- The paper introduces a novel function-based loss that goes beyond L2 appearance metrics to align teacher and student feature roles for improved distillation.
- It integrates both appearance and function perspectives using specialized loss components and strategic path sampling to optimize model performance.
- Experimental results across CIFAR-100, ImageNet, and MS-COCO demonstrate consistent performance gains over existing knowledge distillation techniques.
Function-Consistent Feature Distillation
In this essay, I present a detailed overview and analysis of the paper titled "Function-Consistent Feature Distillation" (2304.11832). This work introduces a novel approach to feature distillation in neural networks, focusing on optimizing the functional similarity between teacher and student features instead of relying solely on appearance-based metrics like L2 distance.
Introduction
The deployment of deep neural networks (DNNs) on edge devices is often constrained by their large storage and computational requirements. Knowledge Distillation (KD) is a popular technique to transfer the knowledge from a large, well-trained teacher model to a smaller student model, with the aim of enhancing the student's performance. Traditional feature-distillation methods primarily use L2 distance to measure similarity between teacher and student features. However, this isotropic approach fails to recognize that neural operations often have anisotropic effects across different dimensions of the feature space.
Motivation
The paper argues for a paradigm shift from appearance-based metrics to a function-based framework for measuring feature similarity. The proposed Function-Consistent Feature Distillation (FCFD) aims to ensure that teacher and student features not only appear similar but also serve similar roles in subsequent network layers, thereby producing similar outputs. The authors provide compelling theoretical and empirical evidence that function-based feature similarity provides a more meaningful and task-relevant basis for distillation.
Methodology
Function-Consistent Feature Distillation (FCFD)
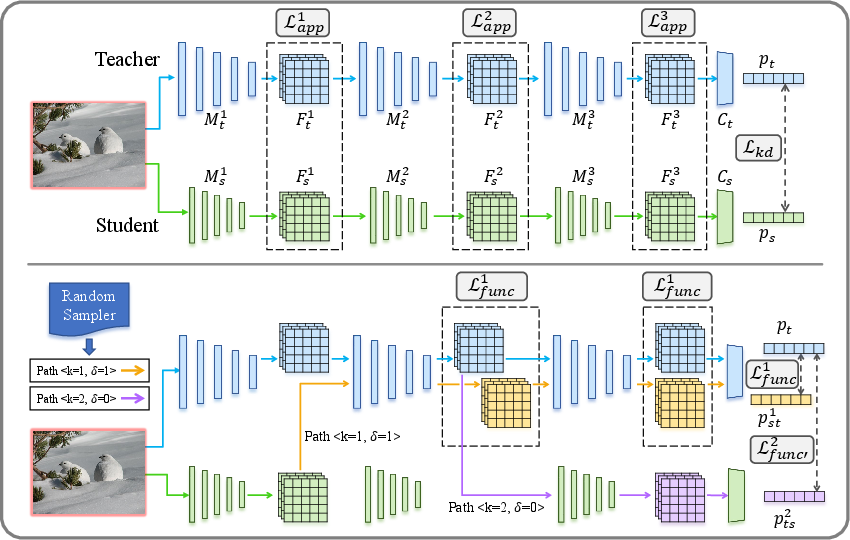
Figure 1: An overview of FCFD. Top: illustration of the traditional KD loss (Lkd) and appearance-based feature matching loss (Lapp). Bottom: illustration of our proposed function matching losses Lfunc and Lfunc′.
FCFD introduces a novel loss function designed to optimize functional consistency:
- Appearance Perspective (Lapp): Maintains the traditional L2 distance to ensure numerical similarity.
- Function Perspective:
- Lfunc: Utilizes the teacher's later layers to measure functional similarity.
- Lfunc′: Employs the student's later layers to achieve functional alignment from the student's viewpoint.
The complete FCFD loss is a weighted sum of these components, achieved through strategic path sampling during training to manage computational costs effectively.
Experiments
The authors conduct comprehensive experiments across image classification (CIFAR-100, ImageNet) and object detection (MS-COCO) tasks, demonstrating the superiority of FCFD over existing approaches. The results consistently show that FCFD outperforms state-of-the-art KD methods, particularly when teacher and student models have different architectures.
Performance Highlights:
- CIFAR-100: FCFD improves student performance by an average of 6.78% over non-distilled baselines for teacher-student pairs with different architectures.
- ImageNet: Achieves significant gains, with a notable 0.7% improvement in top-1 accuracy over the best competing method for the ResNet50-MobileNet pair.
- MS-COCO: Outperforms existing KD techniques, with average improvements exceeding 4% in mean Average Precision (mAP).
Ablation Studies
The paper provides detailed ablation studies validating the synergistic integration of appearance and function perspectives in FCFD. Notably, both Lfunc and Lfunc′ independently contribute to performance gains, highlighting their complementary roles.
Conclusions and Implications
The FCFD approach underscores the importance of function-consistent feature matching in knowledge distillation. By aligning the functional roles of features in addition to their appearance, FCFD offers a more robust framework for enhancing model compression techniques. The paper's findings suggest potential for broader applications across different network architectures and tasks, warranting further exploration into function-based metrics in other areas of deep learning.
In summary, this work provides a significant contribution to the domain of model compression and KD, offering a methodological advance that effectively addresses the limitations of traditional feature-distillation methods. Future research might explore integrating FCFD with orthogonal techniques or investigating its applicability to other complex tasks beyond classification and detection.