- The paper introduces SingSong, a system that generates instrumental accompaniments from vocal inputs using a modified AudioLM model.
- It employs musical source separation on paired vocal-instrumental data to achieve significant improvements in Frechet Audio Distance scores.
- User studies highlight the system's musical compatibility, paving the way for further enhancements in harmonic generation and real-world applicability.
SingSong: Generating Musical Accompaniments from Singing
The paper "SingSong" introduces a novel system designed to generate instrumental accompaniments for vocal inputs using advancements in musical source separation and generative audio modeling. This work leverages a modified version of AudioLM to create expressive, coherent instrumental tracks that accompany user-provided singing. The following essay provides an in-depth analysis of the methodologies and outcomes of the SingSong system.
System Overview
SingSong generates instrumental accompaniments by combining musical source separation with generative audio models. Initially, a source separation algorithm is applied to a large dataset to extract aligned vocal-instrumental pairs. The system then trains an adapted version of AudioLM to handle the conditional generation of instrumentals based upon these vocal inputs.

Figure 1: SingSong generates instrumental music to accompany input vocals, thereby allowing users to create music featuring their own voice. At inference time, the system outputs an instrumental to accompany given vocals.
Methodology
Data Processing and Model Training
The training process starts by applying source separation to approximately one million tracks to produce the necessary data pairs. AudioLM is adapted for the task by converting the unconditional model into a conditional "audio-to-audio" generative model, utilizing vocal inputs as conditions for generating instrumental outputs.
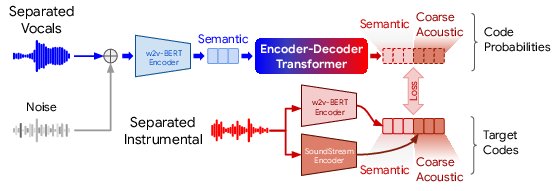
Figure 2: We adapt AudioLM for training on source-separated vocals and generate instrumentals with a sequence-to-sequence approach.
Audio Featurization
A critical challenge in this task is ensuring the system can generalize from training data (source-separated vocals) to real-world inputs (isolated vocals). The study explores different featurization techniques, finding that adding noise and modifying AudioLM features significantly improves the system's generalization capabilities:
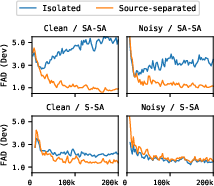
Figure 3: Experimenting with featurizations to enhance generalization from source-separated to isolated vocals results in strong performance on both input types.
Experiments and Evaluation
Quantitative and Qualitative Results
SingSong's performance was evaluated using the Frechet Audio Distance (FAD), demonstrating significant improvements over baseline systems. Additionally, a listening study was conducted, showing user preference for SingSong's outputs.
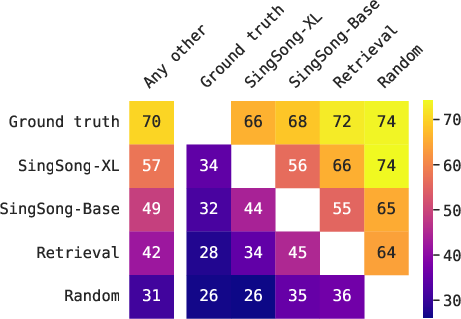
Figure 4: Listening study results indicate a preference for SingSong over retrieval baselines, with the majority favoring its outputs for musical compatibility.
Future Directions and Considerations
SingSong has shown potential in generating useful and appealing accompaniments, yet there are opportunities for further refinement. Future work could focus on enhancing harmonic generation, improving audio fidelity by adjusting sampling rates, and broadening the system's applicability to other sources beyond vocals.
Toward Real-World Applications
Experiments with the Vocadito dataset revealed that while results are promising, further adaptations to handle user-recorded inputs are necessary. Integrating pitch correction or a click-track could enhance real-world performance.
Ethical Implications
The system raises ethical considerations related to cultural influence and musical authorship, highlighting the need for balance between creative freedom and impact on existing musical cultures.
Conclusion
SingSong represents a significant step towards simplifying music creation through the use of AI, providing an intuitive interface for generating instrumental accompaniments from singing. Its development showcases the potential of integrating source separation and generative models, setting the stage for future explorations in music AI applications.