- The paper introduces TabDPT, a transformer-based model that uses in-context learning and self-supervised strategies to advance tabular data processing.
- It achieves state-of-the-art results on CC18 and CTR23 benchmarks, significantly improving classification and regression performance over traditional methods.
- Its innovative architecture, which tokenizes entire rows and employs retrieval-based inference, offers scalable and efficient handling of heterogeneous tabular data.
TabDPT: Scaling Tabular Foundation Models on Real Data
The research presented in "TabDPT: Scaling Tabular Foundation Models on Real Data" (2410.18164) addresses the persistent challenge of applying neural networks to tabular data, a domain traditionally dominated by tree-based models like XGBoost and CatBoost. The paper introduces Tabular Discriminative Pre-trained Transformer (TabDPT), advancing the effectiveness and scalability of tabular foundation models (TFMs) using in-context learning (ICL) trained on real datasets, coupled with innovative self-supervised learning (SSL) strategies.
Methodology and Model Architecture
TabDPT is a transformer-based tabular model utilizing ICL, which enables the model to generalize across datasets without additional fine-tuning, a significant leap over traditional methods. The model architecture borrows core elements from TabPFN but diverges by employing real dataset training in a self-supervised manner. Central to this approach is the use of entire rows as attention tokens, significantly optimizing memory utilization compared to cell-based tokenization in LLM approaches.
The training process employs SSL by predicting randomly selected columns from the rest of the dataset, independent of external labels. This strategy bolsters the learning of feature interdependencies, crucial for handling heterogeneous tabular structures. Additionally, retrieval-based training enhances scalability by utilizing context local to each query point, reducing computational overhead during inference.
Experimental Results
