- The paper introduces a scalable architecture using a two-stage attention mechanism that decouples representation and interaction complexities on large tabular datasets.
- It presents efficient hierarchical embedding and synthetic pretraining strategies that outperform state-of-the-art baselines with up to 10× faster training and inference.
- The work offers practical plug-and-play deployment by eliminating hyperparameter tuning, making it especially suitable for large-scale, real-world tabular classification tasks.
TabICL: Scaling In-Context Learning for Large-Scale Tabular Data
Motivation and Positioning
The paper "TabICL: A Tabular Foundation Model for In-Context Learning on Large Data" (2502.05564) addresses a central challenge that has limited the application of foundation models and in-context learning (ICL) to tabular data. While approaches like TabPFNv2 offer strong performance on small-to-medium dataset sizes, handling large tables on affordable resources has remained challenging due to the quadratic complexity of attention mechanisms over rows and columns. TabICL introduces an architecture and training methodology capable of scaling tabular ICL to datasets with hundreds of thousands of samples and hundreds of features, while retaining or surpassing the predictive performance and reliability of prior art.
Architectural Innovations
TabICL's architecture is motivated by the need to decouple the representation and interaction complexities inherent in tabular data, while maintaining the computational tractability necessary for large datasets.
- Two-Stage Attention Mechanism: TabICL first performs a distribution-aware, column-wise feature embedding using a shared Set Transformer to encode the statistical properties of each column. This is followed by a row-wise Transformer that models inter-feature dependencies within each sample, using learnable [CLS] tokens for aggregation. The final compact embeddings are then processed by a third Transformer for ICL, where training examples serve as context for test time prediction.
- Set-Based Feature Embedding: By treating each feature (column) as a set and employing induced self-attention blocks, TabICL achieves permutation invariance to row order within columns, reducing distribution shift and improving transferability.
- Efficient Hierarchical Aggregation: The aggregation of column-level representations via row-wise attention enables modeling both feature specific and cross-feature dependencies, and supports variable numbers of features and samples without architectural change.
- Rotary Positional Encoding (RoPE): RoPE is introduced within the row-wise Transformer to alleviate representation collapse, particularly when multiple features share similar marginal distributions. While this breaks strict permutation invariance, this is compensated at inference time by ensembling over permutations.
Pretraining Regime and Generalization
TabICL is exclusively pretrained on synthetic data generated from a mixture of structural causal models (SCMs) and tree-based predictors (notably XGBoost). This yields diverse feature interactions and marginal distributions, incorporating both smooth nonlinearities and abrupt, hierarchical dependencies (Figure 1, Figure 2, Figure 3).
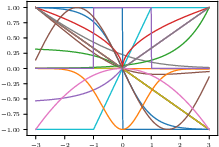
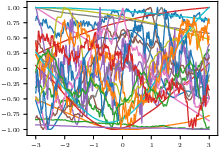
Figure 4: Examples of non-random and randomly instantiated activation functions from the SCM prior, supporting highly diverse functional compositions during synthetic data generation.
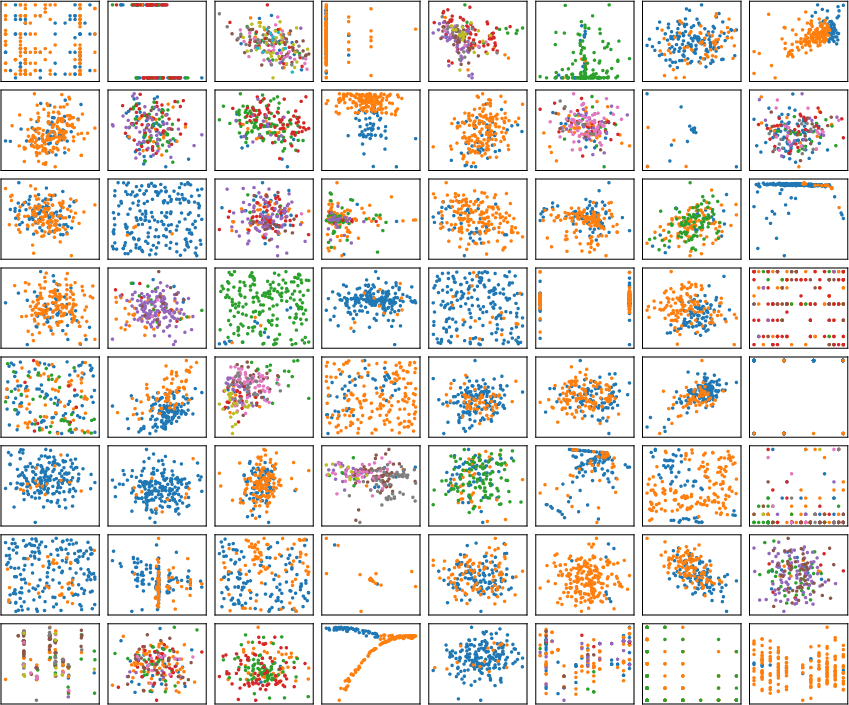
Figure 5: Randomly generated 2D datasets from the SCM prior, illustrating complex non-linear and multimodal label boundaries.
