- The paper provides a comprehensive overview of KG construction, comparing RDF and Property Graph models for integrating diverse data.
- The paper details a step-by-step pipeline for KG construction covering data acquisition, ontology management, and entity resolution with incremental updates.
- The paper highlights challenges like scalability, toolset interoperability, and ensuring robust data quality and provenance in real-world applications.
Construction of Knowledge Graphs: State and Challenges
The paper "Construction of Knowledge Graphs: State and Challenges" provides a comprehensive overview of the methodologies, requirements, and challenges involved in the construction and incremental maintenance of knowledge graphs (KGs). The research identifies critical components and processes necessary to build high-quality KGs and discusses both theoretical and practical implications. Below, the core areas covered by the paper are organized into several key sections.
Knowledge Graph Models and Requirements
The paper begins by differentiating between two primary graph data models used in knowledge graphs: the Resource Description Framework (RDF) and the Property Graph Model (PGM). Each model offers different advantages depending on the application's requirements and data characteristics. KGs are expected to integrate heterogeneous data from multiple sources — structured, semi-structured, and unstructured — in a semantically rich manner, often necessitating schema-flexibility and ontological descriptions.
Figure 1 illustrates a simplified knowledge graph integrating data from multiple domains and highlights the importance of semantic structures like ontologies in allowing inference over existing data.
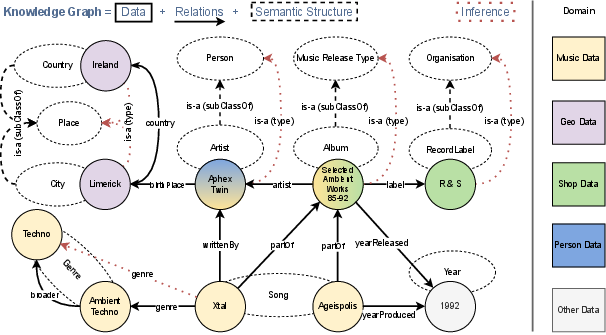
Figure 1: Simplified Knowledge Graph (KG) example demonstrating integrated information from five domains.
KG Construction and Maintenance Pipeline
The process of constructing and maintaining KGs involves distinct phases and tasks, such as data acquisition, knowledge extraction, ontology management, and quality assurance. The paper highlights the incremental KG construction as a significant challenge, detailing the need to incorporate changes without full re-computation.
Figure 2 depicts the incremental knowledge graph construction pipeline, showcasing tasks from data acquisition to knowledge extraction and integration.
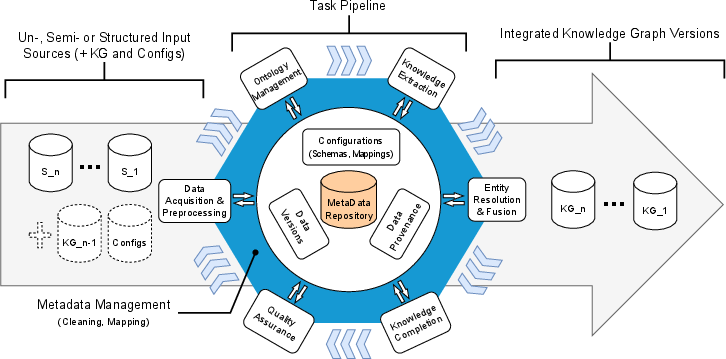
Figure 2: Incremental Knowledge Graph Construction Pipeline
Key Tasks in KG Construction
- Data Acquisition and Preprocessing: Includes identifying relevant data sources and preprocessing for consistency and quality. Techniques involve metadata extraction and data cleansing.
- Metadata Management: Encompasses managing metadata types relevant to provenance, structural relations, and quality metrics.
- Ontology Management: Consists of developing and incrementally updating the ontology to adapt to new information and domain-specific nuances.
- Knowledge Extraction: Involves processes like Named Entity Recognition, entity linking, and relation extraction, often from unstructured data sources such as text.
- Entity Resolution and Fusion: Focuses on identifying and merging duplicate entities within and across datasets to ensure singular representations of real-world entities.
- Quality Assurance: Implements measures to maintain data correctness, consistency, and completeness throughout the KG lifecycle.
Figure 3 illustrates the knowledge extraction process from a sample sentence, bridging text with the DBpedia knowledge graph.
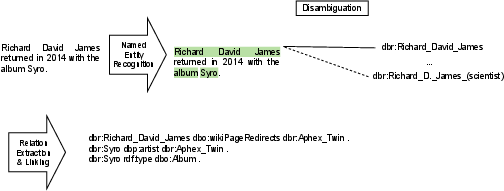
Figure 3: Knowledge Extraction steps for an example sentence linking entities and relations to the DBpedia KG.
Challenges and Future Directions
The paper identifies several essential challenges currently impeding the efficient construction of KGs:
- Incremental Updates and Scalability: A streamlined approach for continuous integration of data is necessary to maintain KGs' freshness and scalability.
- Toolset Accessibility and Interoperability: There is a demand for open-source, modular toolsets to support diverse data models and facilitate broader collaboration.
- Data Quality and Provenance: Ensuring high data quality through robust provenance tracking and error mitigation strategies is critical for building trust in KGs.
- Coordinated Data Management: Incorporating both data and metadata management cohesively is vital for a structured, unified view to facilitate operational effectiveness and analytical insights.
The paper also explores ontology and entity merging strategies, as demonstrated in Figure 4, emphasizing the nuanced challenges of coherent data integration.
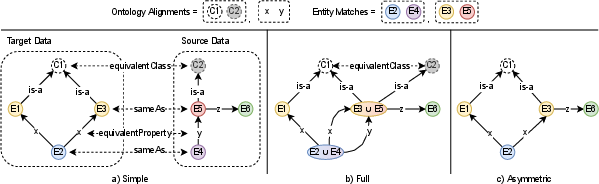
Figure 4: Ontology and Entity Merging Strategies.
Conclusion
This discussion of knowledge graph construction highlights existing challenges and offers insights into future research and technological advancements needed to enhance KG methodologies. Emphasizing the integration of scalable, high-quality, and open-source solutions is vital to improving the current state of knowledge graphs, thereby extending the applicability of KGs in real-world scenarios. The findings underscore the importance of evolution in both research paradigms and technical implementations to keep pace with ever-growing and changing datasets.