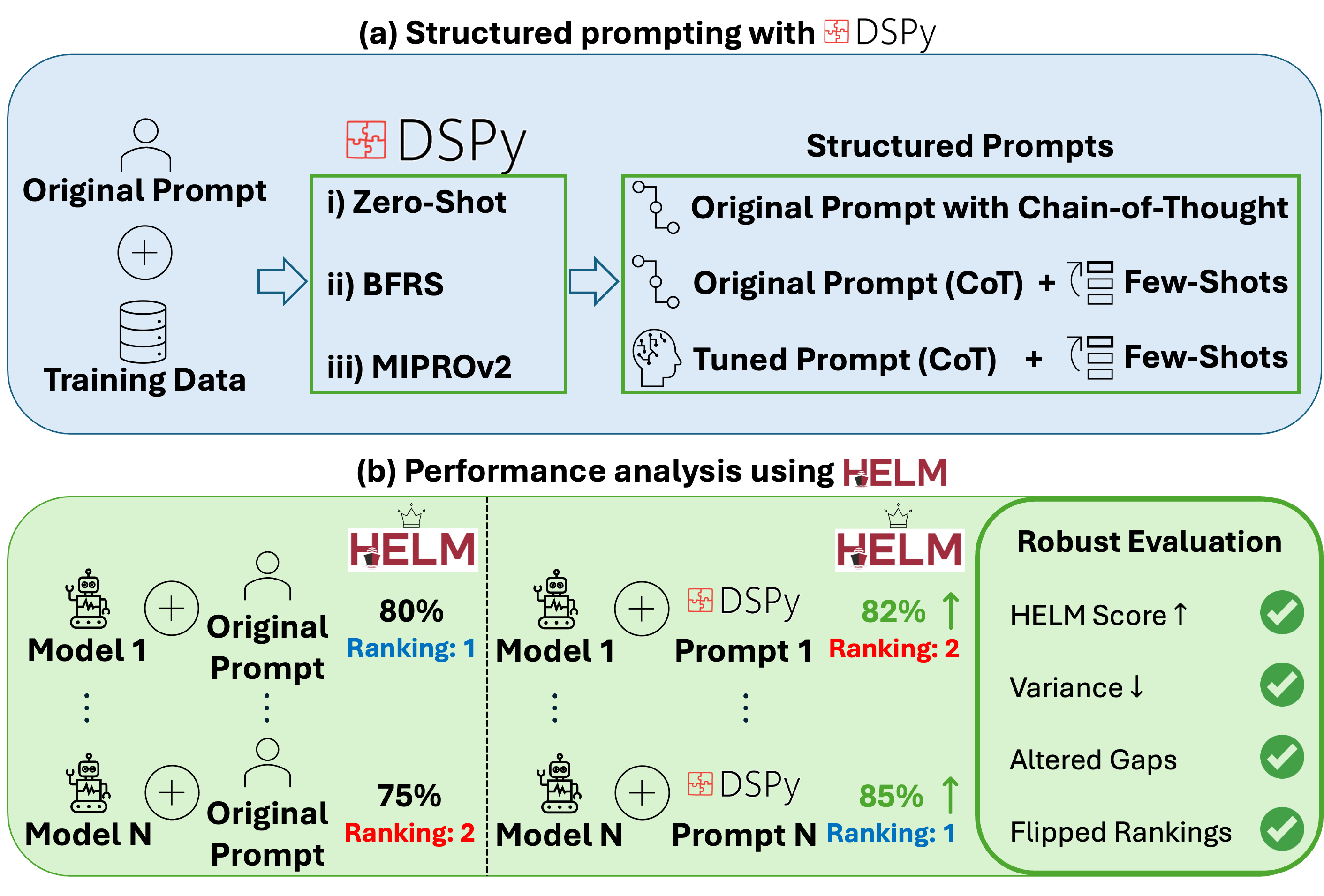
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how we test and compare big LLMs (like GPT, Claude, Gemini) to see how good they are. It argues that many public tests use simple, fixed prompts (short instructions) that don’t work equally well for every model. Because of that, scores can be lower than they should be and rankings can be misleading. The authors show that “structured prompting” — carefully designed prompts that ask models to explain their reasoning — gives fairer, more accurate, and more useful evaluations.
Key Objectives
The paper set out to do three main things in simple terms:
- Check whether using smarter, structured prompts makes LLM scores more accurate than using one fixed prompt for all models.
