- The paper demonstrates that LLMs for code tasks experience significant performance drops in out-of-domain settings, with retrieval-based adaptation improving BLEU scores by over 10 points.
- It employs hierarchical data separation and evaluates code summarization and generation using BLEU and CodeBLEU metrics to highlight vulnerabilities during domain shifts.
- Combining multitask learning, meta-learning, and retrieved supervision, the study outlines effective strategies for adapting models across diverse software domains.
Exploring Distributional Shifts in LLMs for Code Analysis
Introduction
The increasing deployment of LLMs in software environments demands careful examination of their generalization capabilities, especially when confronted with distributional shifts. The paper "Exploring Distributional Shifts in LLMs for Code Analysis" (2303.09128) systematically investigates how LLMs designed for programming tasks adapt to out-of-domain data. Focusing on two key applications—code summarization and code generation—the study evaluates the performance of CodeT5, Codex, and ChatGPT across different domain boundaries such as organization, project, and module.
In addressing the challenges posed by distribution shifts, the paper considers hierarchical data separation (Figure 1), setting the foundation for subsequent adaptation strategies. This approach elucidates the models' performance vulnerabilities when subjected to previously unseen organizational configurations.
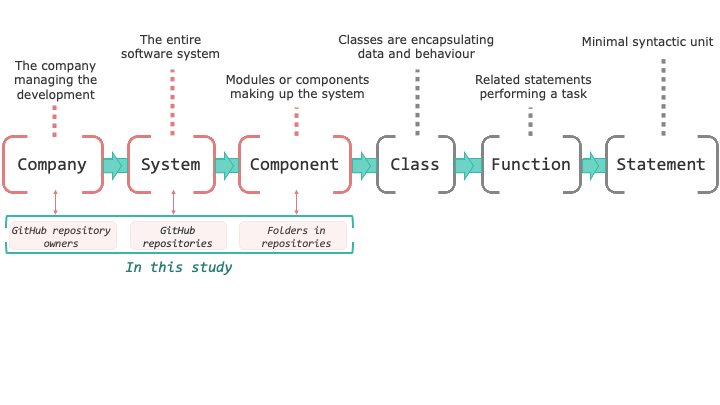
Figure 1: Organization of a software system by the granularity of its components.
Domain Adaptation and Model Evaluation
The paper evaluates models on code summarization and generation tasks, employing BLEU and CodeBLEU as metrics. It underscores significant performance deterioration in an out-of-domain setting, particularly for code summarization tasks. For instance, adapting models with few in-domain examples significantly enhances BLEU score by over 10 points. Notably, multitask learning (MTL) combined with few-shot fine-tuning using retrieved examples from training data achieves substantial performance improvements, surpassing direct fine-tuning in low-data scenarios.
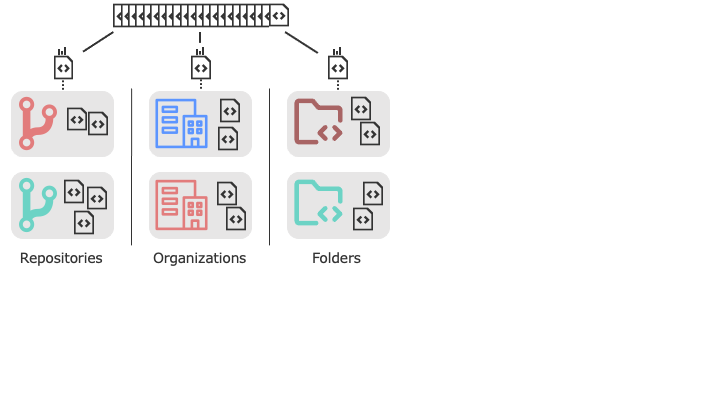
Figure 2: We group the functions from CodeSearchNet by repos, orgs, and folders they belong to.
The paper pioneers a strategy using retrieved examples for domain adaptation, emphasizing retrieval-based example selection as an effective approach for enhancing generalization. The study finds that Codex and ChatGPT exhibit notable sensitivity to instructional variations and demonstrations, with retrieved example demonstrations particularly effective for Codex in low-data settings.
Strategic Model Adaptation
To surmount the impracticality of labeled in-domain data, the paper experiments with meta-learning and multi-task learning. Results reveal these approaches alone do not wholly resolve out-of-domain generalization issues; however, combining them with retrieved supervision from unlabeled data fosters robust performance even in extreme scarcity of labeled examples (Figure 3). Codex demonstrates significant performance gains when leveraging retrieved similar instances for in-context learning.
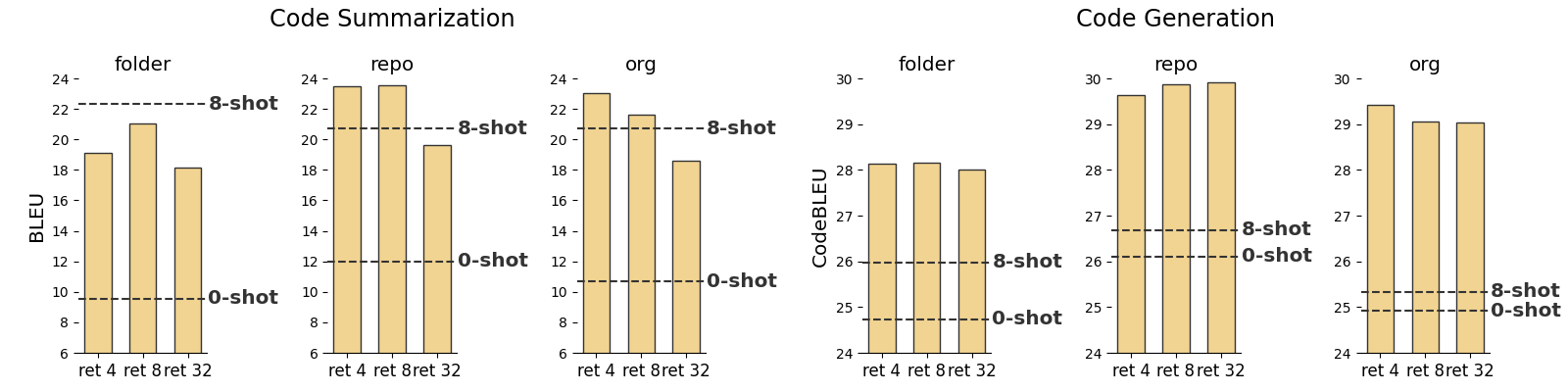
Figure 3: CodeT5 model finetuned with retrieved supervision using different number of retrieved examples per test sample. Scores reported are BLEU for code summarization and CodeBLEU for code generation. CodeT5 MTL model performances in zero-shot, and 8-shot (ID) scenarios are shown with dotted lines for reference.
A broader applicability is tested by adapting models simultaneously to various domains using diverse retrieved examples for adaptation. This methodology proves effective, minimizing the necessity to maintain separate domain-specific model versions, particularly viable for CodeT5 in code generation tasks.
Conclusion
The paper critically assesses the generalization capacities of LLMs on code tasks through multi-domain evaluation settings. It highlights distribution shifts as real and challenging obstacles, recommending retrieval-based example selection combined with meta-learning and multi-task learning for improved adaptability. The broader implications of these findings suggest methodological refinements in training LLMs to counter domain shifts, thereby augmenting their utility in real-world code generation and analysis applications. The research delineates pathways for future exploration in LLMs, emphasizing nuanced adaptation techniques and their integration into software development workflows.