When Names Disappear: Revealing What LLMs Actually Understand About Code
Abstract: LLMs achieve strong results on code tasks, but how they derive program meaning remains unclear. We argue that code communicates through two channels: structural semantics, which define formal behavior, and human-interpretable naming, which conveys intent. Removing the naming channel severely degrades intent-level tasks such as summarization, where models regress to line-by-line descriptions. Surprisingly, we also observe consistent reductions on execution tasks that should depend only on structure, revealing that current benchmarks reward memorization of naming patterns rather than genuine semantic reasoning. To disentangle these effects, we introduce a suite of semantics-preserving obfuscations and show that they expose identifier leakage across both summarization and execution. Building on these insights, we release ClassEval-Obf, an obfuscation-enhanced benchmark that systematically suppresses naming cues while preserving behavior. Our results demonstrate that ClassEval-Obf reduces inflated performance gaps, weakens memorization shortcuts, and provides a more reliable basis for assessing LLMs' code understanding and generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
When Names Disappear: What Do AI Models Really Understand About Code?
Overview: What is this paper about?
This paper looks at how AI models that read and write code (called LLMs, or LLMs) actually “understand” programs. The authors ask a simple question: do these models really reason about how code works, or do they mostly lean on human-friendly clues like variable and function names?
To test this, they hide or change names in code (like renaming MinesweeperGame to class1) without changing what the code does, and then see how well the models perform on different tasks.
The big questions the paper asks
The authors focus on two kinds of information in code:
- The structure or semantics: how the code runs, its logic, and the way data moves through it.
- The names or “naturalness”: the labels humans use (like variable names, function names, and comments) that hint at intent and meaning.
They ask:
- If we remove helpful names but keep the code’s behavior the same, do models still understand the code’s intent (for example, summarizing what a program does)?
- Do models still correctly predict what the code will output when run?
- Are current benchmarks accidentally rewarding models for memorizing name patterns instead of truly understanding code?
How did they study it? Methods in plain language
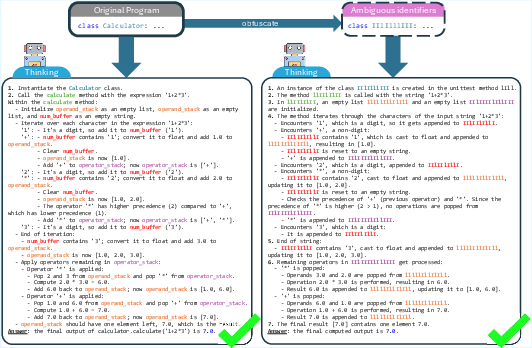
The team took real code and applied “semantics-preserving obfuscations.” That’s a fancy way of saying they changed the names in the code but kept the logic and behavior identical. Think of it like replacing the labels on a well-organized toolbox with confusing or random stickers—same tools, harder to understand at a glance.
They tested models on two kinds of tasks:
- Intent summarization: Can the model explain what the code is for, in plain English?
- Execution/output prediction: Given inputs, can the model say what the program will output?
They used two types of datasets:
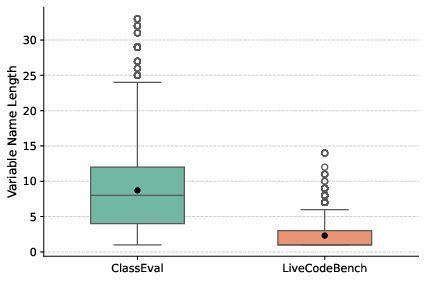
- Intent-rich, real-world code (ClassEval), where names carry a lot of meaning.
- Algorithm-heavy, competitive programming code (LiveCodeBench), where names are often short and not very descriptive.
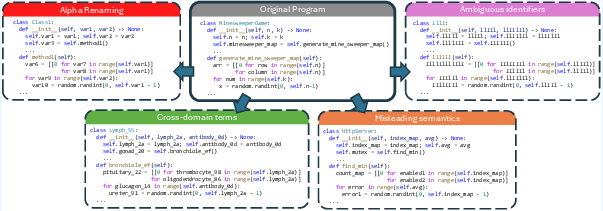
They tried four name-changing strategies that kept the code working the same way:
- Simple renaming (alpha-renaming): Replace names with neutral placeholders like
var1,method2. - Ambiguous names: Use confusing names that look similar (like
IlllIlll). - Cross-domain names: Use terms from unrelated fields (like medical words) to break domain hints.
