EquiTabPFN: A Target-Permutation Equivariant Prior Fitted Networks
Abstract: Recent foundational models for tabular data, such as TabPFN, excel at adapting to new tasks via in-context learning, but remain constrained to a fixed, pre-defined number of target dimensions-often necessitating costly ensembling strategies. We trace this constraint to a deeper architectural shortcoming: these models lack target equivariance, so that permuting target dimension orderings alters their predictions. This deficiency gives rise to an irreducible "equivariance gap", an error term that introduces instability in predictions. We eliminate this gap by designing a fully target-equivariant architecture-ensuring permutation invariance via equivariant encoders, decoders, and a bi-attention mechanism. Empirical evaluation on standard classification benchmarks shows that, on datasets with more classes than those seen during pre-training, our model matches or surpasses existing methods while incurring lower computational overhead.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making machine learning models for tables (like spreadsheets) more fair and stable. It looks at a problem in popular tabular models called TabPFN: the model’s predictions can change just because you changed the order of the output labels (for example, swapping the position of “cat” and “dog” in a one-hot vector). The authors show why this is a problem and introduce a new model, EquiTabPFN, that fixes it so the order of the target labels never affects the prediction.
Key Questions and Goals
Here are the main things the paper tries to figure out:
- Why should the order of target labels not matter, and what goes wrong if it does?
- How much extra error do models get from ignoring this “order-doesn’t-matter” property?
- Can we design a model that naturally respects this property without doing lots of slow tricks?
- Does that new model work well on real datasets and unusual cases (like more classes than seen during training)?
Methods and Approach (in everyday language)
Think of a table of data where each row is a person and each column is a feature (like age, height, etc.). The target might be a class label, often stored as a one-hot vector (for example, a 3-class label might be [0, 1, 0]). In tabular data:
- The order of rows doesn’t matter (shuffling rows gives the same dataset).
- The order of columns often doesn’t matter.
- The order of target components shouldn’t matter either. If you swap the positions of classes in the one-hot vector, the meaning is the same once you relabel consistently.
TabPFN already respects the row order, and some recent work improves column order handling. But TabPFN does not handle target order properly: changing the class order can change predictions, which is not good.
The authors do two main things:
- Theory: They define the “equivariance gap,” which is the extra error caused by not respecting target order. They prove that:
- If the loss is nice (convex) and the data doesn’t prefer any particular label order, then the best possible model is one that’s equivariant (i.e., does not change predictions when you permute target labels).
- If a model is not equivariant, it wastes effort learning to ignore target order and still gets extra error.
In simple terms: if you build a model that doesn’t care about label order, you avoid unavoidable mistakes and make training more efficient.
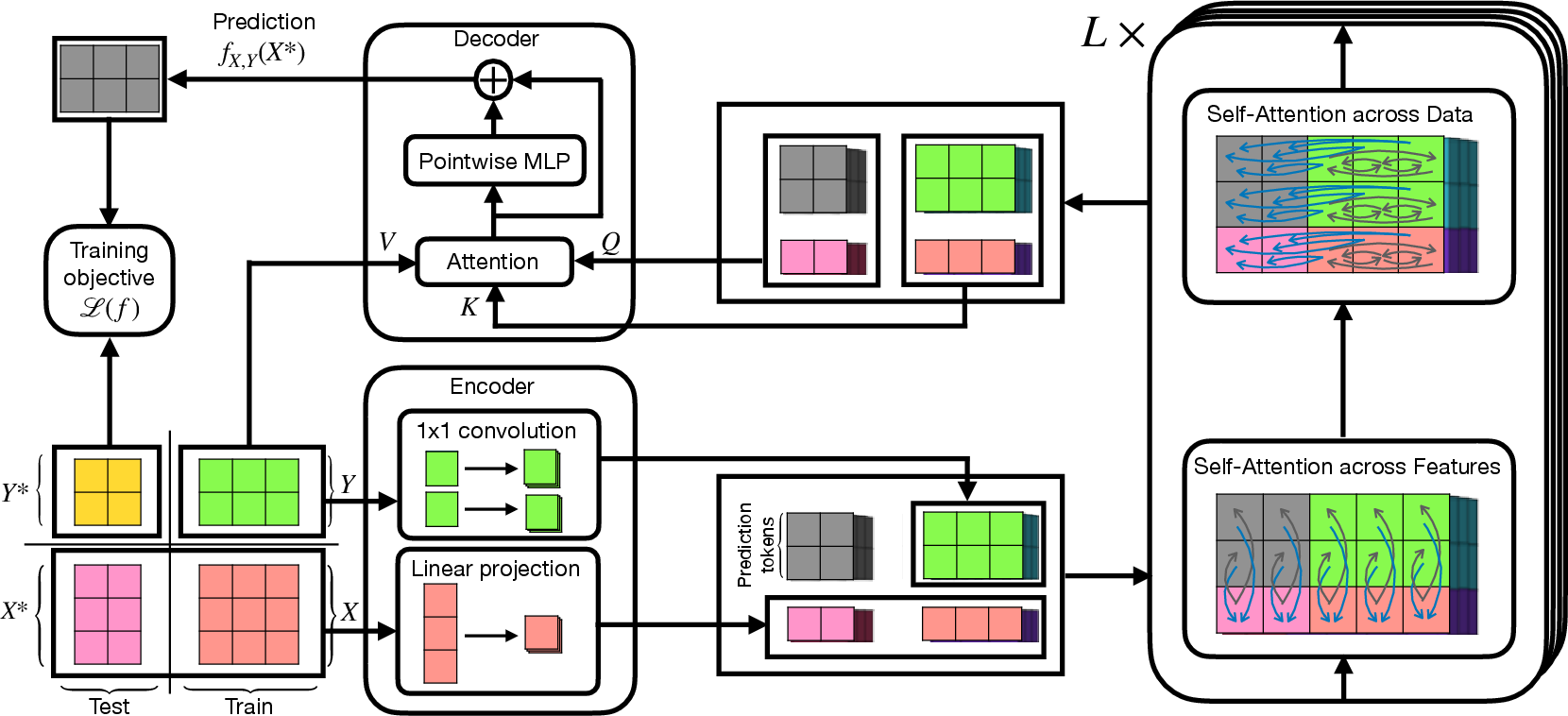
