- The paper introduces a novel compression framework that reduces computational demands by over 28 times while preserving visual fidelity.
- It employs architectural simplification, knowledge distillation, and mixed-precision quantization to boost inference speed up to 19 times on edge devices.
- The approach significantly enhances the deployment viability of speech-driven talking-face generators for digital humans and lip-sync applications.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Introduction
The paper "A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation" (2304.00471) addresses the computational challenges associated with modern talking-face generation models. These models, despite their impressive results, pose considerable computational burdens, which hinder their efficient deployment on resource-limited devices. The paper introduces a lightweight compression framework focusing on a popular talking-face generator, Wav2Lip, to ameliorate these burdens without compromising performance.
Talking-face generation has become vital for applications such as digital human creation and video lip synchronization. However, current state-of-the-art models, founded on generative adversarial networks (GANs), demand significantly more computations than traditional classification networks (Figure 1).
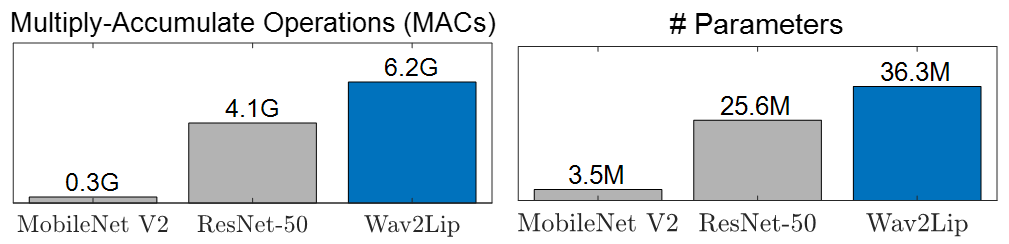
Figure 1: Computational comparison between classification and talking-face generation networks.
This paper builds upon the GAN architecture by leveraging techniques such as knowledge distillation (KD), neural architecture search, and quantization to compress the models efficiently. Unlike previous efforts focused on compressing classical image-to-image translation models, this study uniquely addresses the specific challenges of talking-face generators.
Proposed Compression Framework
The framework compresses the Wav2Lip generator through three main steps: architectural simplification, comprehensive training with KD, and mixed-precision quantization.
Compact Generator Architecture
The first step involves architectural simplification by reducing the number of channels and removing residual blocks in the Wav2Lip generator. The compressed architecture maintains the requisite synthesis capabilities without the redundant residual blocks. This reduction results in a substantially lighter model that efficiently processes input while retaining high visual fidelity (Figure 2).
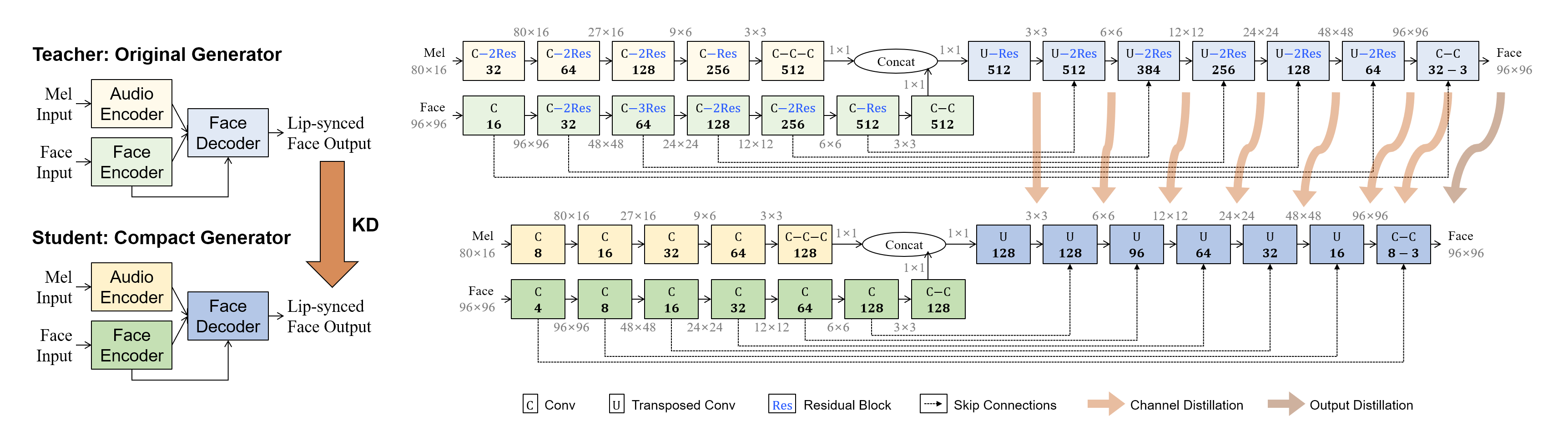
Figure 2: Generator architectures and KD process. Each layer is denoted by the type of convolution and the number of output channels. The compact generator with ×0.25 number of channels and removed residual blocks is trained under the guidance of the original generator.