TabDPT demonstrates superior performance on the CC18 and CTR23 benchmark datasets, achieving state-of-the-art results in classification and regression tasks. It outperforms existing TFMs and tree-based models, evidenced by significant AUC and accuracy improvements (Table 1) and competitive Elo ratings (Figure 1).
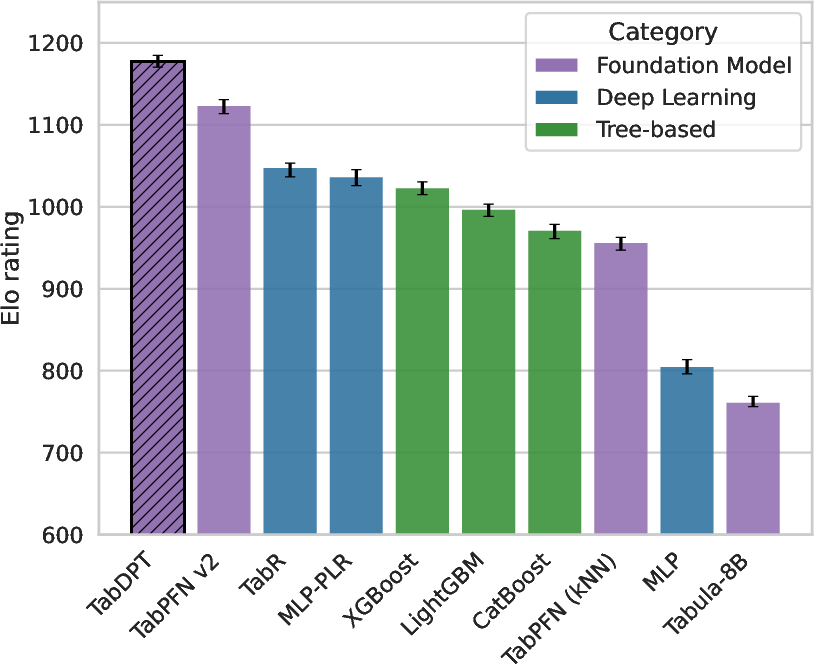
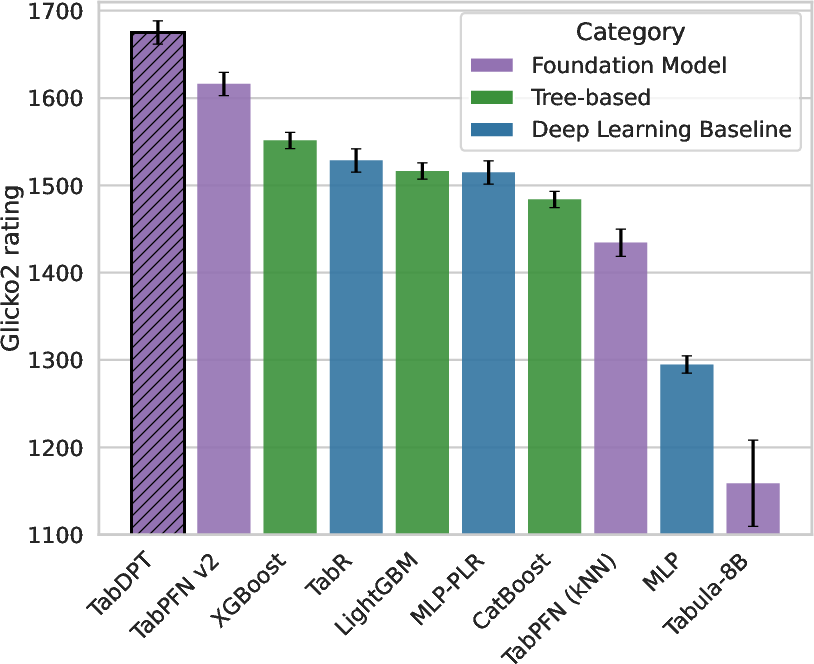
Figure 1: Elo scores (Accuracy, R2) with error bars.
TabDPT's design choices, such as retrieval-based inference and SSL, contribute significantly to its robust performance. The study underscores the model's scalability, with empirical results confirming predictable improvements as model and dataset sizes increase (Figure 2).
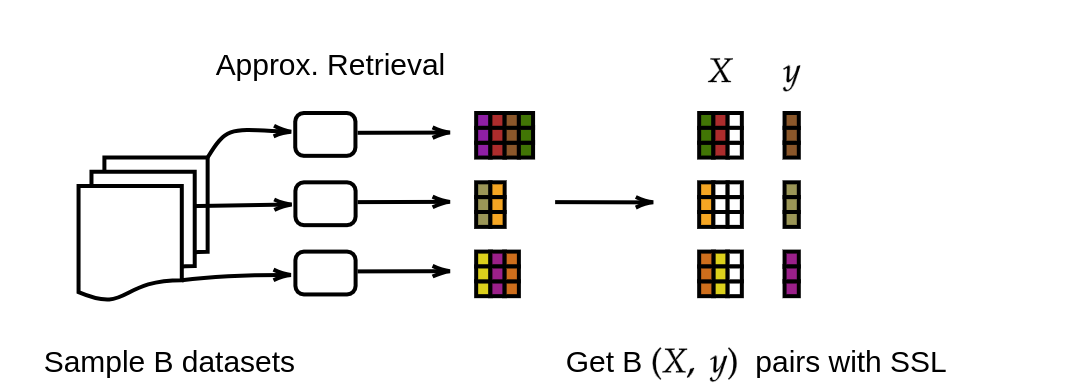
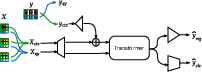
Figure 2: Selecting a training batch.
Considerations and Implications
Despite its achievements, TabDPT does not currently handle textual information within tables, indicating an area for future development. The assumption of i.i.d. data without hierarchical or temporal aspects is another limitation. Nonetheless, the demonstrated scaling laws align with those observed in other domains, affirming the potential for larger tabular models leveraging extensive datasets.
The implications of this research are profound for AI applications reliant on tabular data. TabDPT's approach can revolutionize industries that depend on quick adaptation to new data without extensive re-training, such as finance, healthcare, and logistics. The release of code and model weights will facilitate further advancements and practical applications.
Conclusion
"TabDPT: Scaling Tabular Foundation Models on Real Data" (2410.18164) presents a significant step forward in developing scalable and efficient models for tabular data. By leveraging in-context learning and a novel training regimen grounded in real data, TabDPT offers a compelling alternative to traditional tabular learning methods. As the field progresses, investing in larger models with diverse datasets will be instrumental in realizing the full potential of foundation models in tabular domains.