- See how different prompting styles (like asking the model to “show your work”) change scores and model rankings on popular benchmarks.
- Provide a practical, repeatable way to estimate each model’s “performance ceiling” — the best it can do just by improving the prompt, not retraining the model.
Methods and Approach
The authors combine two tools:
- HELM: a public benchmarking platform that tests models across many tasks.
- DSPy: a framework that builds structured prompts and can automatically improve them.
They evaluate four well-known LLMs on seven public benchmarks covering general reasoning and medical tasks. For each task, they try different ways to prompt the models:
- HELM Baseline: a fixed, plain prompt with no reasoning steps. Think of this as giving short directions like “Answer the question” without asking for how you got there.
- Zero-Shot Predict: same idea as baseline but wrapped in DSPy’s format. Still no examples or reasoning.
- Zero-Shot Chain-of-Thought (CoT): asks the model to show its steps (“reasoning”) before giving the final answer. Like showing your math work.
- BFRS (Bootstrap Few-Shot with Random Search): collects good example Q&A pairs from practice runs, then tries random mixes of a few examples to find which set helps most. Like testing different study flashcards to see which combination boosts your score.
- MIPROv2: a more advanced optimizer that proposes better instructions and better example sets, then searches systematically for the best combination. Like having a coach tune your study guide and examples based on what works.
They keep the testing fair: optimization happens on training/validation splits, and final test scores are computed through HELM’s standard setup. The models are run deterministically (no randomness), and results are averaged across benchmarks with equal weight.
Main Findings
Here are the most important results, explained simply:
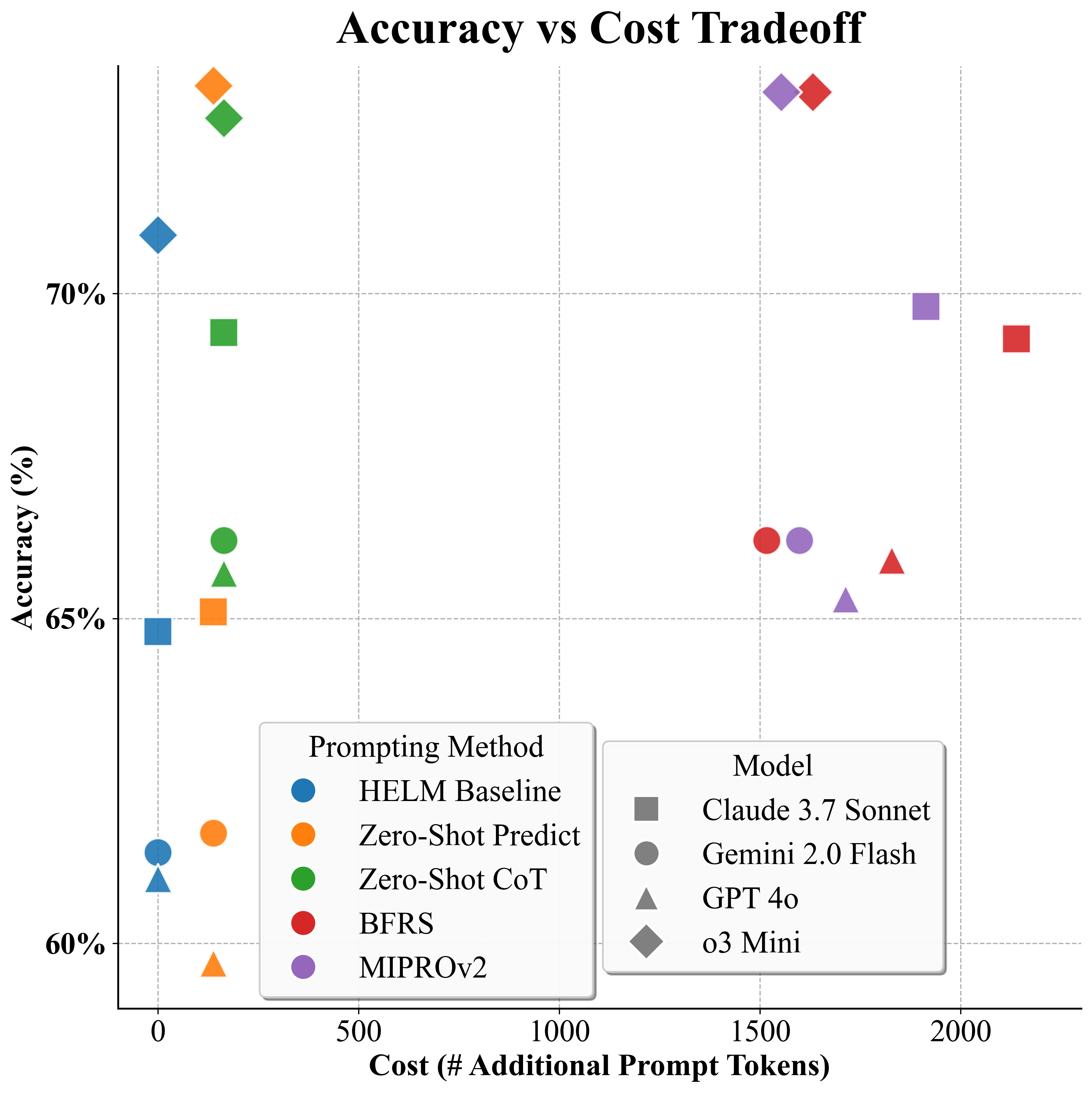
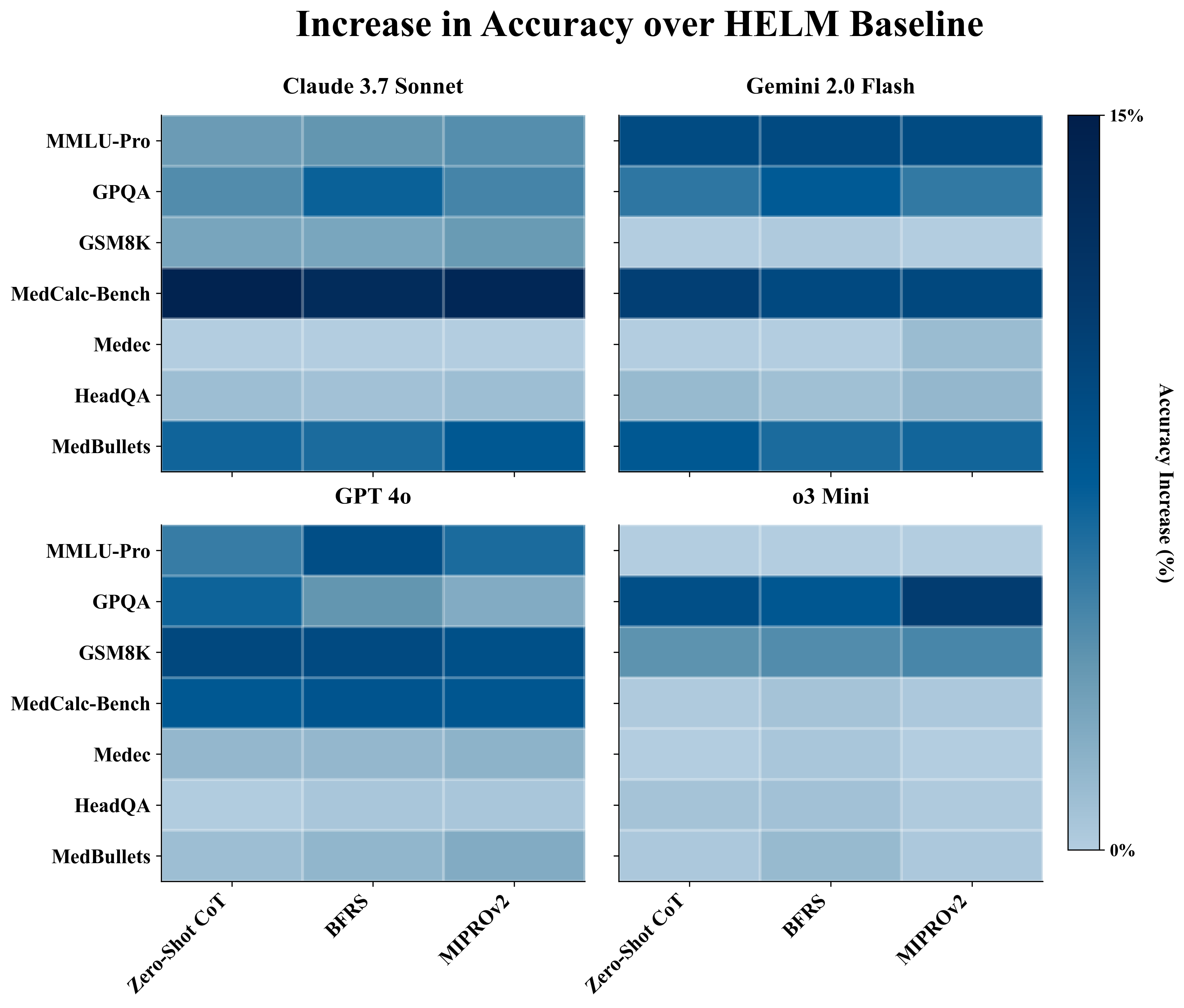
- Structured prompting raises scores. Asking for reasoning or picking better examples increases accuracy by about 4% on average compared to the baseline fixed prompt.