- Architecture (EquiTabPFN): They design a new transformer-based model that is automatically target-permutation equivariant. Key ideas:
- Encoder: Instead of gluing target data directly into a single token, they make a token for each target component (each class position), using something like a tiny “1×1 convolution” over the target entries. This keeps the model fair to any reordering of classes.
- Alternating attention: The transformer alternates between “looking across target components” within each data row and “looking across rows” in the dataset. Think of it like switching between “zooming in” on features of one example and “zooming out” to compare examples.
- Decoder: For prediction, they use attention that directly mixes the test example’s representation with the training examples’ targets. It’s like asking: “Which training rows look most like this test row?” and then averaging their labels. They add a small residual MLP to make the predictions more flexible, while still keeping the order-fair property.
Importantly, they avoid the old workaround of averaging over many random label permutations (which can be extremely slow because the number of permutations grows super fast). Their model is equivariant by design.
Main Findings and Why They Matter
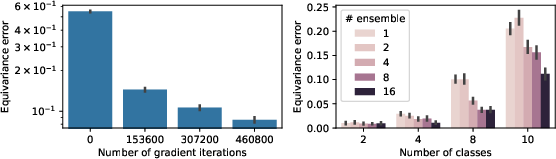
- Theoretical result: They show the “equivariance gap” adds extra error that you can’t remove unless your model respects target order. With normal losses and data, the truly best solution must be equivariant.
- Stability: In experiments, TabPFN changes its decision boundaries when you reorder classes. EquiTabPFN gives the same predictions no matter how you number the classes.
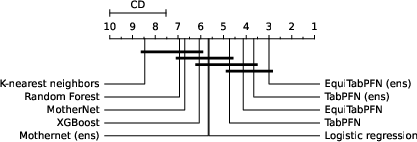
- Accuracy: On many real-world datasets, EquiTabPFN performs as well as or better than strong baselines like TabPFN, MotherNet, and XGBoost. It’s competitive without special tuning.
- Efficiency: TabPFN can be made more equivariant by averaging over many permutations, but that’s slow and gets worse as the number of classes grows. EquiTabPFN builds equivariance into the architecture, so you don’t need expensive ensembling to fix the issue.
- Generalization: EquiTabPFN can handle datasets with more classes than it saw during training because it doesn’t rely on a fixed output size. This is useful in real-life cases where the number of classes can vary a lot.
Implications and Impact
- More trustworthy predictions: Since EquiTabPFN doesn’t change its results when you just reorder labels, it’s more robust and easier to trust. This matters for fairness, reproducibility, and reliability in practical applications.
- Less tuning and fewer hacks: You don’t need to run many permutations or ensembles to fix label-order issues. That saves time and computing resources.
- Better foundations for theory: The paper connects these tabular models to “kernel machines” (a classic, well-understood type of model) through its non-parametric decoder idea. This could help researchers analyze and improve tabular foundation models more systematically.
- Practical readiness: Because EquiTabPFN can handle different numbers of classes at test time, it’s flexible for real-world scenarios where problems vary from one dataset to another.
In short, EquiTabPFN is a smarter, fairer version of tabular foundation models that respects the idea that the order of labels shouldn’t change the prediction, and it does so while staying fast and competitive.
Collections
Sign up for free to add this paper to one or more collections.