- The paper introduces a novel, MLP-based channel-wise transformation that aligns teacher and student features for more effective knowledge distillation.
- It integrates the transformation with an L2 loss, achieving over 3% Top-1 accuracy improvements in image classification and notable gains in object detection and segmentation.
- The approach simplifies the distillation process by reducing reliance on complex spatial transformations while requiring minimal hyper-parameter tuning.
Introduction
Knowledge distillation is a methodology that transfers knowledge from a larger model (teacher) to a smaller one (student). The conventional approach focuses on aligning feature maps spatially, which can produce overly strict constraints on the student. This paper introduces channel-wise transformations to align features along the channel dimension, thereby addressing misalignments effectively and proposing a more flexible distillation framework.
Methodology
The framework leverages a learnable nonlinear channel-wise transformation to align the features between teacher and student. This transformation utilizes an MLP with one hidden layer, facilitated by 1×1 convolutions to adjust channel-wise discrepancies. The transformation uses the following function:
MLP(F)=W2(σ(W1(F)))
where W1 and W2 are the parameters defined as 1×1 convolution layers, and σ denotes the ReLU activation function. The transformation only applies to the student features, enabling the adaptation and retention of significant knowledge.
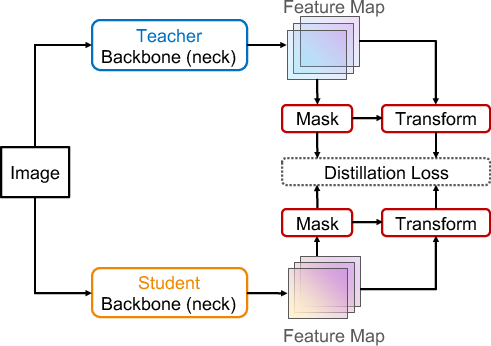
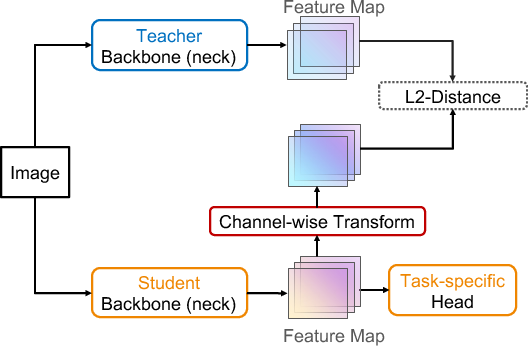
Figure 1: Non-Local Block used in FKD~\cite{zhang2020fkd} compared with our channel-wise transformation.
Integration into Distillation Framework
The proposed method consists of integrating this transformation into a generic feature distillation framework. The framework uses a simple L2 distance to calculate the loss for transformed student features against teacher features:
Lfeat=i∑N(MLP(Fs)−Ft)2
The overall loss combines task-specific losses with the distillation loss, adjusted by a hyper-parameter α, facilitating easy adaptation across various tasks:
Ltotal=Ltask+αLfeat
Experiments and Results
Image Classification
The method achieves notable improvements in image classification tasks, as evidenced by increases in Top-1 accuracy for models like ResNet34 distilled into ResNet18. Significant gains of over 3% Top-1 accuracy were observed, outperforming prior logits-based and feature-based distillation methods.
Object Detection and Instance Segmentation
In object detection, the method demonstrates average improvements of +3.5% in mAP across various detectors, including two-stage and single-stage architectures. Specifically, for instance segmentation, the bounding box AP saw a rise of +3.2% using the proposed framework.
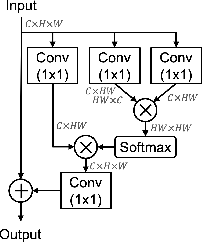
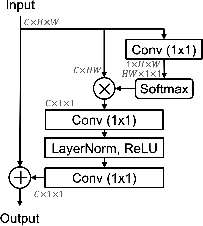
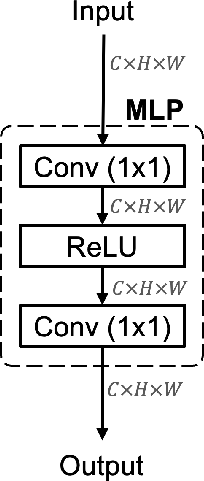
Figure 2: Our proposed method uses a learnable channel-wise transformation only for the student model, avoiding complex spatial transformations.
Semantic Segmentation
Extensive testing on the CityScapes dataset shows improvements in mIoU by +4% on the homogeneous setting and significant gains with heterogeneous sets. These results underscore the flexibility and broad applicability of the channel-wise transformation in various dense prediction tasks.
Ablation Studies
Through empirical analysis, the study highlights the significance of channel-wise transformations. Specifically, replacing sophisticated spatial transformations with a simple MLP produces better results with lower L2 distances in training while maintaining higher task-specific outputs.
Conclusion
This study underscores the feasibility of channel-wise feature alignment as an effective strategy in knowledge distillation frameworks. The proposed MLP-based transformation simplifies the distillation process and requires minimal hyper-parameter tuning, making it adaptable for various computer vision tasks. Future work may explore further optimization in balancing distillation and task-specific losses, as well as extending the framework's application to other modalities beyond vision.