- Rankings can flip. When you measure each model at its “best prompt” (its performance ceiling), the leaderboard changes on 3 out of 7 benchmarks. That means some models look better or worse depending on the prompt style.
- More stable results. With structured prompting, scores vary less across different benchmarks (about 2% less variability), which makes comparisons more reliable.
- “Show your work” does most of the heavy lifting. Moving from no reasoning to chain-of-thought brings the biggest gains. Once you add reasoning, fancy optimization adds only small extra improvements.
- Best value for cost: Zero-Shot CoT. Adding a short reasoning instruction costs a small number of extra tokens (small increase in prompt length) but gets most of the benefits. Methods that include many example demos can cost much more per query (many extra tokens) for similar gains.
Why does chain-of-thought help? When models “show their work,” they consider multiple reasoning paths and average over them. This tends to make answers more correct and less sensitive to tiny changes in the wording of the prompt.
Implications and Impact
- Benchmark fairness: Public leaderboards should not rely on one fixed prompt. Instead, they should estimate each model’s performance ceiling with structured prompting, especially chain-of-thought, to avoid underestimating models.
- Better decisions: If you’re choosing a model for a real-world task (like medical question answering), you should compare models under their best prompts. That will give you a truer sense of differences in ability, cost, and stability.
- Practical guidance: If you want a simple, effective upgrade, use Zero-Shot CoT — ask the model to explain its steps. It’s cheap and gives most of the improvement.
- Future evaluations: Benchmark creators and users should include structured prompting as part of their standard testing process to reach more accurate and robust conclusions.
In short, the paper shows that “how you ask” matters a lot. By asking models to reason step-by-step and by tuning prompts sensibly, we get fairer scores and better comparisons — which is key for making smart choices about deploying LLMs in schools, hospitals, and many other settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable research directions.
- Generalization beyond closed-source frontier LMs: Evaluate the DSPy+HELM framework on strong open-source models (e.g., Llama, Mixtral, DeepSeek), smaller models, and older API versions to test whether the reported sensitivity and ceiling effects hold across model families and sizes.
- Non‑English and multilingual evaluation: Assess whether structured prompting and CoT benefits transfer to non‑English datasets (e.g., Spanish portions of HeadQA, multilingual QA) and multilingual tasks, including language-specific instruction tuning considerations.
- Modalities beyond text: Extend evaluation to multimodal tasks (images, tables) supported by frontier LMs to test if structured prompting improves robustness outside text-only benchmarks.
- Task coverage gaps: Add benchmarks for long-context reasoning (e.g., retrieval-heavy or 100k+ context tasks), code generation, open-ended generation (summarization, translation), and tool-use workflows to probe whether ceiling estimation generalizes to these task types.
- Metric breadth and reliability: Incorporate non-accuracy metrics (calibration, confidence/entropy, ECE/Brier score, robustness to perturbations, faithfulness/hallucination rates, safety/toxicity, fairness/bias) to understand whether structured prompting improves reliability, not just accuracy.
- Statistical robustness of leaderboard shifts: Re-run experiments with multiple seeds, repeated trials, and formal significance tests (e.g., permutation tests on rank flips; bootstrap on macro-averages) to determine whether observed ranking changes are statistically reliable rather than artifacts of single deterministic runs.
- Aggregation choices and rank stability: Compare macro-averaging with sample-size-weighted (micro) averaging and rank correlation analyses (Kendall tau, Spearman) to quantify how aggregation choices affect conclusions about model gaps and flips.
- Sensitivity to data partitions: Vary train/validation splits, seeds, and cross-validation folds to assess optimizer stability and risk of overfitting to the validation split when bootstrapping demonstrations.
