- The paper introduces a benchmark for evaluating LLMs on binary code analysis tasks such as function name recovery and code summarization.
- The study uses real-world datasets from projects like FFmpeg and OpenSSL across architectures like x86, ARM, and MIPS, measuring metrics including F1-score and BLEU-4.
- The paper finds that models such as CodeLlama-34b and ChatGPT outperform others, with fine-tuning further enhancing performance in practical reverse engineering scenarios.
An Empirical Study on the Effectiveness of LLMs for Binary Code Understanding
Introduction
The paper "An Empirical Study on the Effectiveness of LLMs for Binary Code Understanding" investigates the application of LLMs to the domain of binary code analysis, which is pivotal for tasks such as malware detection, software vulnerability discovery, and reverse engineering. Unlike human-readable source code, binary code lacks semantic information, presenting significant challenges. This research evaluates whether LLMs can bridge this gap, focusing on two key tasks: function name recovery and binary code summarization.
Methodology
The authors propose a benchmark to assess the LLMs' capabilities in binary code understanding. This involves compiling a comprehensive dataset from real-world projects like FFmpeg and OpenSSL, targeting multiple architectures (x86, x64, ARM, MIPS) and various compiler optimization levels (O0 to O3). The binaries are decompiled to pseudo code using IDA Pro, stripped of symbolic information to simulate realistic reverse engineering scenarios.
A robust evaluation process is established where popular LLMs – both general-domain (e.g., ChatGPT, Llama) and code-domain (e.g., CodeLlama, WizardCoder) – are tested against expert models like SymLM and HexT5. Performance is measured using Precision, Recall, F1-score for function name recovery, and BLEU-4, METEOR, Rouge-L for binary code summarization (Figure 1).
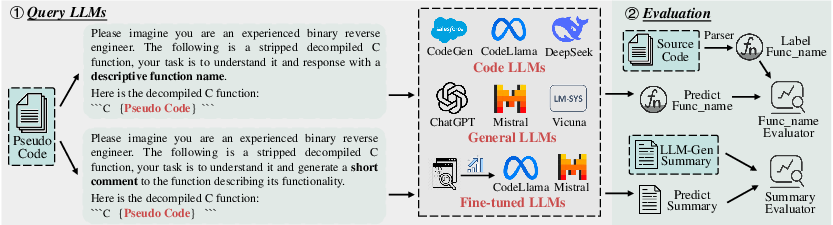
Figure 1: An overview of the evaluation process.
Results
The study finds that LLMs, particularly CodeLlama-34b and ChatGPT, show promise in binary code understanding. CodeLlama-34b achieved superior results in function name recovery across different architectures, especially on MIPS, likely due to its simpler instruction set. However, LLMs in general show minimal performance variance across optimization levels, indicating robustness to code transformations applied during compilation.
In binary code summarization, ChatGPT excels, suggesting general-domain LLMs handle natural language description tasks better due to enhanced contextual understanding. The results also highlight the influence of pseudo code and symbol information lengths on performance (Figures 5 and 6). Longer pseudo code generally improves function name recovery until complexity becomes overwhelming, while more symbol information consistently benefits both tasks.

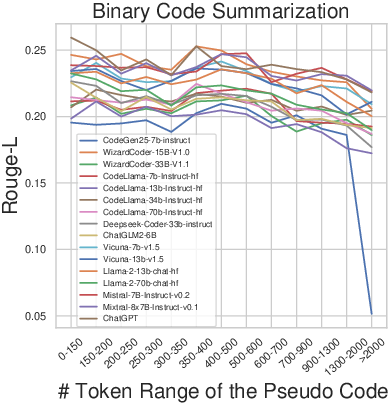
Figure 2: Impact of pseudo code length on performance.
