StemGen: A music generation model that listens
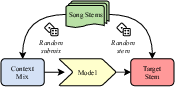
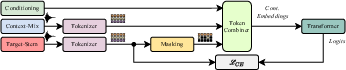
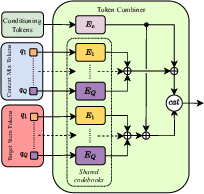
Abstract: End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
- “WaveNet: A Generative Model for Raw Audio,” arXiv, 2016, 1609.03499.
- “High Fidelity Neural Audio Compression,” arXiv, 2022, 2210.13438.
- “High-Fidelity Audio Compression with Improved RVQGAN,” arXiv, 2023, 2306.06546.
- “MusicLM: Generating Music From Text,” arXiv, 2023, 2301.11325.
- “Simple and Controllable Music Generation,” arXiv, 2023, 2306.05284.
- “VampNet: Music Generation via Masked Acoustic Token Modeling,” arXiv, 2023, 2307.04686.
- “Noise2Music: Text-conditioned Music Generation with Diffusion Models,” arXiv, 2023, 2302.03917.
- “Multi-instrument Music Synthesis with Spectrogram Diffusion,” arXiv, 2022, 2206.05408.
- “Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion,” arXiv, 2023, 2301.11757.
- Nicholas Cook, Music, Imagination, and Culture, ACLS Humanities E-Book. Clarendon Press, 1990.
- “Jukebox: A Generative Model for Music,” arXiv, 2020, 2005.00341.
- “SingSong: Generating musical accompaniments from singing,” arXiv, 2023, 2301.12662.
- “Multi-Source Diffusion Models for Simultaneous Music Generation and Separation,” arXiv, 2023, 2302.02257.
- “SoundStorm: Efficient Parallel Audio Generation,” arXiv, 2023, 2305.09636.
- “CLAP: Learning Audio Concepts From Natural Language Supervision,” arXiv, 2022, 2206.04769.
- J. Ho and T. Salimans, “Classifier-Free Diffusion Guidance,” arXiv, 2022, 2207.12598.
- “Cutting music source separation some Slakh: A dataset to study the impact of training data quality and quantity,” in Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2019.
- MIDI Manufacturers Association, “Complete MIDI 1.0 Detailed Specification,” http://www.midi.org/techspecs/gm.php, 1999/2008.
- “LLaMA: Open and Efficient Foundation Language Models,” arXiv, 2023, 2302.13971.
- “Fréchet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms,” in Proc. Interspeech 2019, 2019, pp. 2350–2354.
- M. T. Pearce, The construction and evaluation of statistical models of melodic structure in music perception and composition, Ph.D. thesis, City University London, 2005.
- M. Pearce and G. Wiggins, “Expectation in melody: The influence of context and learning,” Music Perception, vol. 23, pp. 377–405, 06 2006.
- L.-C. Yang and A. Lerch, “On the evaluation of generative models in music,” Neural Computing and Applications, vol. 32, 05 2020.
- “Multitrack Music Transcription with a Time-Frequency Perceiver,” in IEEE Int. Conf. on Acoustics, Speech and Sig. Proc. (ICASSP), 2023, pp. 1–5.
- “Modeling Beats and Downbeats with a Time-Frequency Transformer,” in IEEE Int. Conf. on Acoustics, Speech and Sig. Proc. (ICASSP), 2022, pp. 401–405.
- W.-T. Lu and J.-C. Wang and M. Won and K. Choi and X. Song, “SpecTNT: a Time-Frequency Transformer for Music Audio,” in International Society for Music Information Retrieval Conference, 2021.
- “To Catch A Chorus, Verse, Intro, or Anything Else: Analyzing a Song with Structural Functions,” in IEEE Int. Conf. on Acoustics, Speech and Sig. Proc. (ICASSP), 2022, pp. 416–420.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.