Knowledge Distillation (KD)
A core challenge in GAN compression is balancing generator and discriminator capacities. The proposed KD technique circumvents the need for adversarial learning by using structured distillation losses that encourage the student model to mimic the teacher model's intermediate features and outputs (Equations \ref{loss_teacher} and \ref{loss_student}). Offline KD, with a frozen teacher model, proved more effective than online KD for talking-face synthesis tasks.
Mixed-Precision Quantization
To address quality degradation observed in full INT8 precision conversion, the paper implements a mixed-precision quantization strategy. This method utilizes FP16 compute units for quantization-sensitive layers, preserving the model's visual output quality while accelerating inference speeds significantly (Figure 3).
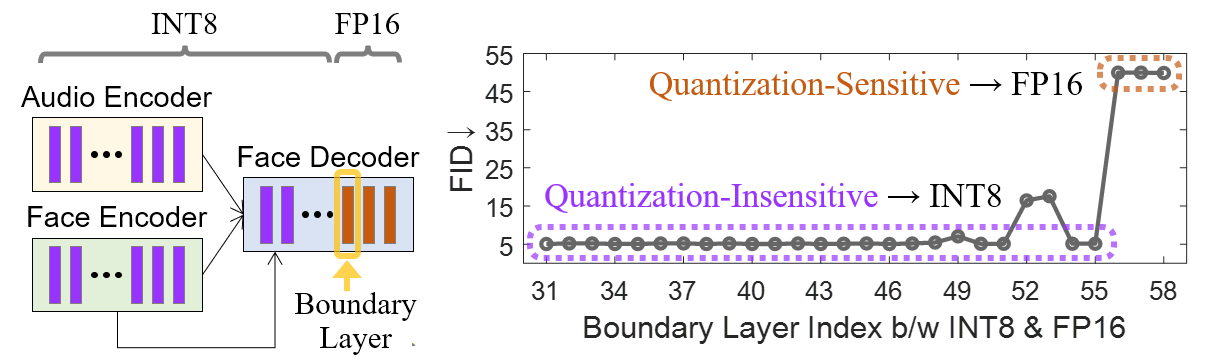
Figure 3: Layer-wise quantization sensitivity analysis for mixed-precision quantization.
Experimental Results
The experiments performed on the LRS3 dataset demonstrate the framework's efficacy in reducing computational demands by more than 28 times, while maintaining generation quality comparable to the original model (Table \ref{table:score}). KD effectively resolves trade-offs between visual fidelity and lip-sync quality, enhancing stability during training.
Qualitative results further confirm the framework's success, as the compressed model accurately implements lip-syncing capabilities comparable to the original generator (Figure 4).

Figure 4: Qualitative results. As per the specified speech, the reference faces' mouth shapes should transform into (a) closed-lip and (b) open-lip shapes. The student models \circled{1}, \circled{2}, and \circled{3} correspond to those in Table \ref{table:score}. The outputs of our final model (Student \circled{3}) closely resemble those of the original generator (Teacher).
Inference Speed
The framework's real-world applicability is further bolstered by the remarkable inference speed improvements on NVIDIA Jetson edge GPUs. Mixed-precision quantization enables up to 19 times faster inference, making the model suitable for deployment on edge devices (Figure 5).

Figure 5: Latency (measured in milliseconds) at different precisions on NVIDIA Jetson edge GPUs. At FP16 precision, our approach boosts the inference speed by 8ᷗsim17ᷗ. At the mixed precision (denoted by ``MIX"), we achieve a 19ᷗ speedup on Xavier NX.
Conclusion
The paper presents a potent unified framework for compressing talking-face generation models, specifically Wav2Lip, without sacrificing quality. By combining architectural simplification, KD, and mixed-precision quantization, the framework achieves significant reductions in computational demands and enhances inference speeds. This work paves the way for future research into automatically optimizing quantization across layer-specific needs for enhanced performance on edge devices.
Future studies can explore automated precision determination strategies for further optimization. The presented framework offers valuable insights and practical solutions for deploying efficient talking-face generators across diverse platforms.