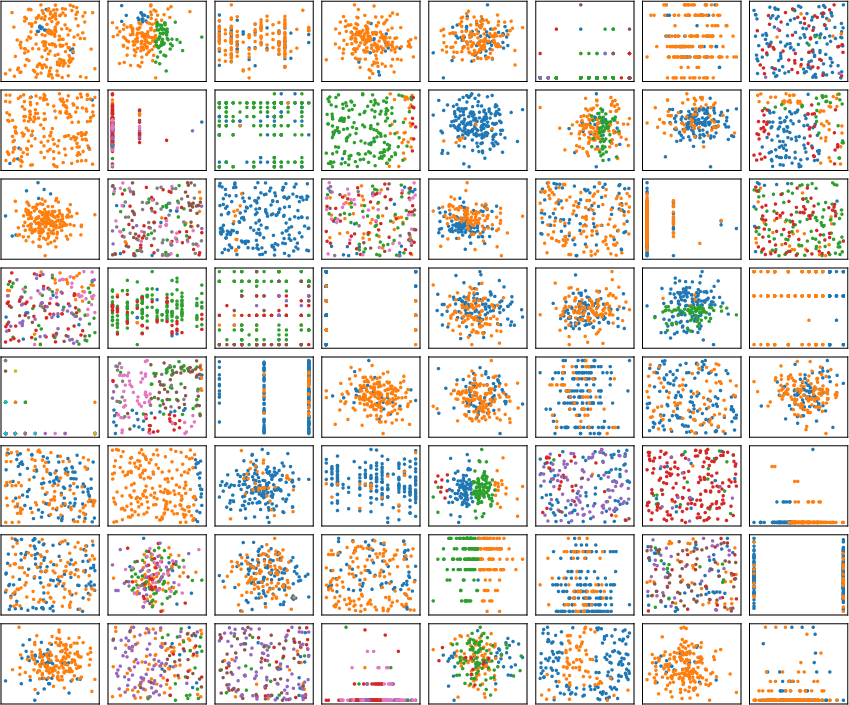
Figure 6: 2D datasets synthesized using the tree-based SCM prior, which injects inductive bias characteristic of tree models.
The curriculum learning approach gradually increases table sizes in pretraining, and for test-time cases exceeding pretrained class-counts, a hierarchical classification scheme is introduced for problems with more than 10 classes.
TabICL is benchmarked on 200 datasets from the TALENT benchmark, with sizes up to 150K samples and up to 500 features. The results presented are compelling across several axes:
- Predictive Performance: TabICL matches or outperforms all baselines, including the state-of-the-art TabPFNv2 and strong GBDT implementations (e.g., CatBoost) on both small-medium and large dataset regimes.
- Efficiency: TabICL achieves systematic speedup, with training+inference times up to 10× faster than TabPFNv2 for large datasets, and order-of-magnitude advantage over tree-based or MLP ensembles that require hyperparameter search.
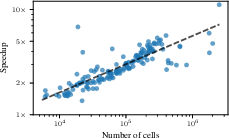
Figure 8: Speedup of TabICL relative to TabPFNv2 as dataset size increases, demonstrating increasing efficiency gains for large tables.
