- The paper formalizes permutation equivariance by proving that token and feature shuffling preserves outputs and gradients through specific weight and activation transformations.
- It rigorously validates theoretical claims with empirical results on vision and text Transformers, showing consistent training dynamics and inference performance.
- The study leverages these properties for privacy-preserving split learning and model authorization, offering secure defenses with negligible computational overhead.
Permutation invariance and equivariance have been conventionally restricted to inter-token shuffling and typically only characterized for forward propagation. This work systematically redefines permutation equivariance as an intrinsic property of Transformer-based architectures, broadening the notion to encompass both inter- and intra-token permutations and, critically, extends the guarantees to both forward and backward passes. Formally, the authors show that row (token) permutations and column (intra-token feature) permutations can be handled by appropriate transformations of weights and activations, such that the output predictions and backpropagated gradients are preserved under the transformation, up to invertible linear transforms. This establishes a form of parameterized symmetry in the learning dynamics and inference of Transformers.
The backbone permutation mechanism is summarized and visualized below.

Figure 1: The Transformer backbone, where yellow highlights indicate permutable learnable weights.
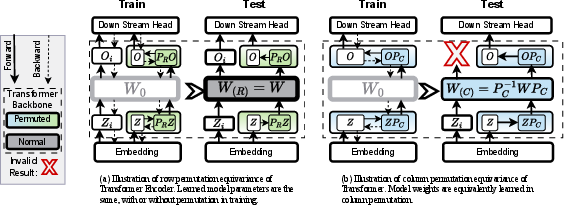
Figure 2: Schematic of the permutation properties, demarcating key loci for equivariant operations in the Transformer stack.
This reveals that, with proper alignment of weight permutations, models exhibit strict equivariance with respect to arbitrary shuffling of tokens or their features in both phases of learning, contingent on the permutation and its inverse being correctly applied at corresponding interfaces.
Theoretical Claims and Proofs
A sequence of theorems systematically prove:
- Row/Token Permutation Forward Equivariance: For any permutation matrix R of shape n×n (where n is the token count), for an input X, Enc(RX)=REnc(X). If the embedding output is permuted, and the downstream head input is unshuffled, the model’s mapping is unchanged.
- Row/Token Permutation Backward Invariance: The gradients after backpropagation are identically distributed for both the permuted and unpermuted cases, so the learned weights are identical.
- Column/Feature Permutation Forward Equivariance: For any feature-permutation matrix C, column permutation requires that weight matrices themselves be correspondingly permuted in each block. Given the correct mapping (WC=C−1WC at each layer), we have TC(XC)=T(X)C.
- Column/Feature Permutation Backward Equivariance: The gradients and weight updates correspond by conjugation, dL/dWC=C−1(dL/dW)C, ensuring that the parameter evolution tracks exactly under the permutation.
A constructive approach also shows this property is inherited by any network composed (sequentially or in parallel) of permutation-equivariant primitive operators (e.g., softmax, attention, elementwise, linear, normalization, and MLP layers), with the caveat that convolution-like or sliding window operators break the symmetry (see supplement for such exceptions).
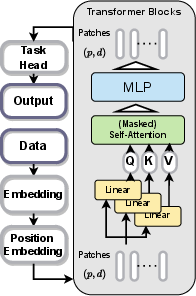
Figure 3: An encoder block in a Transformer, illustrating the locus of permutation at both attention and MLP submodules.
Experimental Validation Across Domains
The theory is validated on canonical Transformer backbones (ViT, Bert, GPT2) for both vision and text domains. All results substantiate the analytical claims:
- Inference Invariance: Model outputs (classification accuracy, mIoU, perplexity) are preserved up to floating point errors when row or column permutations are correctly handled (Table results in paper).
- Training Dynamics: Learning curves, final accuracy, and loss trajectories match exactly with and without permutations.
- Interruption of Permutation Alignment: Feeding misaligned permutations (e.g., permuted weights with unpermuted activations and vice versa) degrades performance to random guess.
These properties are empirically illustrated for vision transformers, NLP transformers, and semantic segmentation.