- Demonstration selection and K ablations: Systematically ablate the demo-selection threshold τ, number of demos per module K (e.g., K∈{0,1,3,5,10}), and demo sourcing strategies (nearest-neighbor vs. random vs. diversity-aware) to quantify their impact on ceilings and cost.
- Transferability of optimized prompts: Test whether prompts optimized for one LM transfer to others (cross-model transfer) and whether prompts optimized on one benchmark generalize to related tasks (cross-task transfer).
- Temporal fragility under model updates: Track performance of optimized prompts over API/model version changes to measure degradation or improvement and quantify maintenance costs for keeping “ceiling” prompts current.
- CoT theory–practice gap: Empirically validate the paper’s CoT prompt-insensitivity argument by measuring path distribution shifts (e.g., TV distance, KL on sampled reasoning traces), decision margins, and the fraction of near-tied items where prompts can flip predictions.
- Decoding strategy effects: Evaluate temperature, nucleus sampling, and self-consistency voting versus temperature=0 to quantify how sampling interacts with CoT and whether ceilings rise further with multiple trajectories.
- Output-length constraints: Remove or vary the <200-token output cap to test whether longer reasoning traces improve accuracy or induce more errors/hallucinations; measure tradeoffs and identify optimal caps per task.
- Parsing and evaluation artifacts: Audit HELM output extraction under structured prompts (“REASONING”/“OUTPUT” fields) to ensure no parsing-related scoring biases; add robustness checks for formatting variations and noisy rationales.
- Optimizer diversity: Compare DSPy’s BFRS/MIPROv2 against other APO families (LM-as-optimizer, evolutionary methods like Promptbreeder, RL-based or Bayesian optimization variants, program-of-thought planners) to see if higher ceilings are attainable.
- Tool use and retrieval augmentation: For computation-heavy or knowledge-limited tasks (e.g., MedCalc-Bench, Medec), evaluate calculators, external knowledge retrieval, and verifier/critic modules to test whether improvements require tools beyond prompting.
- Cost and latency measurement: Report end-to-end costs (provider-specific $/1k tokens, latency, throughput, API rate limits), not just token counts, for both inference and optimization runs; quantify ROI and amortization across deployment scales.
- Safety and ethical impacts: Measure whether CoT increases harmful or speculative content (e.g., hallucination rates, toxicity) and whether structured prompts reduce or exacerbate safety risks in medical and general tasks.
- Per-benchmark and per-category diagnostics: Provide fine-grained analyses (e.g., topic-wise breakdowns within GPQA/HeadQA/MedBullets) to identify which subtypes benefit most/least from structured prompting.
- o3 Mini’s prompt insensitivity: Investigate why o3 Mini shows smaller gains (native reasoning mode? internal self-consistency?) via ablations that disable or emulate its reasoning features and compare against CoT induction in non-reasoning models.
- “High‑stakes” instruction framing: Test whether MIPROv2’s high-stakes medical framing systematically improves performance or induces undesirable biases; run neutral vs. high-stakes instruction ablations and measure effects.
- Ceiling definition and search budgets: Quantify how close the reported “ceilings” are to true maxima by scaling optimizer trial counts, batch sizes, and search spaces; provide confidence intervals or regret bounds on estimated ceilings.
- Robustness to adversarial/prompts and injection: Evaluate how structured prompts handle adversarial inputs, prompt injection, or instruction conflicts to ensure robustness under real-world usage.
- Reproducibility assets: Besides pipelines, release the exact optimized instructions and selected demos per benchmark/model (where licensing permits) to enable direct replication and cross-lab comparisons.
Glossary
- Automatic Prompt Optimization (APO): Methods that treat prompt design as an optimization problem to automatically improve model instructions and examples. "researchers have explored automatic prompt optimization (APO)"
- Bayesian search: A search strategy using probabilistic models to guide exploration toward high-performing configurations. "and (iii) Bayesian search over instruction-demo pairs."
- BFRS (Bootstrap Few-Shot with Random Search): An optimizer that bootstraps candidate demonstrations and then randomly searches demo sets to maximize validation performance. "BFRS. Bootstrap Few-Shot with Random Search (BFRS) (Algorithm~\ref{alg:bfrs}) leverages the idea of bootstrapping and random sampling to select the best few-shot demonstrations (fixed instructions) in two phases:"
- Bootstrap confidence interval: A statistical interval derived from resampling to estimate uncertainty around metrics. "Entries are reported as mean ± 95% bootstrap confidence interval."