- Misleading names: Give names that suggest the wrong behavior (like calling a sum function
compute_max).
They then measured model performance before and after these changes, using several modern LLMs (such as GPT-4o, Qwen-Coder, DeepSeek, and Llama).
What did they find, and why is it important?
The authors report three main results:
- Summarization drops a lot when names disappear, especially for real-world code.
- When names like
MinesweeperGameare present, models produce good summaries that capture intent. - After renaming, models often fall back to boring, line-by-line descriptions (they describe what happens step by step instead of explaining the big idea).
- This shows that models rely heavily on names to figure out “what” the program is for.
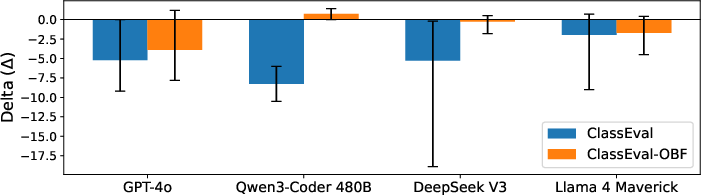
- Even execution prediction (which should only depend on structure) gets worse without names.
- This is surprising. The code still runs the same way, so in theory the model should predict outputs just as well.
- Performance still drops across several models and datasets.
- The most likely reason: models are using names as shortcuts or “memory keys” to recall patterns they’ve seen before, instead of reasoning through the code every time.
- Evidence of memorization
- The authors ran a “memory check” by feeding new inputs so outputs would be different from those in training.
- With original names, models sometimes reproduced old outputs from memory instead of computing new ones.
- With obfuscated names, this memorization effect went down a lot, which suggests names were acting like triggers for memorized code-output pairs.
Because of these results, the authors created a new benchmark called ClassEval-Obf (the “Obf” stands for obfuscated). It reduces name-based shortcuts while keeping the code behavior the same. They show that this benchmark gives a fairer, more reliable measure of true code understanding.
What’s the impact? Why this matters
This work matters for anyone building or evaluating AI for coding:
- It shows that strong scores on popular benchmarks may be partly inflated by models using names as hints rather than doing deep reasoning.
- It recommends better testing: hide or change names and use new input-output pairs to reduce memorization.
- It provides tools and a dataset (ClassEval-Obf) to help researchers and developers measure genuine code understanding.
- Long term, this could lead to AI systems that truly grasp program logic and intent, not just “look up” familiar patterns.
In short
- Code has two channels: how it works (structure) and what names tell us (intent).
- Today’s models often rely on names more than we expect, even for tasks that should depend only on behavior.
- Removing names exposes this reliance and pushes models to reason more.
- The paper offers a better benchmark to test true understanding, helping AI move beyond memorization toward real code comprehension.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Cross-language generalization is untested: results are reported primarily on Python-like code; effects for statically typed languages (e.g., Java, C++, C#), languages with heavy reflection (e.g., Java, C#), and minified/transpiled ecosystems (e.g., JavaScript/TypeScript) are unknown.
- Comments/docstrings and other natural-language artifacts are not systematically controlled: the study focuses on identifiers, leaving open how comments, docstrings, commit messages, or surrounding NL contexts affect intent and execution under obfuscation.
- Semantics-preserving guarantee lacks formalization: the “capture-avoiding obfuscation harness” is not specified in enough detail to verify that reflection, metaprogramming, dynamic attribute access, string-based getattr/setattr, serialization, or framework conventions (e.g., Django “magic” names) are not inadvertently broken by renaming.
- External API/library identifiers handling is unclear: whether imported symbols, framework-specific identifiers, dunder/special methods, or reserved/builtin names are safely excluded from renaming (and how this impacts results) is not detailed.
- Tokenization artifacts may confound conclusions: “ambiguous” identifiers (e.g., IlllIll) and long opaque tokens likely alter subword splits, OOV rates, and context packing; the extent to which performance drops stem from BPE/WordPiece pathologies versus genuine semantic reliance on names is unmeasured.
- No positive-control interventions to disentangle cues: the study does not test whether adding structural signals (types, AST summaries, data-flow edges, SSA form, or symbolic traces) can recover performance lost by name removal, which would strengthen the causal claim about the two channels.
- Limited task coverage: only summarization and I/O prediction are evaluated; effects on code repair, fault localization, test generation, code translation, clone detection, code search, review, and security auditing remain unknown.