Application: Privacy-Preserving Split Learning
Leveraging permutation equivariance, the authors design privacy-enhancing split learning protocols. The client applies a random row permutation to the feature embeddings before offloading them to the cloud. The cloud, without knowledge of the permutation, cannot reconstruct the input data from the intermediate representation (with reconstruction attacks on permuted features yielding very low similarity to the original images), yet the utility for downstream tasks is robustly preserved. Enhanced variants of defense mechanisms (Gaussian Noise + permutation, Frequency Filtering + permutation) further improve the privacy-utility trade-off.





Figure 4: Test-time model inversion attack—data reconstructed from unprotected features.
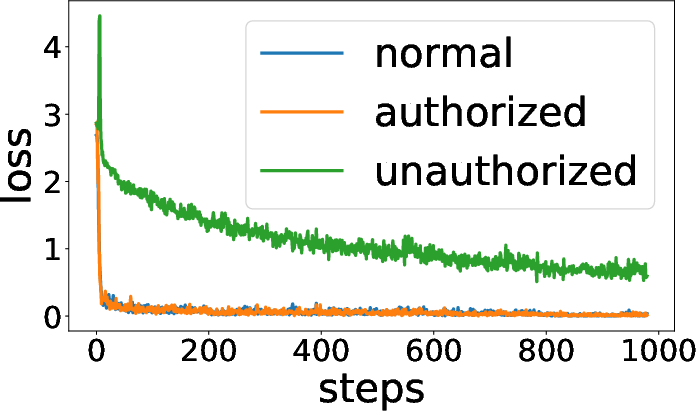
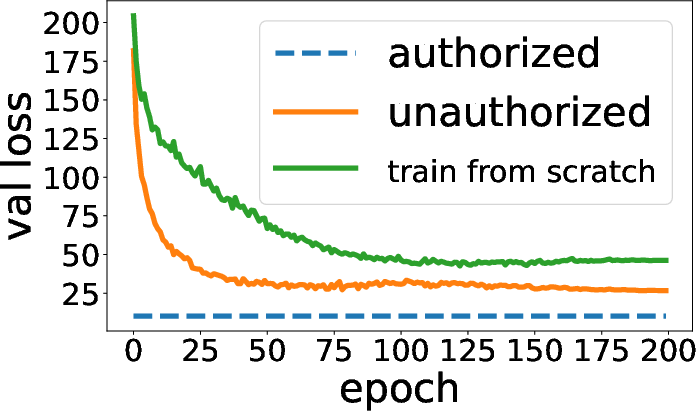
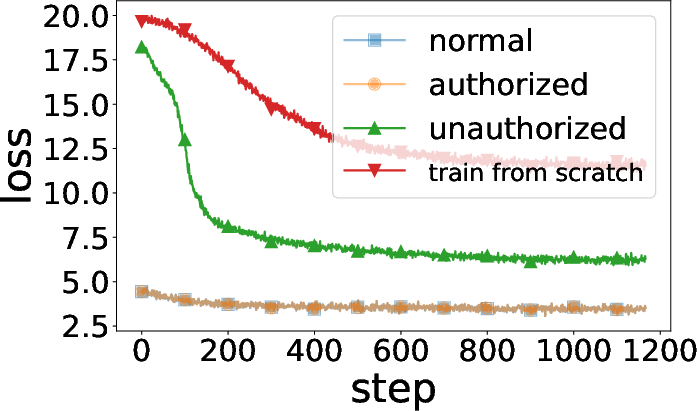
Figure 5: Training curves show authorized usage yields high utility, while unauthorized (no key) usage leads to failure and high loss.