- Chain-of-thought (CoT): A prompting technique that elicits step-by-step reasoning traces before producing an answer. "(iv) introducing reasoning (chain-of-thought) reduces LM sensitivity to prompt design"
- Data-processing inequality: An information-theoretic inequality stating that processing cannot increase information, used to bound changes in distributions. "applying the data-processing inequality followed by Pinsker's inequality"
- Declarative prompting: A paradigm where prompts and LM pipelines are specified in modular, structured forms rather than as ad-hoc strings. "Declarative prompting frameworks, such as DSPy, offer a scalable alternative to manual prompt engineering"
- DSPy: A declarative framework for composing modular LM pipelines and optimizing structured prompts. "DSPy~\citep{khattab2023dspy} is a widely used declarative framework that represents prompts as modular, parameterized components"
- Exact match: An evaluation metric that counts predictions as correct only when they match the ground truth exactly. "The metric is exact match."
- Frontier LMs: State-of-the-art LLMs at the cutting edge of capability. "Even state-of-the-art general-purpose frontier LMs exhibit non-trivial hallucination rates"
- HELM (Holistic Evaluation of LLMs): A benchmarking framework for comprehensive, transparent evaluation of LLMs across many tasks. "While frameworks such as Holistic Evaluation of LLMs (HELM) enable broad evaluation across tasks"
- In-context examples: Demonstration pairs included in the prompt to guide the model’s behavior via few-shot learning. "IN-CONTEXT EXAMPLES ( Demos):"
- Kullback–Leibler divergence: A measure of difference between probability distributions used to bound changes in model behavior. "is Kullback--Leibler divergence"
- Macro-average: An averaging scheme that gives equal weight to each task or benchmark when summarizing performance. "Entries are reported as the macro-average ± standard deviation σ over seven benchmarks."
- MIPROv2: An optimizer that jointly proposes instructions and selects few-shot demonstrations using bootstrapping, instruction proposals, and Bayesian/TPE search. "MIPROv2 (Algorithm~\ref{alg:mipro}) is an optimizer that jointly selects instructions and few-shot demonstrations"
- Performance ceiling: The highest achievable performance for a model via prompt-only changes, used to assess true capability. "scalable performance ceiling estimation enables more decision-useful benchmarks."
- Pinsker’s inequality: An inequality relating total variation distance to KL divergence, used to bound differences between distributions. "applying the data-processing inequality followed by Pinsker's inequality"
- Random few-shot search: Sampling and testing different sets of demonstrations to find high-performing few-shot configurations. "Random few-shot search: Given demonstration pools, BFRS randomly samples sets of demonstrations per module"
- Self-consistency: A technique that marginalizes over multiple reasoning paths to stabilize and improve final predictions. "predicts by marginalizing over paths (self-consistency):"
- Total-variation distance: A metric for the difference between probability distributions, used to bound changes in predictions. "where $\|\cdot\|_{\mathrm{TV}$ is total-variation distance"
- TPE (Tree-structured Parzen Estimator): A Bayesian optimization method that models densities to select promising hyperparameter configurations. "Fit/update TPE from to obtain in \eqref{eq:tpe-densities}."
- Zero-Shot CoT: A prompting method that elicits chain-of-thought reasoning without providing demonstrations. "Zero-Shot CoT. DSPy's Zero-Shot CoT configuration utilizes the same prompting structure as Zero-Shot Predict"
- Zero-Shot Predict: A baseline prompting method with instructions only and no in-context demonstrations. "DSPy's Zero-Shot Predict configuration is an unoptimized non-adaptive baseline"
Practical Applications
Below are practical applications that follow directly from the paper’s findings and innovations on structured prompting and ceiling-aware benchmarking. They are grouped by when they can be deployed and linked to sectors with concrete tools, products, and workflows. Each item notes key assumptions or dependencies that may affect feasibility.
Immediate Applications
Industry (Software/AI platforms, enterprise ML)
- Ceiling-aware model selection for procurement and vendor evaluation
- Use DSPy+HELM to measure “ceiling performance,” variance, and ranking stability across candidate LMs before purchase or renewal. Replace single-prompt leaderboards with multi-prompt, CoT-inclusive evaluations to avoid underestimating model capabilities.
- Tools/workflows: “Ceiling benchmarking” dashboards, prompt A/B testing harness, CoT baseline pack, CI/CD gate for model updates.