- LLM-as-a-judge risks unaddressed: summarization relies on GPT-4o scoring without human raters, inter-rater reliability, calibration, or adversarial checks that the judge itself is robust to obfuscation; potential circularity and bias remain.
- Statistical rigor is insufficiently reported: small post-filter sample sizes (e.g., 37 ClassEval instances), lack of confidence intervals, effect-size estimates, and significance tests leave uncertainty about generality and variance across seeds and runs.
- Prompting and decoding sensitivity is unexplored: the impact of prompt templates, chain-of-thought vs. direct answers, temperature, sampling strategies, and few-shot demonstrations on obfuscation robustness is not analyzed.
- Memorization diagnosis is partial: the input-augmentation “old-output” check suggests leakage but does not quantify training-set overlap, near-duplicate similarity, or retrieval pathways (e.g., via embedding similarity); stronger contamination audits and retrieval tracing are needed.
- Retrieval augmentation/tool-use is not tested: whether enabling code execution tools (e.g., sandboxes), symbolic interpreters, or retrieval of API docs mitigates obfuscation-induced drops is unknown.
- Real-world obfuscation/minification is not evaluated: performance on genuinely obfuscated/minified code in the wild (e.g., ProGuarded JVM code, minified/bundled JS, decompiled binaries) is unmeasured.
- Repository-level and cross-file settings are missing: the impact of obfuscation on repo-scale tasks (SWE-Bench/SWE-Bench Live) with cross-file references, imports, and build systems remains untested; renaming across module boundaries raises additional invariance challenges.
- Degree-of-obfuscation is not parameterized: beyond four discrete strategies, a continuous “strength” scale (e.g., character-level entropy, semantic distance of substituted names) and dose–response curves are not established.
- Alternative obfuscations are unexplored: transformations beyond renaming—formatting/layout changes, control-flow restructuring, dead-code insertion, equivalent boolean/arithmetic rewrites, or AST anonymization—could more precisely isolate structural vs. naturalness reliance.
- Domain-shift side effects of cross-domain names are unquantified: substituting with medical or other domain terms may introduce new semantic priors; whether “unrelated semantic” tokens vs. meaningless tokens differentially impact models is not dissected.
- Causal decomposition of channels is not formalized: there is no explicit causal framework (e.g., counterfactual mediation or Shapley-style attribution) to quantify the contribution of naming vs. structure to task performance.
- Model-internal evidence is absent: probing, representational analyses, or attention/attribution studies to verify whether and how identifiers mediate reasoning are not provided.
- Comparative mitigation strategies are not evaluated: training-time obfuscation augmentation, structure-aware pretraining/fine-tuning, entity-masking objectives, or contrastive learning against misleading names are proposed implicitly but not tested.
- API-level/type information as a compensator is untested: whether adding explicit type annotations, contracts, or interface specs counteracts name removal is unknown.
- Generalization across model families and sizes is limited: only a handful of frontier models are evaluated; broader sweeps across open models (e.g., StarCoder2, CodeLlama variants, Mistral-Code), size scales, and training data regimes are absent.
- Benchmark construction details need clarity: exact prompts, decoding settings, seed control, and license/composition of ClassEval-Obf (including which identifiers were exempted from renaming) are not fully specified for replicability.
- Potential evaluator–subject interference is unmeasured: using the same vendor/model family both as subject and judge could bias scores; cross-judge validation (e.g., Claude, Llama-judge) and human audits are missing.
- Practical developer impact is not quantified: how obfuscation robustness correlates with real-world tasks like code review accuracy, defect detection, or maintenance effort is not assessed.
- Fairness and localization remain open: impacts on non-Latin scripts, multilingual identifiers, or projects with mixed-language codebases are unstudied.
- Security implications are unexplored: whether obfuscation degrades LLM-based vulnerability detection or allows adversaries to hide malicious intent from code models is not evaluated.
- Failure taxonomies are absent: the paper notes “line-by-line narration” under obfuscation but does not categorize failure modes or propose automatic detectors for intent-collapse vs. genuine reasoning.
- Benchmark inflation claim needs broader evidence: the assertion that obfuscation “reduces inflated performance gaps” would be stronger with multi-benchmark meta-analysis, confidence intervals, and replication across independent datasets.