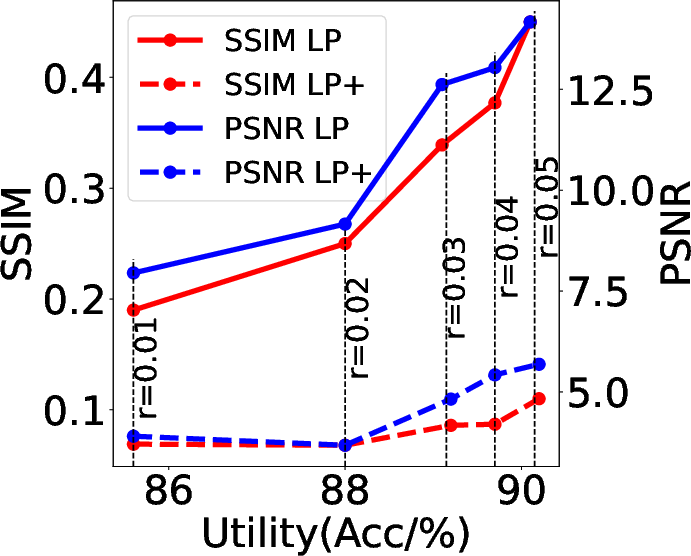
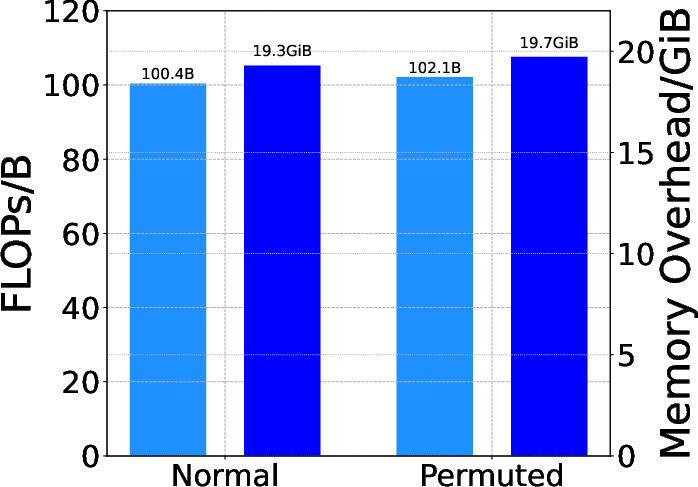
Figure 6: Utility-privacy trade-off curve when varying LP radius; applying a permutation consistently yields better privacy at constant utility.
Application: Model Authorization and “Encryption”
Column permutation can act as a lightweight “authorization key” or obfuscation mechanism. If model weights are “encrypted” by a secret column permutation, only parties with the matching permutation key can use the model (for inference or fine-tuning). Unauthorized users, lacking the permutation, cannot leverage the model effectively—accuracy collapses to chance, and fine-tuning is nearly as hard as training from scratch.
This is robustly shown for both vision and language Transformer models. Training and validation curves confirm that only authorized (key-holding) users achieve expected generalization.
Overheads and Practicality
The computational and memory overhead of the approach is negligible: four extra matrix multiplications per batch (for permutations and their inverses), not scaling with model or dataset size. Efficiency benchmarks confirm that the cost is essentially equivalent to vanilla training and inference.
Implications and Further Directions
Theoretical Implications:
These results formalize permutation equivariance as not just a forward-pass property but a full learning-dynamics symmetry. This reframes how invariance and equivariance can structure many aspects of Transformer-based representation learning—opening up new avenues for data augmentation, robust learning protocols, and secure model deployment without sacrificing utility.
Practical Implications:
Permutations give rise to generic, non-cryptographic privacy and model IP protection strategies. Split learning schemes and model offloading pipelines, especially in adversarial or semi-honest environments, gain actionable defenses against inversion attacks and unauthorized model use with essentially no algorithmic or computational penalty.
Future Work:
Directions include extending these results to other architectures (e.g., hybrid ConvNet/Transformer, graph Transformers), exploring combined permutations and more complex secret-sharing schemes, and further formalizing the interplay with weight/activation sharing in distributed or federated scenarios. Additionally, quantifying the cryptographic strength of permutation-based model "encryption" and integrating with homomorphic or semantically secure inference remains open.
Conclusion
This paper advances a rigorous, general theoretical account of permutation equivariance in Transformers—extending beyond mere token shuffling and forward passes to a bi-directional, compositional property. It validates the results across canonical models, demonstrates strong privacy and authorization mechanisms enabled by this structure, and does so without incurring practical overhead. These findings have significant consequences for both model interpretability and privacy/security in Transformer-based deep learning.
For the original paper and proofs, see "Permutation Equivariance of Transformers and Its Applications" (2304.07735).