- The paper introduces a dual-stage framework using an LSTM-based EEG feature extractor with contrastive learning and a conditional GAN for image generation.
- Experimental results show superior Inception Scores (up to 7.33) and enhanced image fidelity compared to previous methods.
- The approach effectively tackles small EEG datasets through differentiable data augmentation and mode-seeking regularization to prevent overfitting and mode collapse.
EEG2IMAGE: Image Reconstruction from EEG Brain Signals
Introduction
The paper presents a framework for reconstructing visual images from non-invasive EEG signals, addressing the challenge of synthesizing images from small EEG datasets. The approach leverages contrastive learning for EEG feature extraction and a modified conditional GAN for image generation. The motivation is to advance BCI technology, particularly for neuro-rehabilitation and communication for disabled individuals, by enabling direct translation of brain activity into visual content.
Framework Architecture
The proposed system consists of two main components: an EEG feature extractor and an image generator. The feature extractor is an LSTM network with 128 hidden units, mapping EEG signals to a 128-dimensional feature space. The image generator is a conditional DCGAN, augmented with differentiable data augmentation and mode-seeking regularization to address data scarcity and mode collapse.
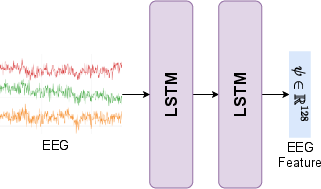

Figure 1: The overall framework: (a) LSTM-based EEG feature extraction; (b) Conditional GAN with data augmentation for robust image synthesis.
The feature extraction phase employs a contrastive learning regime using semi-hard triplet loss. This metric learning approach structures the feature space such that EEG signals corresponding to similar visual stimuli are clustered together, while those from different classes are separated by a margin. The triplet loss formulation is:
θminE[∣∣fθ(xa)−fθ(xp)∣∣22−∣∣fθ(xa)−fθ(xn)∣∣22+β]
where fθ maps EEG signals to the feature space. Empirical results show that triplet loss yields superior k-means clustering accuracy (53% for Object dataset, 49% for Character dataset) compared to softmax-based classification (17.8% and 16.3%, respectively).
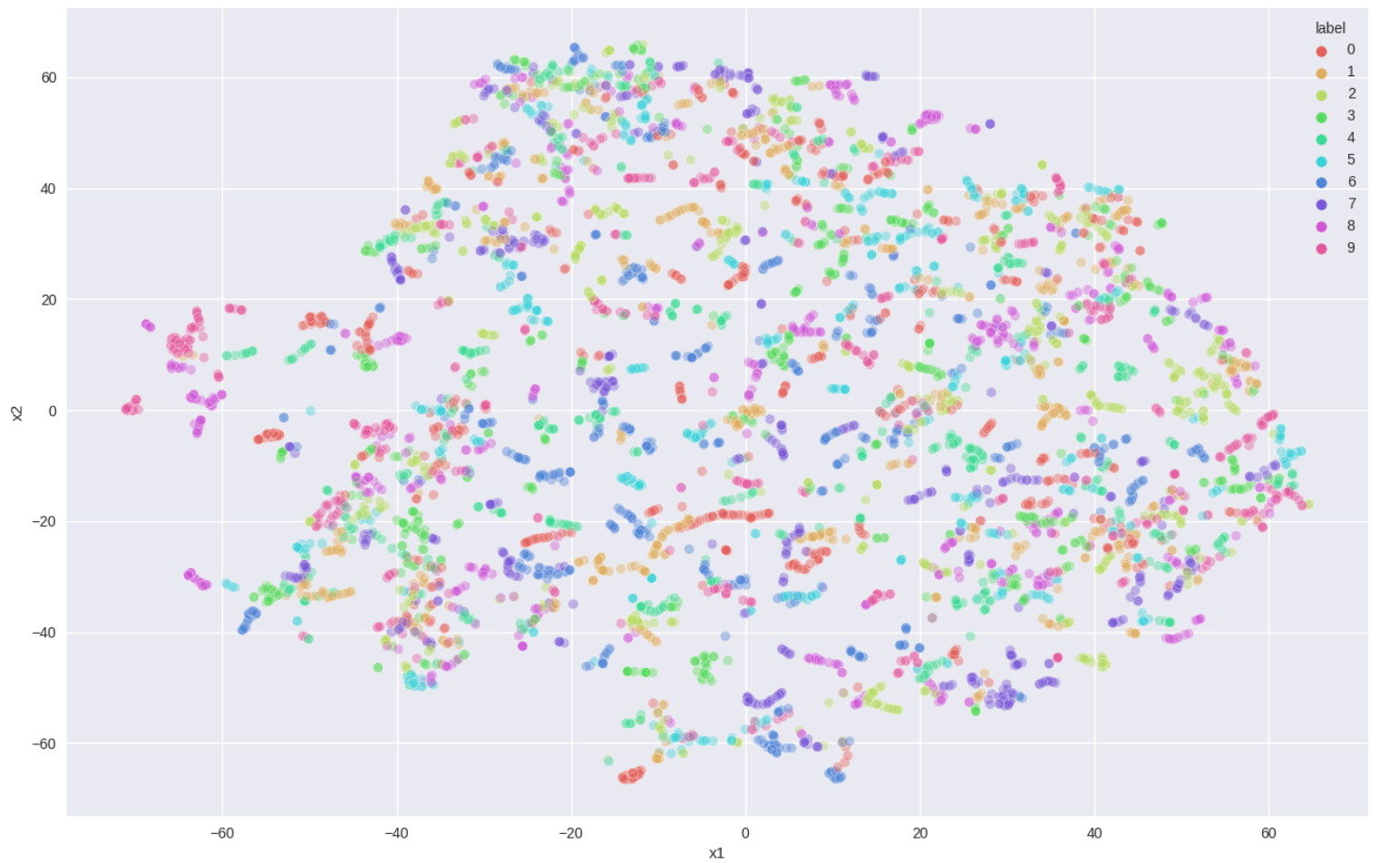
Figure 2: t-SNE visualization of EEG feature space learned with label supervision; test classification accuracy 0.75, k-means accuracy 0.18.
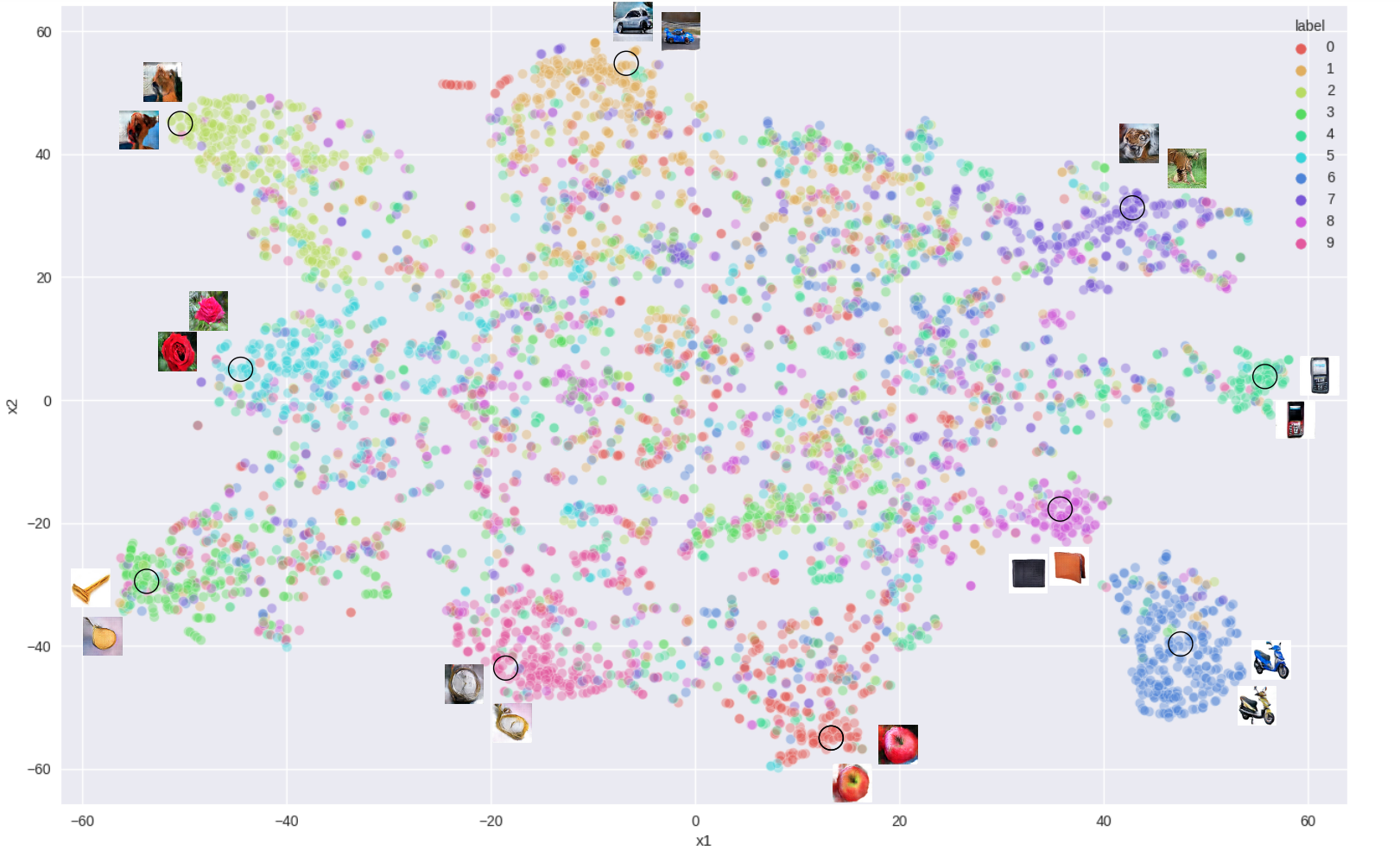
Figure 3: t-SNE visualization of EEG feature space learned with triplet loss; test k-means accuracy 0.53. Clustered EEG-based generated images are shown.