Glossary
- Alpha-renaming: Systematic renaming of identifiers that preserves bindings and program semantics. "Simple structural renaming (alpha-renaming): replace identifiers with role-preserving placeholders;"
- Ambiguous identifiers: Identifier names intentionally made visually confusable (e.g., l vs I) to weaken linguistic cues without changing behavior. "Ambiguous identifiers: replace identifiers with visually ambiguous tokens;"
- AST-based structure loss: A training objective derived from an abstract syntax tree to encourage models to learn program structure. "leverages AST-based structure loss during fine-tuning"
- Capture-avoiding obfuscation harness: A tooling framework that renames identifiers while preventing variable capture and preserving semantics. "we pair a capture-avoiding obfuscation harness with semantics-invariance checks (execution correctness)"
- ClassEval-Obf: An obfuscation-enhanced benchmark that suppresses naming cues while preserving behavior for more reliable evaluation. "we release ClassEval-Obf, an obfuscation-enhanced benchmark that systematically suppresses naming cues while preserving behavior."
- Contrastive pretraining: Pretraining that pulls semantically similar representations together and pushes dissimilar ones apart. "aligns structured and unstructured data via contrastive pretraining and entity-masked prediction."
- Control/data flow: The execution order and data movement pathways within a program. "a structural/semantic channel (syntax, control/data flow, execution behavior)"
- Cross-domain terms: Identifier substitutions using terminology from unrelated fields to break domain-specific naming cues. "Cross-domain terms: substitute identifiers with terms from unrelated fields to break semantic cues in the application domains;"
- Cyclomatic Complexity: A measure of code complexity based on the number of linearly independent paths in the control flow graph. "Cyclomatic Complexity "
- Data-flow edges: Graph links representing data dependencies or transfers between program elements. "pre-train GraphCodeBERT with data-flow edges and variable alignment"
- Dense retrieval: Neural retrieval using dense vector embeddings instead of sparse lexical matching. "a structure-aware dense retrieval model that aligns structured and unstructured data via contrastive pretraining and entity-masked prediction."
- Entity-level renaming: Renaming identifiers at the level of classes, methods, or variables to disrupt semantic cues. "especially entity-level renaming"
- Entity-masked prediction: A pretraining objective where entity tokens are masked and the model must predict them. "via contrastive pretraining and entity-masked prediction."
- Execution-grounded evaluation: Assessment of models based on running code or execution feedback rather than surface similarity. "Parallel research has advanced execution-grounded evaluation."
- Execution/IO prediction: Predicting a program’s outputs given specific inputs without executing the code. "execution/IO prediction."
- Identifier leakage: Spurious influence of human-readable names that reveals task semantics or enables memorization shortcuts. "expose identifier leakage across both summarization and execution."
- Input augmentation: Adding novel inputs to test whether models generalize beyond memorized patterns. "Our additional stress tests with input augmentation indicate that removing names reduces these retrieval effects"
- Intent summarization: Generating descriptions that capture what a program does and why, beyond line-by-line narration. "intent summarization (what/why)"
- LLM-as-a-judge: Using a LLM to evaluate and score outputs according to a rubric. "LLM-as-a-judge: Summaries are evaluated using rubric-based scoring derived from the BigGenBench framework"
- Misleading semantics: Assigning names that suggest incorrect behavior to probe robustness against deceptive cues. "Misleading semantics: assign names that imply incorrect behaviors."
- Natural adversarial attacks: Human-like, semantics-preserving perturbations (e.g., renaming) that can fool code models. "study natural adversarial attacks on code models (including variable renaming)"
- Naturalness channel: The human-interpretable linguistic signals in code (identifiers, comments) that convey intent. "naturalness channel~\cite{hindle2012naturalness}"
- Pass@1: The probability that a correct solution appears in the first sampled attempt. "Pass@1 drops from $85.7$ to $76.1$"
- Pass@3: The probability that a correct solution appears within the first three sampled attempts. "Pass@3 from $89.2$ to $83.3$."
- Program-graph representation: A structured graph encoding of program elements and relations to capture behavior. "introduce PerfoGraph, a program-graph representation that injects numerical and aggregate-structure information"
- Semantics-invariance checks: Tests ensuring transformations leave program behavior unchanged, often via execution correctness. "semantics-invariance checks (execution correctness)"
- Semantics-preserving obfuscations: Name-only transformations that reduce natural-language cues while keeping program behavior intact. "we introduce a suite of semantics-preserving obfuscations"
- Structure-aware dense retrieval: Retrieval that incorporates program or document structure into dense embeddings. "a structure-aware dense retrieval model"
- Unit-test execution feedback: Using unit-test outcomes to guide training or generation toward functional correctness. "grounds generation in unit-test execution feedback via reinforcement learning"
- Variable alignment: Mapping corresponding variables across different representations or contexts to improve modeling. "data-flow edges and variable alignment"
Practical Applications
Immediate Applications
The following items can be deployed now to improve evaluation, safety, and day-to-day use of code LLMs by exploiting the paper’s findings on identifier leakage, semantics-preserving obfuscation, and pre/post-obfuscation deltas.