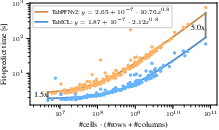
Figure 10: Training+inference time comparison between TabICL and TabPFNv2, clearly showing TabICL's sub-linear scaling with respect to data size.
- Robustness Across Data Characteristics: TabICL maintains strong performance across benchmarks varying in the number of classes (Figure 11), the number of features (Figure 12), and the categorical-to-total feature ratio (Figure 13), demonstrating its generalization capacity.
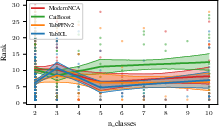
Figure 7: Dependency of benchmark rank on the number of classes; TabICL remains top-ranked across class counts.
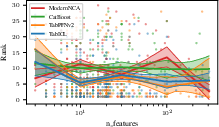
Figure 14: Rank dependence on the number of features; TabICL displays stable ranking even as dimensionality increases.
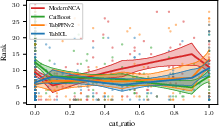
Figure 15: Rank dependence on proportion of categorical features; TabICL exhibits better robustness compared to TabPFNv2 as categorical feature dominance rises.
Theoretical and Practical Implications
Theoretical
- ICL as Bayesian Inference: The Bayesian interpretation of ICL is reinforced, where TabICL's pretrained Transformers act as implicit estimators of predictive posteriors given arbitrary context sets and test queries. The column-then-row embedding architecture can be viewed as approximating a sufficient statistic-like reduction for task adaptation.
- Architectural Inductive Bias: The structural decoupling and permutation invariance embedded in TabICL's design are critical for dataset-agnostic transferability. The use of set-based and hierarchical attention mechanisms provides strong evidence that tailored inductive biases are essential for successfully scaling tabular foundation models.
- Synthetic Pretraining: Demonstrating that pure synthetic data, when appropriately diverse and constructed, is sufficient to provide generalizable inductive priors for broad real-world tabular tasks.
Practical
- Resource Efficiency: The memory and runtime optimizations (via FlashAttention, checkpointing, offloading, and regression-guided batching) make training and inference feasible on commodity hardware for datasets previously only tractable for polynomially-scaling models.
- No Hyperparameter Search: TabICL operates with fixed pretraining and does not require dataset-specific tuning, yielding near plug-and-play utility for practitioners, with large time and cost reductions compared to existing hyperparameter-heavy methods.
- Hierarchical Classification: The recursive reduction of multiclass tasks to a hierarchy of subproblems enables inference for extremely high-class-count scenarios without loss in efficiency.
Limitations and Future Directions
- Classification-only Scope: Extension to regression and mixed outcome settings is necessary for full generality. Structural adaptations, inspired by findings in TabPFNv2, are likely feasible.
- ICL-vs-In-weights Learning Tradeoff: The interplay between pretraining context (ICL) and model parametric adaptation (fine-tuning or in-weights learning) for extremely large datasets or non-i.i.d. shifts remains to be fully mapped.
- Support for Multimodal Extension: Integration with text or images in tabular data is outside scope here but may theoretically benefit from similar row-then-column decoupling strategies and hierarchical context aggregation.
Further research should explore scaling beyond the 500K sample regime, combined modalities, and the potential for on-the-fly or retrieval-augmented hybrid ICL/fine-tuning to handle highly dynamic environments or distribution shifts.
Conclusion
TabICL (2502.05564) substantially extends the scalability and robustness of in-context learning approaches for tabular data, outperforming prior ICL models and traditional ML baselines in both predictive performance and computational efficiency. The combination of permutation-invariant set-based embeddings, hierarchical attention, and synthetic pretraining represents a strong path forward for tabular foundation models. The demonstrated ability to handle arbitrary dataset sizes and structure, with consistent calibration and without dataset-specific tuning, positions TabICL as a state-of-the-art solution for real-world large-data tabular classification tasks. This work establishes key architectural and training principles for the next generation of tabular foundation models, with broad implications for practical ML deployment and the design of transferable, scalable statistical learners.