- Assumptions/Dependencies: Access to representative validation data and ground truth; consistent model API versions; ability to run deterministic inference (e.g., temperature=0); token budget for few-shot prompts where needed.
- Cost-performance optimization of prompts in production
- Adopt Zero-Shot CoT as the default cost-effective prompting template that captures most performance gains with minimal token overhead; reserve few-shot methods (BFRS, MIPROv2) for high-stakes tasks that warrant the extra cost.
- Tools/workflows: Cost–accuracy calculator, prompt token budget allocator, automatic prompt variant selection.
- Assumptions/Dependencies: Token pricing and context window constraints; monitoring to detect prompt drift across model updates.
- MLOps gates for model upgrades and prompt changes
- Integrate the DSPy+HELM pipeline into release processes so every model or prompt update is evaluated against ceiling metrics and across-benchmark variance (sigma). Roll back if variance widens or ceiling decreases.
- Tools/workflows: Pre-deployment test suites, regression dashboards, rank-stability checks.
- Assumptions/Dependencies: Automated dataset loaders with train/val splits; standardized metrics across tasks; policy for rollback thresholds.
Healthcare
- Safer clinical LLM deployment via ceiling-aware evaluation
- Use MedHELM benchmarks (e.g., MedCalc-Bench, HeadQA, MedBullets) with Zero-Shot CoT to select models and prompts for clinical decision support (risk score calculation, documentation QA). Exploit observed gains on reasoning-heavy tasks to reduce underestimation and bias in model choice.
- Tools/workflows: EHR assistant prompt packs, clinical evaluation harness, “reasoning + output” templates.
- Assumptions/Dependencies: HIPAA-compliant data pipelines; clinician oversight; IRB approvals for any real-world validation; guardrails for hallucination detection.
- Clinical workflow tuning with prompt optimization
- Bootstrap few-shot demonstrations from safe, labeled internal notes to optimize prompts for targeted tasks (e.g., risk score computation, chart error detection), then amortize costs over repeated use.
- Tools/workflows: Demonstration library builder, BFRS/MIPROv2 optimizers, audit trail for demo provenance.
- Assumptions/Dependencies: Availability of de-identified and labeled clinical data; policies for prompt trace storage and privacy.
Finance and Legal
- Ceiling-informed compliance and accuracy checks for document QA
- Evaluate multiple LMs with structured prompts on compliance, contract review, and policy Q&A datasets to select the most robust model under CoT, minimizing false conclusions due to prompt sensitivity.
- Tools/workflows: Compliance QA prompt packs, ceiling-aware scorecards, leaderboard stability reports.
- Assumptions/Dependencies: Domain-specific labeled corpora; regulatory constraints on model use; auditability of reasoning traces.
Education
- Reliable math and science tutoring with CoT
- Deploy Zero-Shot CoT templates for GSM8K-like reasoning tasks in tutoring systems to boost solution accuracy with minimal cost.
- Tools/workflows: “REASONING → OUTPUT” tutor prompts, classroom piloting framework, learning analytics for variance tracking.
- Assumptions/Dependencies: Age-appropriate content filtering; human-in-the-loop oversight for incorrect solutions; alignment with curriculum standards.
Academia and Benchmarking Communities
- More representative research evaluations and publications
- Adopt ceiling-aware, CoT-inclusive baselines in papers to avoid underreporting model capabilities and misrepresenting inter-model gaps; include variance and ranking stability as standard metrics.
- Tools/workflows: DSPy+HELM integration to reproduce structured prompt variants; “ceiling plots” and sigma summaries in results sections.
- Assumptions/Dependencies: Agreement on reporting standards; access to open benchmarks; reproducible seeds and model versions.
Policy and Governance
- Procurement guidance and reporting templates for LLM evaluation
- Require vendors and agencies to report model ceiling performance, variance across prompts, and ranking stability across benchmarks in tenders and audits.
- Tools/workflows: Standardized evaluation rubric, disclosure checklist (baseline vs ceiling, zero-shot vs CoT, few-shot costs).
- Assumptions/Dependencies: Consensus on minimal prompt sets; references to public benchmarks; capacity to spot-check claims.
Daily Life / Power Users
- Prompt patterns for personal reliability
- Use the paper’s minimal CoT template (produce “REASONING” then “OUTPUT”) for everyday reasoning tasks (planning, calculations, study aids) to reduce sensitivity to wording variations and improve accuracy with low token overhead.
- Tools/workflows: Personal prompt library, “reasoning-first” macros.