Conditional GAN for Image Synthesis
The image synthesis module utilizes a conditional DCGAN, modified in three key ways:
- Hinge Loss: For stable GAN training and improved separation between real and generated images.
- Differentiable Data Augmentation (DiffAug): Applied between generator and discriminator to prevent discriminator overfitting and vanishing gradients, critical for small datasets.
- Mode-Seeking Regularization: Encourages diversity in generated images, mitigating mode collapse.
The generator receives the 128D EEG feature vector and a noise vector sampled from N(0,I), producing 128×128 images. The discriminator is conditioned on EEG features and augmented images.
Experimental Results
Quantitative Evaluation
The framework is evaluated on the Object and Character datasets from [Kumar2018], using Inception Score (IS) as the primary metric. The proposed method achieves an IS of 6.78 on the Object dataset, outperforming AC-GAN (4.93) and ThoughtViz (5.43). Per-class IS values are consistently high, with the lowest at 5.44 and the highest at 7.33.
Qualitative Comparison
Qualitative analysis demonstrates that the proposed framework generates images with higher fidelity and semantic relevance compared to ThoughtViz, both for object and character classes.


Figure 4: Comparison of images generated from EEG signals: ThoughtViz (left) vs. EEG2Image (right) on Object dataset.


Figure 5: Comparison of images generated from EEG signals: ThoughtViz (left) vs. EEG2Image (right) on Character dataset.
Ablation Studies
Ablation experiments isolate the contributions of mode-seeking regularization and DiffAug. Training without either yields an IS of 3.61; adding mode-seeking regularization increases IS to 4.27; adding DiffAug alone boosts IS to 6.5. The combination of both yields the best results.



Figure 6: Ablation study on Object dataset: (a) no mode loss/data augmentation, (b) mode loss only, (c) data augmentation only.
Implementation Considerations
- Data Requirements: The framework is designed for small EEG datasets (230 samples per dataset), enabled by data augmentation and regularization.
- Computational Resources: Training the LSTM and GAN components is feasible on modern GPUs; the model size and input dimensionality are modest.
- Generalization: The use of contrastive learning and data augmentation improves generalization to unseen EEG samples.
- Limitations: The current approach is limited to 128×128 image resolution and small datasets; scaling to higher resolutions or larger datasets may require architectural modifications and more advanced regularization.
Theoretical and Practical Implications
The results demonstrate that contrastive learning significantly enhances EEG feature representation for downstream generative tasks. The integration of mode-seeking regularization and differentiable data augmentation is shown to be critical for robust GAN training under data scarcity. The framework sets a precedent for BCI applications in image reconstruction, with potential extensions to other modalities (e.g., speech, video) and more complex visual domains.
Future Directions
Potential avenues for future research include:
- Scaling to larger and more diverse EEG datasets.
- Exploring self-supervised or unsupervised feature extraction for EEG signals.
- Increasing image resolution and semantic complexity.
- Real-time deployment in assistive BCI systems.
- Cross-modal generative modeling (e.g., EEG-to-text, EEG-to-video).
Conclusion
The EEG2IMAGE framework establishes a robust pipeline for reconstructing images from EEG signals using small datasets. By combining contrastive learning for feature extraction and a modified conditional GAN for image synthesis, the approach achieves superior quantitative and qualitative results compared to prior methods. The demonstrated effectiveness of data augmentation and regularization strategies provides a foundation for future work in scalable, high-fidelity brain-to-image reconstruction and broader BCI applications.