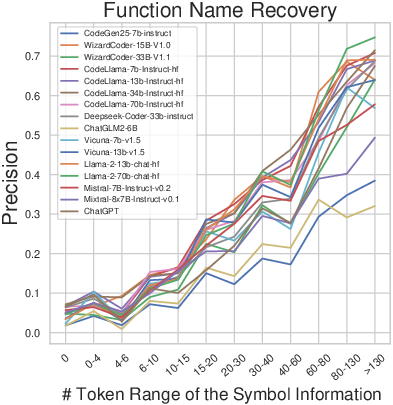
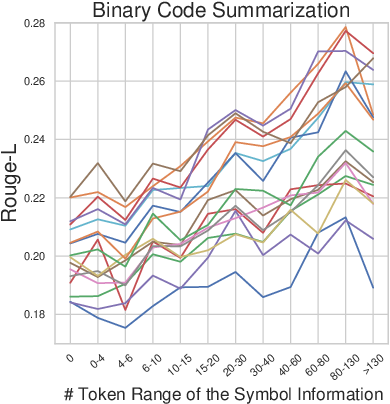
Figure 3: Impact of symbol information length on performance.
Fine-Tuning and Practical Applications
The research explores fine-tuning LLMs with binary-centric datasets to inject domain-specific knowledge, resulting in significant performance improvements (Figure 4). This suggests fine-tuning as a viable approach to optimize LLMs for specific binary analysis tasks.
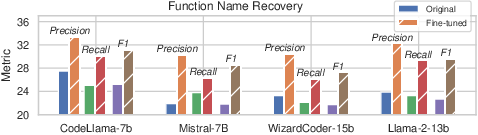
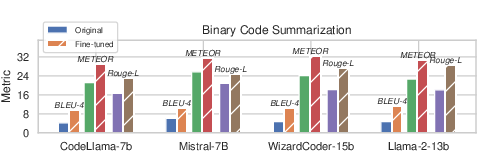
Figure 4: Comparison of original and fine-tuned LLMs on performance.
Case studies demonstrate LLMs' practical utility in real-world scenarios, such as malware analysis, where they can assist in deciphering decompiled code through function summarization and naming — tasks traditionally reserved for human reverse engineers (Figures 8 and 9).
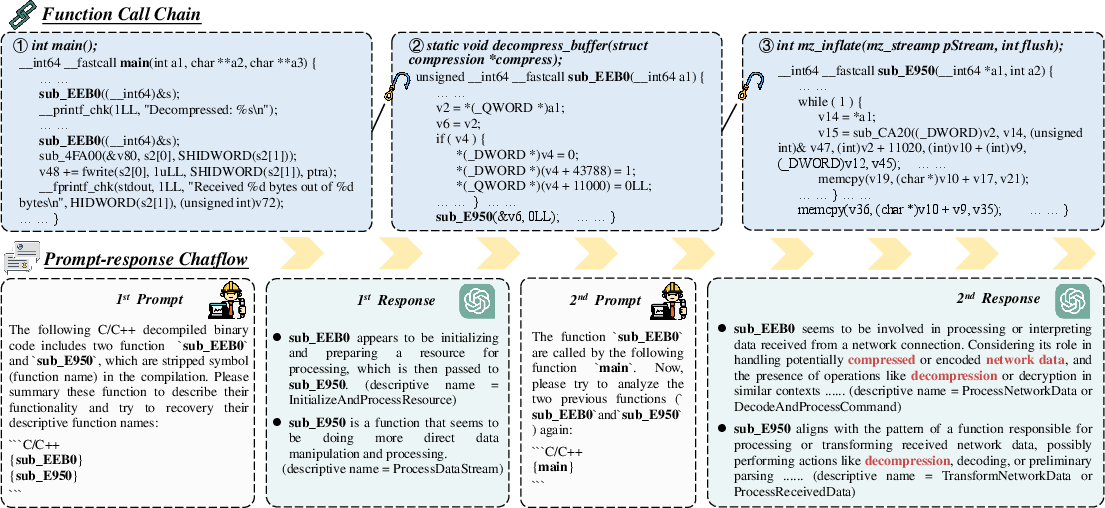
Figure 5: An example of binary code understanding in a real-world virus with ChatGPT.

Figure 6: The chatflow of analyzing the binary function getRemovableDisk from TrojanCockroach with ChatGPT.
Conclusions and Future Directions
The study concludes that LLMs are promising tools for binary code understanding, exhibiting strong capabilities in both function name recovery and code summarization across various architectures and optimization settings. However, there is room for improvement, particularly in cases involving complex or obfuscated binaries.
Future work should focus on developing domain-specific models with longer context windows, improved handling of non-intuitive code, and the integration of multimodal information sources. Advancements in these areas could further position LLMs as integral components of software security and reverse engineering toolchains.