- Assumptions/Dependencies: Users’ access to LMs with sufficient context window; awareness that CoT can still err and needs verification.
Long-Term Applications
Standards and Regulation
- Ceiling-aware benchmarking standards in regulated domains
- Formalize standards that require reporting of performance ceilings, cross-prompt variance, and ranking stability for medical, financial, and public-sector deployments; encourage CoT-inclusive baselines in certification.
- Tools/products: Standard test suites, certification criteria, auditor training curricula.
- Assumptions/Dependencies: Multi-stakeholder consensus; coordination with regulators (e.g., FDA-equivalent for AI), sustained access to high-quality benchmarks.
Dynamic and Continuous Prompt Optimization
- Online prompt tuning in production systems
- Extend BFRS/MIPROv2 to continuously adapt prompts to data drift, new model releases, and task changes, while preserving auditability and guardrails.
- Tools/workflows: Live A/B prompt optimizer, drift detectors, governance policies for demo updates.
- Assumptions/Dependencies: Safe collection of interaction traces; robust privacy controls; safeguards against overfitting and gaming metrics.
Cross-Domain Expansion (Robotics, Energy, Operations)
- Ceiling-aware evaluation for action-planning and decision support
- Translate structured prompting and CoT to multimodal/agent settings (task planning in robotics, grid operations advisories, logistics scheduling) to quantify gains from reasoning-focused prompts.
- Tools/workflows: Agent prompt packs, task-specific demo repositories, ceiling-aware planning benchmarks.
- Assumptions/Dependencies: Multimodal support (text + sensors), accurate simulators or labeled outcomes, domain safety protocols.
Safety, Privacy, and Trust Research
- Secure CoT and reasoning-trace governance
- Investigate methods to retain CoT’s robustness benefits while minimizing leakage of sensitive content in reasoning traces and preventing prompt injection via demos.
- Tools/workflows: Redaction and trace minimization tools, safe-demo curation pipelines, adversarial prompt testing.
- Assumptions/Dependencies: Advances in privacy-preserving prompting, red-teaming capacity, formal risk assessments.
Marketplaces and Bench-to-Deployment Pipelines
- “Ceiling-as-a-Service” platforms
- Build services that run DSPy+HELM-style evaluations for enterprises, returning ceiling scores, variance, and cost curves; integrate with procurement portals and MLOps stacks.
- Tools/products: Hosted evaluators, API-based benchmarking runners, automated reports with sector-specific templates.
- Assumptions/Dependencies: Sustainable access to model APIs; licensing for commercial benchmarks; customer data onboarding policies.
Academic Methodology and Meta-Evaluation
- Reasoning-path analysis and prompt sensitivity theory
- Expand the paper’s theoretical framing (decision margins and path distributions) to develop predictive measures of prompt sensitivity and conditions for invariance; design probes that quantify model robustness to prompt changes.
- Tools/workflows: Path-distribution analyzers, margin estimators, synthetic benchmark generators.
- Assumptions/Dependencies: Access to model internals or sufficient sampling; agreement on evaluation metrics beyond accuracy (e.g., calibration, consistency).
Multilingual and Low-Resource Settings
- Ceiling-aware evaluation for non-English and specialized domains
- Localize structured prompts and demo bootstrapping to languages and domains with scarce labeled data, leveraging small, curated demos to approximate ceilings across cultural contexts.
- Tools/workflows: Multilingual prompt packs, community-driven demo collection, transfer-learning evaluators.
- Assumptions/Dependencies: Availability of validated datasets in target languages; culturally appropriate content; mechanisms to prevent bias amplification.
Economic and Policy Impact Modeling
- Value-based procurement and ROI models
- Incorporate ceiling performance and variance into cost–benefit analyses for public tenders and enterprise contracts, moving beyond headline leaderboard metrics to decision-useful models of expected accuracy and robustness.
- Tools/workflows: Economic simulators linking token costs, ceiling gains, and operational risk; policy templates for evidence-based AI acquisition.
- Assumptions/Dependencies: Reliable cost inputs; domain-specific error cost estimates; organizational willingness to adopt evidence-driven procurement.
These applications leverage the paper’s central insights: fixed prompts systematically underestimate LM performance; chain-of-thought is the dominant, cost-effective driver of gains; and ceiling-aware, structured prompting yields more robust, decision-useful benchmarks and deployments.
Collections
Sign up for free to add this paper to one or more collections.