Industry and DevTools
- ClassEval-Obf–backed model evaluation and selection (software, AI/devtools)
- Use ClassEval-Obf and the paper’s obfuscation harness to add a “Name-Robustness Score” (Δ pre/post obfuscation) in CI/CD for candidate models and model updates.
- Workflow: nightly or pre-release eval job runs benchmarks on original vs obfuscated code and gates promotion if Δ exceeds a threshold.
- Dependencies: semantics-preserving renamers for target languages; unit tests or IO oracles to verify invariance; compute budget for dual runs.
- IDE extension for “Identifier Randomizer” and “Prompt Hardening” (software, security/privacy)
- One-click toggle to obfuscate identifiers before sending code to cloud LLMs, and to locally test whether the assistant’s suggestions/summaries degrade under obfuscation.
- Tools: VS Code/IntelliJ plugins that implement alpha-renaming and “misleading/cross-domain” variants.
- Dependencies: capture-avoiding renaming (no collisions), reversible mapping for developer readability, safeguards for reflection/metaprogramming.
- Procurement rubric for LLMs with pre/post-obfuscation reporting (software procurement, enterprise IT)
- Require vendors to report: (i) Δ on execution tasks, (ii) Δ on summarization tasks, (iii) memorization stress-test results with input augmentation.
- Outputs: standardized “robustness appendix” in RFP responses; internal scorecards.
- Assumptions: vendor cooperation; reproducible harness; agreed thresholds per task.
- Training data curation to reduce IP leakage and shortcut learning (software, privacy/compliance)
- Preprocess internal corpora with semantics-preserving obfuscation to de-emphasize name cues and lower leakage risk when fine-tuning in-house models.
- Workflow: data pipeline stage “name scrubber” before training; spot-check with execution tests.
- Dependencies: acceptance of potential accuracy trade-offs on intent-heavy tasks; legal review for data transformations.
- Execution-prediction QA with input augmentation and obfuscation (CI/testing)
- Add a test suite that (a) generates new inputs for existing tasks and (b) runs original vs obfuscated code to detect memorization and brittle reasoning.
- Metrics: “semantic fidelity” (success under novel inputs) and “memorization hits” (old-output reproduction rate).
- Dependencies: correct oracles for augmented inputs; filtering of small-output-domain items to reduce chance matches.
- Code review bot for “name-sensitivity” and “line-by-line degeneration” (software quality, DevEx)
- Bot flags summaries that regress to narration under obfuscation, signaling weak intent inference; suggests structure-aware prompts or tests.
- Tools: LLM-as-a-judge rubric from the paper; side-by-side summary comparison.
- Dependencies: consistent eval prompts; guardrails to avoid false positives.
Academia and Research
- Benchmark adoption and reporting protocol (SE, ML/NLP)
- Adopt ClassEval-Obf as a default companion to execution and summarization benchmarks; publish pre/post-obfuscation deltas and uncertainty intervals.
- Use the obfuscation suite to study identifier leakage across tasks and languages.
- Dependencies: dataset licensing; multi-language obfuscators.
- Course labs on “two-channel code understanding” (education)
- Lab assignments where students test LLMs on original vs obfuscated code, measure Δ, and analyze failure modes.
- Dependencies: classroom GPU credits or API access; curated tasks with gold IO.
Policy, Compliance, and Security
- Safe-sharing workflow for external LLM use (privacy/IP in finance, healthcare, enterprise)
- Enforce pre-send obfuscation of identifiers in client/server code sent to SaaS LLMs; retain a reversible mapping locally.
- Artifacts: policy addendum, pre-commit hook or proxy that rewrites code in transit.
- Dependencies: reflection/dynamic code exemptions; developer training.
- Model card updates with “identifier robustness” and “memorization checks” (governance)
- Add sections reporting Δ under multiple obfuscations and counts of old-output reproductions on augmented inputs.
- Dependencies: standardized eval harness; reviewer guidance.
Daily Practice
- Developer tactics for safer prompts and better expectations (individual devs, teams)
- Use “private-mode prompts” (obfuscation) when sharing snippets externally; expect summarizers to falter when names are removed; lean on tests and structure in prompts.
- Interview prep and code katas with obfuscated snippets to build structure-first reasoning.
- Dependencies: simple local renamer; time to run tests.
Long-Term Applications
These directions require further research, scaling, integration, or standardization to realize robust, name-agnostic code understanding in production systems and policy frameworks.
Industry and Products
- Structure-first code LLMs trained with obfuscation and program graphs (software, AI/devtools)
- Training that mixes AST/data-flow supervision, execution signals, and systematic obfuscation augmentation to reduce name dependence.
- Products: next-gen code assistants resilient to naming; improved execution prediction engines.
- Dependencies: large-scale static analysis pipelines; execution sandboxes; curated multi-language corpora.
- Execution-grounded assistants that fuse static analysis and lightweight execution (IDEs, enterprise)
- Agents that prefer semantics (symbolic execution, data-flow) over lexical cues for summarization, review, and test generation.
- Tools: hybrid neuro-symbolic inference; cost-aware interpreter integration.
- Dependencies: latency budgets; robust sandboxing; path explosion mitigation.
- Robustness certification and eval-as-a-service (evaluation vendors, standards)
- Third-party services issuing “identifier-robust” certification based on Δ thresholds, input augmentation, and anti-memorization tests.
- Sector fit: vendor selection for regulated industries (finance, healthcare, energy).
- Dependencies: consensus metrics; reproducibility standards; legal acceptance.
- Privacy-preserving code assistants with reversible abstraction layers (security/privacy)
- Enterprise gateways that abstract identifiers at ingress, keep a secure mapping, and de-abstract responses—minimizing exposure while maintaining usability.
- Dependencies: deterministic mapping, collision resistance, compatibility with reflection/metaprogramming, SOC2/ISO controls.
- Inference-time “anti-memorization adapters” (AI safety)
- Middleware that masks or normalizes identifiers at inference, calibrates uncertainty when reliance on names is detected, and triggers fallback to structural tools.
- Dependencies: reliable name detectors; confidence estimation; minimal latency overhead.
Academia and Research
- Cross-language, repo-scale obfuscation benchmarks (SE/NLP)
- Extend ClassEval-Obf to Java, C/C++, JS, Rust, Go; cover repositories with reflection, metaprogramming, macros, and dynamic dispatch.
- Dependencies: capture-avoiding obfuscators per language; semantics invariance checks.
- Training objectives penalizing name overreliance (ML)
- Contrastive objectives across name variants; masked-identifier prediction with structural targets; RL from execution feedback under obfuscation.
- Dependencies: scalable training infra; high-quality execution oracles.
- Large user studies on developer trust and failure modes (HCI/SE)
- Measure how Δ under obfuscation correlates with user trust, bug introduction, and review efficacy.
- Dependencies: IRB approvals; instrumentation in IDEs.
Policy, Standards, and Regulation
- ISO/IEEE-style standards for code LLM evaluation under obfuscation (standards bodies)
- Define test suites, Δ thresholds, memorization stress tests, and reporting templates for procurement and audits.
- Dependencies: multi-stakeholder working groups; pilot programs.
- Regulatory guidance on code-data usage and memorization risk (public policy)
- Require risk disclosures and mitigations for identifier leakage and training-data reappearance in outputs; mandate eval artifacts for high-risk deployments.
- Dependencies: impact assessments; regulator capacity; sector-specific tailoring.
Daily Life and Education
- “Two-channel literacy” in curricula and certifications (education, workforce)
- Teach that LLMs map names to intent and structure to behavior; train students to design prompts/tests that emphasize semantics.
- Tools: interactive playgrounds to toggle obfuscation and visualize performance shifts.
- Dependencies: open educational resources; faculty adoption.
- Community practices for open-source maintainers (open-source)
- Contribution guidelines encouraging tests and structural cues; CI checks that ensure tools/assistants remain effective after obfuscation.
- Dependencies: maintainer buy-in; CI time budgets.
Notes on assumptions and feasibility across applications:
- Obfuscation must be capture-avoiding and semantics-preserving; dynamic features (reflection, eval, metaprogramming) complicate renaming.
- Reliable oracles (tests, IO specs) are needed to verify invariance and to run augmented-input checks.
- Some applications trade off readability/usability against privacy and robustness; reversible mappings and IDE support mitigate this.
- Standardization and procurement changes require multi-party agreement and time; interim internal policies can bridge the gap.
Collections
Sign up for free to add this paper to one or more collections.